随着大语言模型(LLMs)在高权限场景中的广泛应用,AI智能体的安全问题日益凸显。这些智能体能够读取邮件、生成代码、调用API,甚至执行复杂的任务链。然而,一旦被恶意利用,可能导致严重的安全隐患。为了应对这一挑战,Meta AI公司最新推出了LlamaFirewall,一款专为生产环境中的AI智能体设计的系统级安全解决方案。
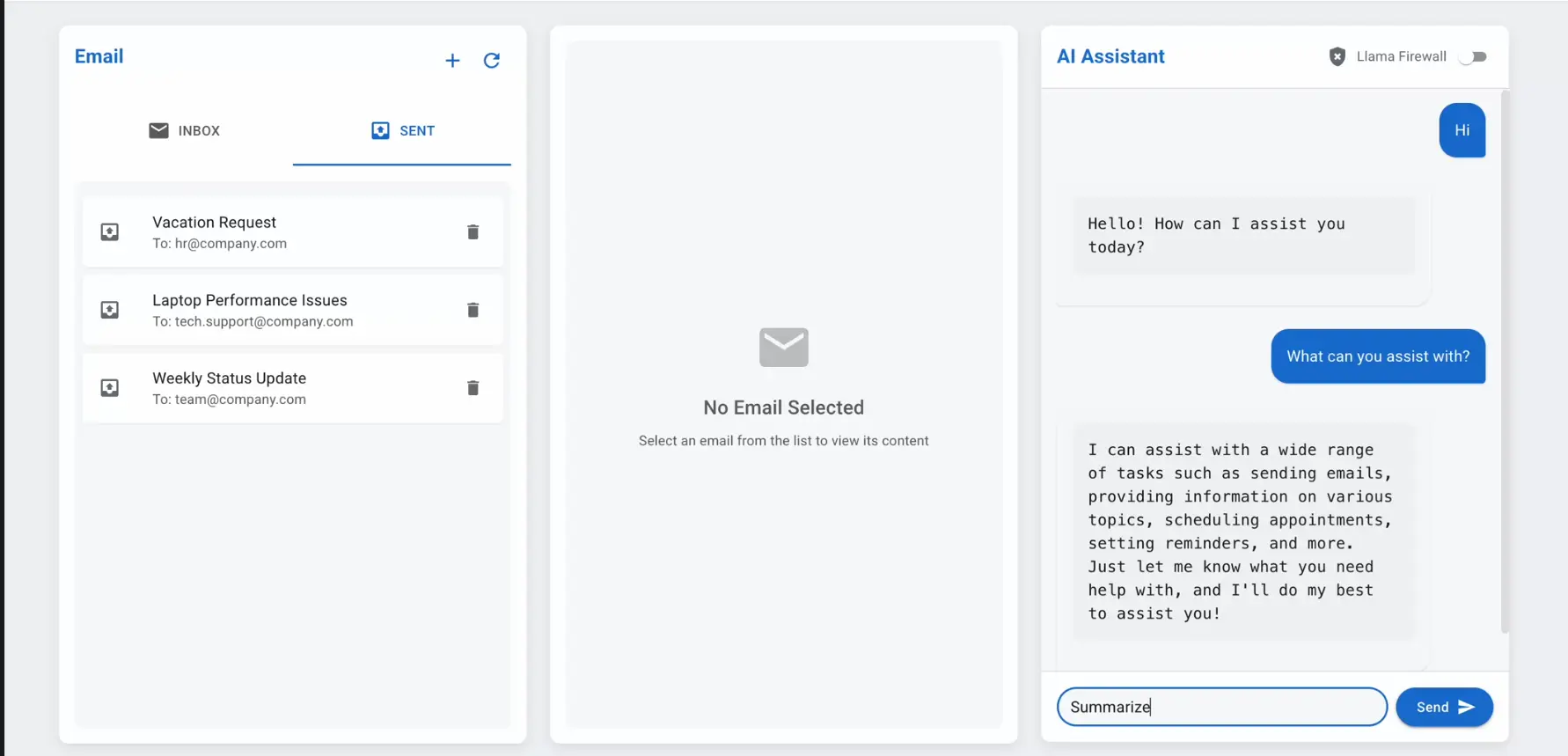
AI智能体面临的核心安全威胁
传统的安全机制,例如聊天机器人内容审核或硬编码模型限制,已无法满足现代AI智能体的需求。Meta针对三大核心安全挑战开发了LlamaFirewall:
- 提示注入攻击:攻击者通过精心设计的输入绕过模型限制,诱导智能体执行恶意行为。
- 智能体行为与用户目标不一致:智能体可能因误解或间接提示而偏离用户的初衷。
- 不安全的代码生成:生成的代码中可能包含漏洞,例如SQL注入等,危及系统安全。
LlamaFirewall:分层防护架构
LlamaFirewall采用分层框架,包含三个专门的防护模块,每个模块专注于解决特定的安全威胁:
1. PromptGuard 2
PromptGuard 2 是一个基于BERT架构的分类器,用于实时检测越狱行为和提示注入攻击。它支持多语言输入,并提供两种版本:
- 86M参数模型:性能强劲,适合对安全性要求更高的场景。
- 22M轻量版本:低延迟部署,适用于需要快速响应的环境。
在Meta的AgentDojo基准测试中,PromptGuard 2(86M)将提示注入攻击的成功率(ASR)从17.6%降至7.5%,同时任务实用性损失极小。
2. AlignmentCheck
AlignmentCheck 是一种实验性审计工具,通过分析智能体内部的推理轨迹,确保其行为与用户目标保持一致。它特别擅长检测间接提示注入,进一步降低了攻击成功率。
结合PromptGuard 2,AlignmentCheck将ASR从7.5%进一步降低至2.9%,显著提升了系统的安全性。
3. CodeShield
CodeShield 是一个静态分析引擎,专门用于检查LLM生成代码中的不安全模式。它支持多种编程语言,能够在代码提交或执行前捕获常见漏洞,例如SQL注入、路径遍历等。
测试结果显示,CodeShield在不安全代码数据集上的表现优异,精准度高达96%,召回率达到79%,且响应时间适合生产环境的实时使用。
测试结果与性能评估
Meta在AgentDojo基准测试中模拟了97个任务领域的提示注入攻击,以全面评估LlamaFirewall的性能。测试结果如下:
- 整体系统表现:将攻击成功率(ASR)从17.6%大幅降低至1.75%,降幅达90%。
- 任务实用性:尽管增加了安全防护,任务实用性仅略降至42.7%,表明LlamaFirewall在安全性与功能性之间实现了良好平衡。
LlamaFirewall的意义与未来展望
LlamaFirewall的推出标志着AI智能体安全领域的一次重大进步。它不仅解决了当前最紧迫的安全威胁,还为未来的AI应用提供了更强大的保障。以下是LlamaFirewall的关键意义:
- 系统级保护:通过分层架构覆盖多个安全维度,为AI智能体提供全方位防护。
- 高性能与灵活性:不同版本的模块适应多样化的部署需求,兼顾安全性与效率。
- 推动行业标准:为AI安全领域树立了新的标杆,可能引领更多企业开发类似解决方案。
未来,Meta计划进一步优化LlamaFirewall的功能,例如增强对复杂任务链的支持,以及扩展对新兴编程语言和威胁类型的覆盖范围。此外,LlamaFirewall的成功也为AI安全研究提供了宝贵的实践经验,有助于推动整个行业的技术进步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











