华东师范大学和阿里巴巴的研究人员推出新型视频合成模型扩展方法ExVideo,这种方法旨在通过参数高效的方式对现有的视频合成模型(Stable Video Diffusion)进行后期调整(post-tuning),以提升模型生成视频的长度和质量。ExVideo目前局限性,例如在生成高质量人物肖像方面存在困难,以及对基础模型的依赖。未来的工作将致力于在更大的数据集上训练模型,以进一步提高性能。
- 项目主页:https://ecnu-cilab.github.io/ExVideoProjectPage
- GitHub:https://github.com/modelscope/DiffSynth-Studio
- 模型地址:https://huggingface.co/ECNU-CILab/ExVideo-SVD-128f-v1
- Demo:https://huggingface.co/spaces/modelscope/ExVideo-SVD-128f-v1
开发团队目前已经释出了SVD扩展模型,成功实现了长达 128 帧视频的生成能力。该模型基于约 4 万个视频样本,利用 8 块 A100 高性能GPU进行了为期一周的训练。这可能导致模型在某些情况下生成的内容与现实逻辑不尽相符,后续会有更加优化的模型版本发布。
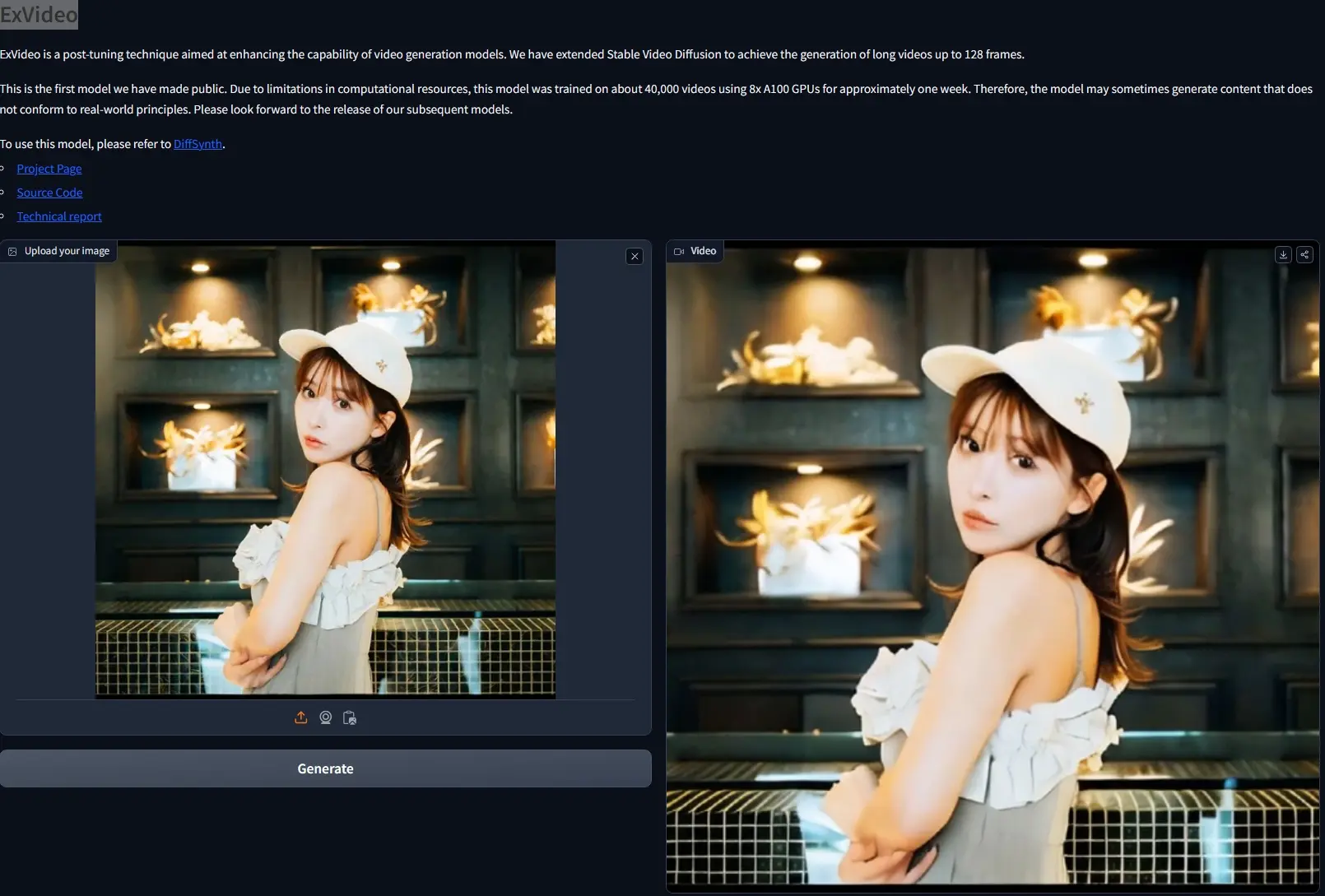
ExVideo旨在提升现役视频合成模型的功能,使其在减少额外训练成本的同时,能够生成更长时间的视频序列。开发团队特别为普遍采用的时序模型架构定制了扩展策略,涵盖了3D卷积、时间注意力机制及位置嵌入等领域。为验证ExVideo方法的有效性,开发者选取了Stable Video Diffusion模型实施延展训练。通过应用本方法,该模型生成视频帧的能力提升了至多5倍,且仅需利用含有4万个视频的数据集进行1,500小时的GPU训练。重要的是,视频时长的显著增加并未牺牲模型的固有泛化性能,其在生成风格多样、分辨率不一的视频方面依然表现出色。

主要功能和特点:
- 扩展视频长度:ExVideo能够显著增加视频合成模型生成的视频长度,最多可达原始帧数的5倍。
- 参数高效:该方法在扩展视频长度的同时,保持了较低的训练成本,仅需要1.5k GPU小时来训练。
- 保持原有能力:尽管视频长度增加,但ExVideo不会影响模型的泛化能力,即模型仍然能够生成多样化风格和分辨率的视频。
工作原理:
- 3D卷积:ExVideo保留3D卷积层,以适应不同尺度的视频。
- 时间注意力:对时间注意力模块进行微调,以提高模型处理更长视频序列的能力。
- 位置嵌入:使用可训练的位置嵌入替换原有的静态位置嵌入,以适应更长的视频序列。
- 后期调整策略:通过后期调整,增强模型在时间模块上的能力,使其能够处理更长时间的内容。
具体应用场景:
- 文本到视频合成:ExVideo可以与文本到图像模型结合,将文本描述转换为视频。
- 多样化风格和分辨率:ExVideo能够生成具有不同风格(如现实风格、像素艺术风格、平面动画风格)和分辨率的视频。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











