
浙江大学、北京大学和阿里巴巴的研究人员推出新型知识蒸馏方法DisBack,它用于加速一类称为扩散模型(diffusion models)的生成模型的采样速度。扩散模型是当前非常热门的生成模型,能够生成高质量和多样化的图像、音频和视频,但它们通常面临生成速度慢的问题。例如,我们想要生成一幅具有特定风格的图像,使用传统的扩散模型可能需要很长时间来逐步迭代生成图像。而DisBack通过学习教师模型的收敛过程,能够更快地引导学生生成器产生高质量的图像,大大减少了生成时间。
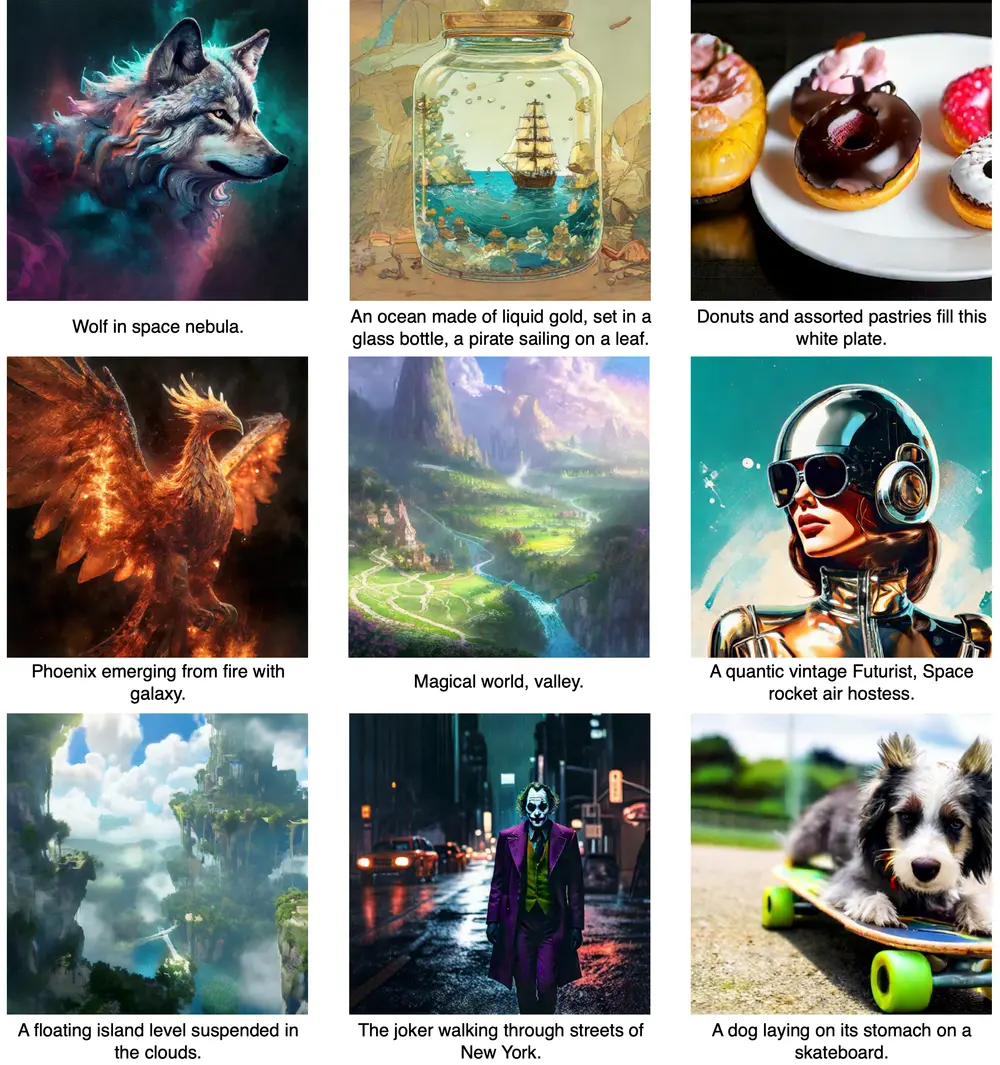
主要功能:
- 加速采样:DisBack旨在加快扩散模型的采样过程,使其能够更快地生成数据。
主要特点:
- 分布回溯:DisBack通过记录教师模型到学生生成器的退化路径,并将其逆转,作为教师模型的收敛轨迹来指导学生模型的训练。
- 两阶段过程:DisBack包括退化记录和分布回溯两个阶段,先记录教师模型的收敛轨迹,然后训练学生生成器去逼近这个轨迹。
工作原理:
- 退化记录:首先,从训练有素的教师模型开始,逐渐调整其参数,使其适应未经训练的学生生成器的初始分布,记录下这个“退化”过程中的一系列中间模型。
- 分布回溯:然后,将这个退化路径逆转,作为教师模型的收敛轨迹。接着,训练学生生成器去逆向逼近这些中间分布,从而学习教师模型的收敛行为。
具体应用场景:
- 图像生成:在图像生成任务中,DisBack可以用来加速生成高质量图像的过程。
- 文本到图像:在文本到图像的生成任务中,根据文本描述快速生成相应图像。
- 视频和音频生成:虽然论文中没有特别提到,但DisBack的方法同样可以应用于视频帧或音频样本的快速生成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











