
华盛顿大学、谷歌 DeepMind和加州大学伯克利分校的研究人员推出一种用于生成视频序列的方法Generative Inbetweening,能够在两个关键帧之间产生连贯的运动。简单来说,就是给定视频的起始和结束画面,这项技术能够自动生成中间的过渡画面,使得整个视频看起来流畅自然。
- 项目主页:https://svd-keyframe-interpolation.github.io
- GitHub:https://github.com/jeanne-wang/svd_keyframe_interpolation
- Demo:https://huggingface.co/spaces/fffiloni/svd_keyframe_interpolation
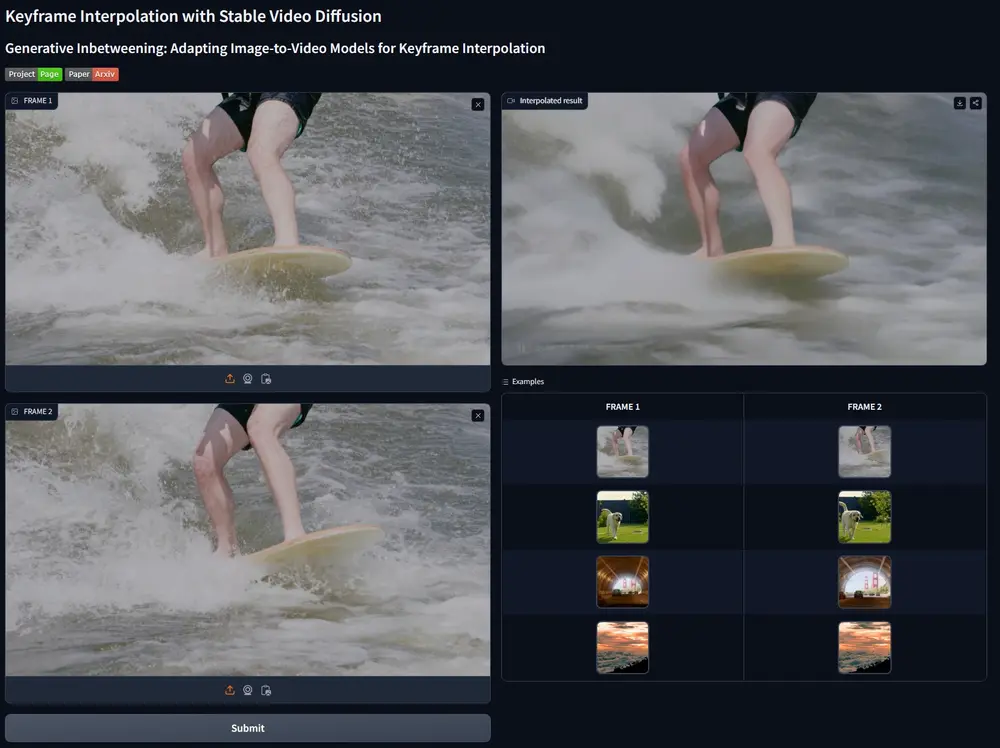
研究团队对一个预训练的大规模图像到视频扩散模型进行了调整(该模型最初被训练用于从单个输入图像生成随时间向前移动的视频),使其适用于关键帧插值,即在两个输入帧之间产生视频。研究团队通过一种轻量级的微调技术实现了这种调整,该技术产生了一个修改后的模型版本,该版本可以预测从单个输入图像开始向后移动的视频。随后,这个模型(加上原始的向前移动的模型)被用于一个双向扩散采样过程中,该过程结合了从两个关键帧开始的重叠模型估计。
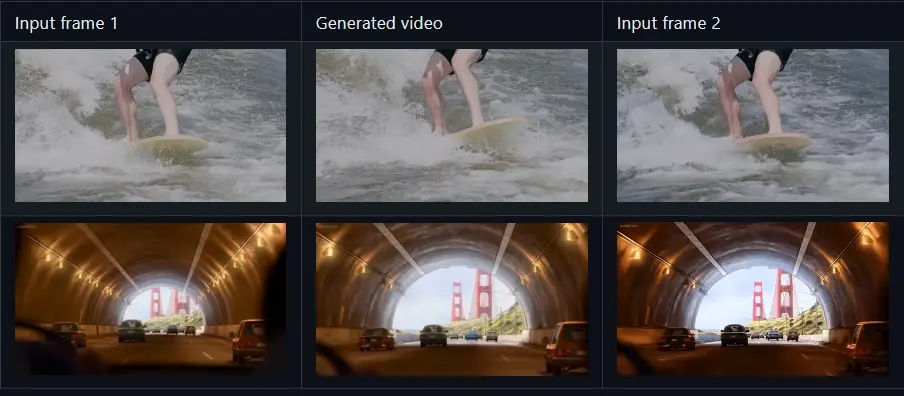
主要功能和特点:
- 关键帧插值:在两个给定的画面之间生成过渡画面,创造出平滑的动态效果。
- 预训练模型的适应性:通过对预训练的大型图像到视频扩散模型进行微调,使其能够反向生成视频,即从结束画面向起始画面生成动画。
- 轻量级微调技术:与从头开始训练一个专门的模型相比,这种方法需要的数据和计算资源更少。
工作原理:
- 正向与反向运动预测:首先使用原始的图像到视频模型生成从起始画面开始的正向运动视频,然后通过微调技术生成从结束画面开始的反向运动视频。
- 时间自注意力机制:利用时间自注意力层来建模生成视频中的运动,通过180度旋转时间自注意力图来实现运动时间的反向关联。
- 双方向扩散采样:结合正向和反向运动预测,通过共享的时间自注意力图来同步两个采样路径,确保它们生成完全相反的运动,从而实现“前后运动一致性”。

具体应用场景:
- 视频编辑:在视频制作中,可以用来生成平滑的过渡效果,尤其是在需要在两个关键动作或场景之间创建流畅动画时。
- 动态效果增强:为静态图片添加动态效果,例如将一张图片中的物体或人物制作成看起来在移动的样子。
- 虚拟现实和游戏:在虚拟现实或游戏中生成更加真实和连贯的动画效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











