
上海AI实验室、上海交通大学、香港中文大学和InnoHK的研究人员提出基于结果奖励的强化学习新范式OREAL,通过基于结果奖励的强化学习(RL)提升大语言模型(LLMs)在数学推理任务中的表现。该框架特别关注于如何利用二元结果奖励(即最终答案的正确与否)来优化模型的推理能力,从而解决复杂数学问题。
- GitHub:https://github.com/InternLM/OREAL
- 模型:https://huggingface.co/collections/internlm/oreal-67aaccf5a8192c1ba3cff018
- 数据:https://huggingface.co/datasets/InternLM/OREAL-RL-Prompts
例如,在解决数学问题时,模型需要通过一系列推理步骤(如代数运算、几何推理等)来得出最终答案。传统的强化学习方法在处理这类任务时面临稀疏奖励(只有最终答案正确与否)和长推理链(中间步骤部分正确)的挑战。OREAL框架通过创新的策略解决了这些问题,使得模型能够更好地学习从问题到正确答案的推理路径。
主要功能
- 提升数学推理能力:通过强化学习优化模型在数学问题解决中的表现,特别是在复杂问题的推理链上。
- 利用二元结果奖励:仅依赖于最终答案的正确性(二元奖励)来训练模型,无需额外的中间步骤标注。
- 优化大模型性能:在7B和32B参数规模的模型上实现显著性能提升,甚至超越了更大规模的模型。
主要特点
- 理论支持:通过行为克隆(Behavior Cloning)和奖励重塑(Reward Shaping)等方法,证明了在二元反馈环境中学习最优策略的可行性。
- 稀疏奖励优化:通过token级别的奖励模型,自动估计推理步骤的重要性,解决长推理链中的稀疏奖励问题。
- 可扩展性:适用于不同规模的模型,并在多个基准数据集上验证了其有效性。
工作原理
- 行为克隆与正样本学习:通过Best-of-N(BoN)采样选择正确的推理路径,并使用行为克隆直接学习这些路径。理论分析表明,这种方法可以学习到KL正则化的最优策略。
- 奖励重塑与负样本学习:通过奖励重塑技术,调整负样本的奖励值,以保持正负样本之间的梯度一致性,从而优化失败的推理路径。
- token级别的奖励模型:通过分解推理轨迹的优势,自动估计每个token对最终结果的贡献,从而为关键推理步骤分配更高的权重,优化学习过程。
具体应用场景
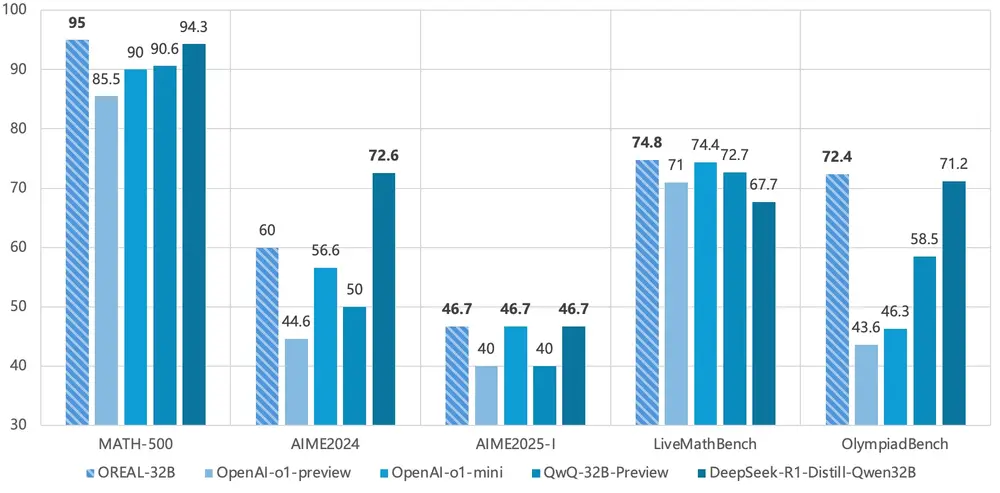
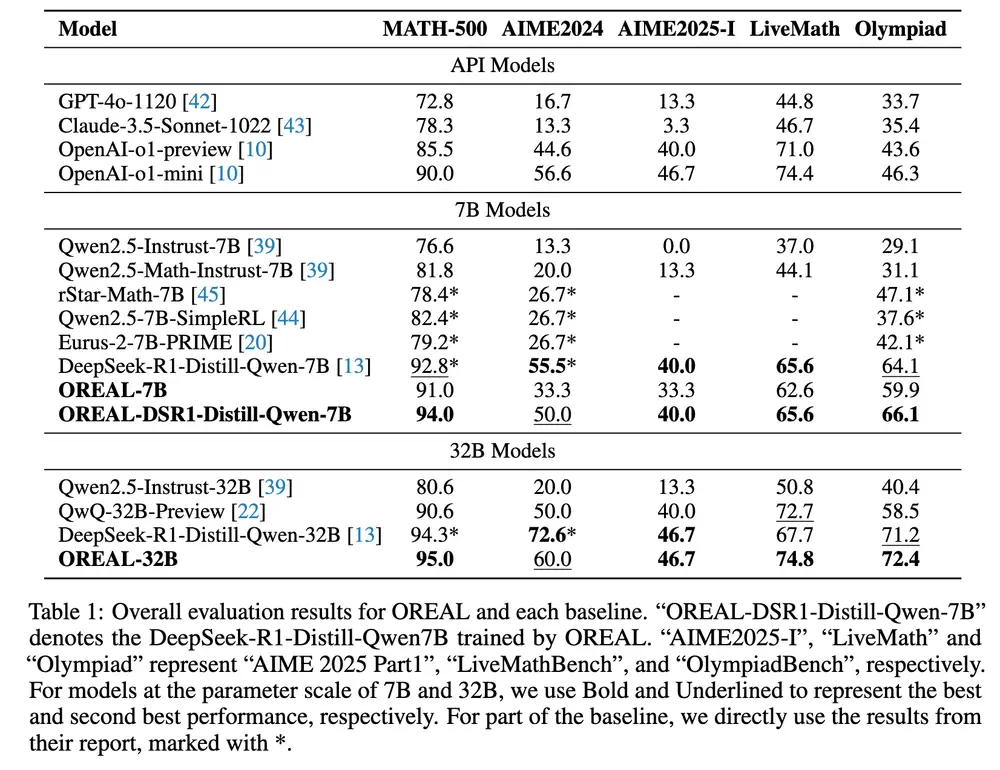
- 数学问题解决:在MATH-500、AIME、LiveMathBench等数学竞赛和基准测试中,OREAL显著提升了模型的准确率。
- 教育领域:帮助学生理解和生成数学问题的推理过程,提供更有效的学习工具。
- 科学研究:为研究复杂问题的推理机制提供了一个强大的模型框架,特别是在需要精确逻辑推理的领域。
- 人工智能开发:为开发更智能的AI系统提供了一种强化学习方法,特别是在只有最终结果反馈的场景中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











