当我们看到大模型在各种任务上不断刷新性能纪录时,一个隐含的信念常常浮现:性能提升 = 内部表示更优。这种观点被称为“表示乐观主义”(Representational Optimism)——即认为随着模型变得更强大,其内部对世界的结构化理解也在同步进化。
但这一假设真的成立吗?
麻省理工学院、不列颠哥伦比亚大学、牛津大学、矢量研究所与 Lila Sciences 的研究人员在论文《Questioning Representational Optimism in Deep Learning: The Fractured Entangled Representation Hypothesis》中提出了一项挑战性发现:即使两个神经网络输出完全一致,它们的内部表示可能天差地别。
更重要的是,传统训练方法(如随机梯度下降,SGD)生成的网络,其内部表示往往是破碎且纠缠的;而通过开放性搜索演化出的网络,则更接近一种统一、可分解的结构。
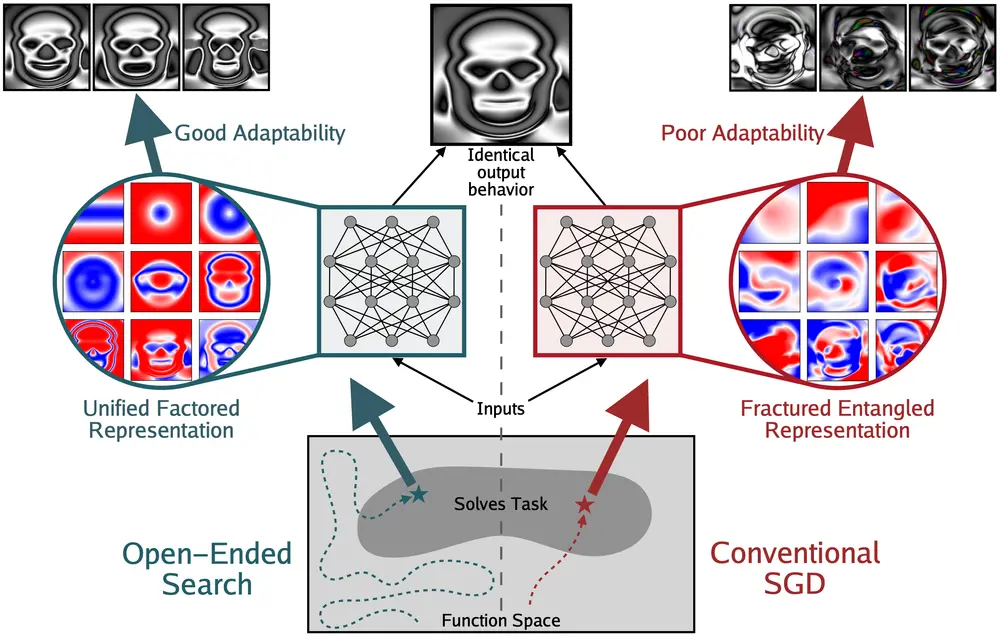
这一结果暗示:我们可能正在用更高的性能,掩盖一个更深层的问题——模型“怎么想”的质量并未同步提升。
一个极简实验:生成一张图像
为了深入观察神经网络的“思维过程”,研究团队选择了一个极简任务:让神经网络生成一张固定图像(例如骷髅头),输入是坐标 (x, y),输出是该位置的像素值。
这看似简单,却具备独特优势:
- 网络的每一层、每一个神经元都可以被完整可视化为一张图像;
- 可以逐层追踪信息如何从输入构建为最终输出;
- 能够清晰比较不同训练方式下,功能相同但路径不同的内部机制。
他们对比了两种训练范式:
- SGD 训练网络:使用标准反向传播优化损失函数,直接拟合目标图像;
- 进化网络:基于 Picbreeder 实验框架,通过人类引导的进化搜索(Interactive Evolutionary Computation)逐步生成图像。
两者最终都能完美生成目标图像,输出行为完全一致。但内部发生了什么?
截然不同的“思维方式”
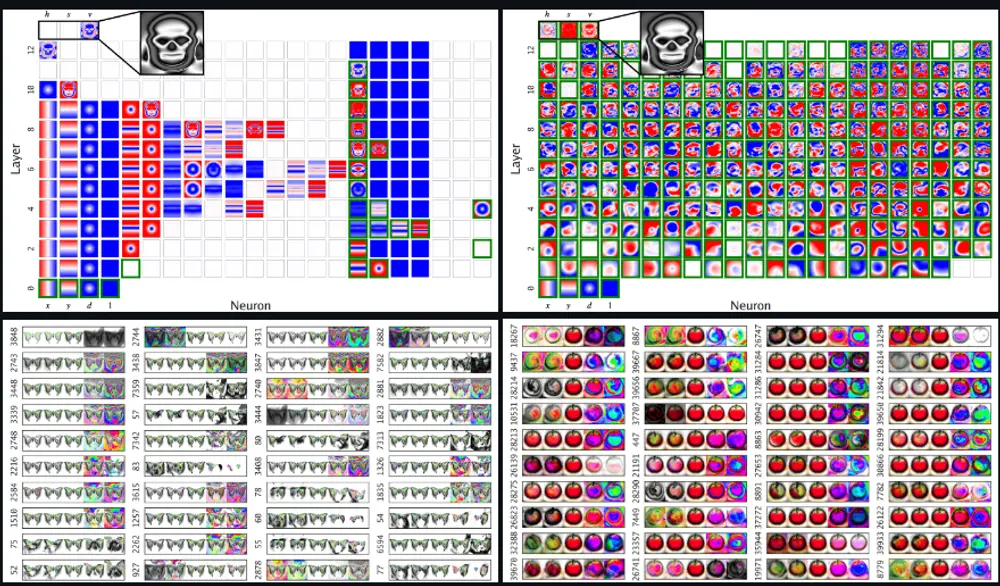
1. SGD 网络:碎片化纠缠表示(FER)
SGD 训练出的网络虽然能输出正确结果,但其内部结构呈现出高度混乱的状态:
- 单个神经元的激活模式杂乱无章,缺乏语义意义;
- 多个神经元共同编码同一特征,且彼此高度耦合;
- 特征分布零散,无法清晰分离形状、对称性、边缘等基本结构。
研究者将这种现象称为 Fractured Entangled Representation(FER) ——即“碎片化纠缠表示”。
就像一群人用不同语言同时喊出同一句话,最终声音汇成正确结果,但没人真正理解这句话是怎么组成的。
这种表示方式虽然能“完成任务”,但缺乏结构性和可解释性。
2. 进化网络:统一分解表示(UFR)
相比之下,通过开放性搜索演化出的网络展现出截然不同的组织方式:
- 神经元具有清晰的功能分工:有的负责对称性,有的生成圆形轮廓,有的控制局部细节;
- 高层特征由低层基础模式组合而成,呈现层级化结构;
- 表示接近 Unified Factored Representation(UFR) ——即统一且可分解的表示。
类似于建筑师从地基、墙体到屋顶逐步建造房屋,每一步都有明确意图和结构支撑。
尽管任务只是生成一张图,进化过程自发地发现了图像的内在规律(如对称性、重复结构),并将其编码为可复用的模块。
为什么表示方式如此重要?
关键在于:输出正确 ≠ 能力强大。真正的智能不仅在于“做对一件事”,更在于能否泛化、创造和持续学习。
研究进一步分析了 FER 与 UFR 在以下方面的影响:
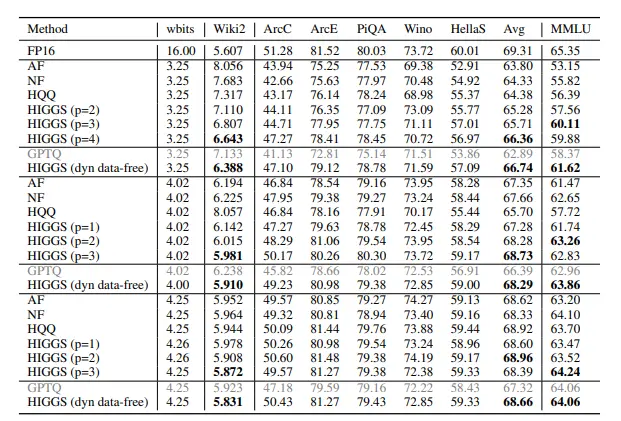
| 能力 | FER(SGD) | UFR(进化) |
|---|---|---|
| 泛化能力 | 在数据稀疏区域表现差,难以 extrapolate | 能利用基础规律推断未知区域 |
| 创造力 | 修改局部常导致整体崩溃,难以生成新结构 | 可组合已有模块创造新图像 |
| 持续学习 | 新知识易与旧表示冲突,出现灾难性遗忘 | 模块化结构支持增量学习 |
换句话说,FER 可能让模型成为“高分低能”的应试者,而 UFR 更接近真正理解任务的思考者。
问题根源:训练目标 vs. 表示质量
为什么 SGD 容易产生 FER?
根本原因在于:SGD 只关心最小化损失函数,不关心表示的结构质量。
- 它寻找的是“任何能拟合数据的参数配置”,而不区分是否具有语义结构;
- 在高维空间中,存在大量等效解(即输出相同但内部不同),SGD 倾向于收敛到其中最易到达的解,而非最优表示;
- 相比之下,进化搜索通过长期探索和选择压力,更可能发现结构清晰、可组合的解决方案。
这提示我们:当前主流训练范式可能存在表示层面的“路径依赖”问题——性能提升只是表象,内部结构并未同步进化。
对未来研究的启示
这项工作并非否定 SGD 的有效性,而是提醒我们:
不能仅凭输出性能判断模型的“理解”程度。
它为深度学习提出了几个关键方向:
- 表示质量应成为独立评估维度
未来模型评估不应只看准确率、BLEU 或 FID,还应考察其内部表示是否结构化、可解释、可组合。 - 探索非梯度优化路径的价值
进化算法、强化学习、自组织机制等非传统方法,可能在表示学习上具有独特优势。 - 设计鼓励结构化的训练目标
引入稀疏性、模块化、因果性等归纳偏置,引导模型学习 UFR 而非 FER。 - 可视化工具的重要性
在更大模型中,虽无法完全可视化每个神经元,但可通过探针、因果干预等手段间接分析表示结构。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...