阿里旗下阿里妈妈研究人员推出高保真图像到视频生成框架AtomoVideo,它能够将输入的图像转化为高保真的视频。相较于现有的技术,它提供了更出色的运动强度和一致性,而且完美兼容各种个性化文生图模型,无需繁琐的调整。
AtomoVideo是一个强大的工具,它结合了先进的图像生成技术和视频处理能力,为用户提供了一个从静态图像到动态视频的高效转换途径。

主要功能:
AtomoVideo的核心功能是将静态图像转换成动态视频。它不仅能够保持图像的高保真细节,还能生成具有较高运动强度和一致性的视频。这意味着生成的视频不仅看起来与原图像非常相似,而且动作流畅自然。
主要特点:
- 高保真度: 生成的视频能够精确地反映原始图像的风格和内容。
- 运动强度和一致性: 视频不仅动作丰富,而且动作之间的过渡自然流畅。
- 可扩展性: 该框架可以灵活地扩展到视频帧预测任务,通过迭代生成实现长视频的制作。
- 高度可定制:通过适配器训练的设计,AtomoVideo能够与各种个性化模型和可控模块完美融合,为用户提供更多创作可能性。
工作原理:
AtomoVideo的工作流程包括以下几个关键步骤:
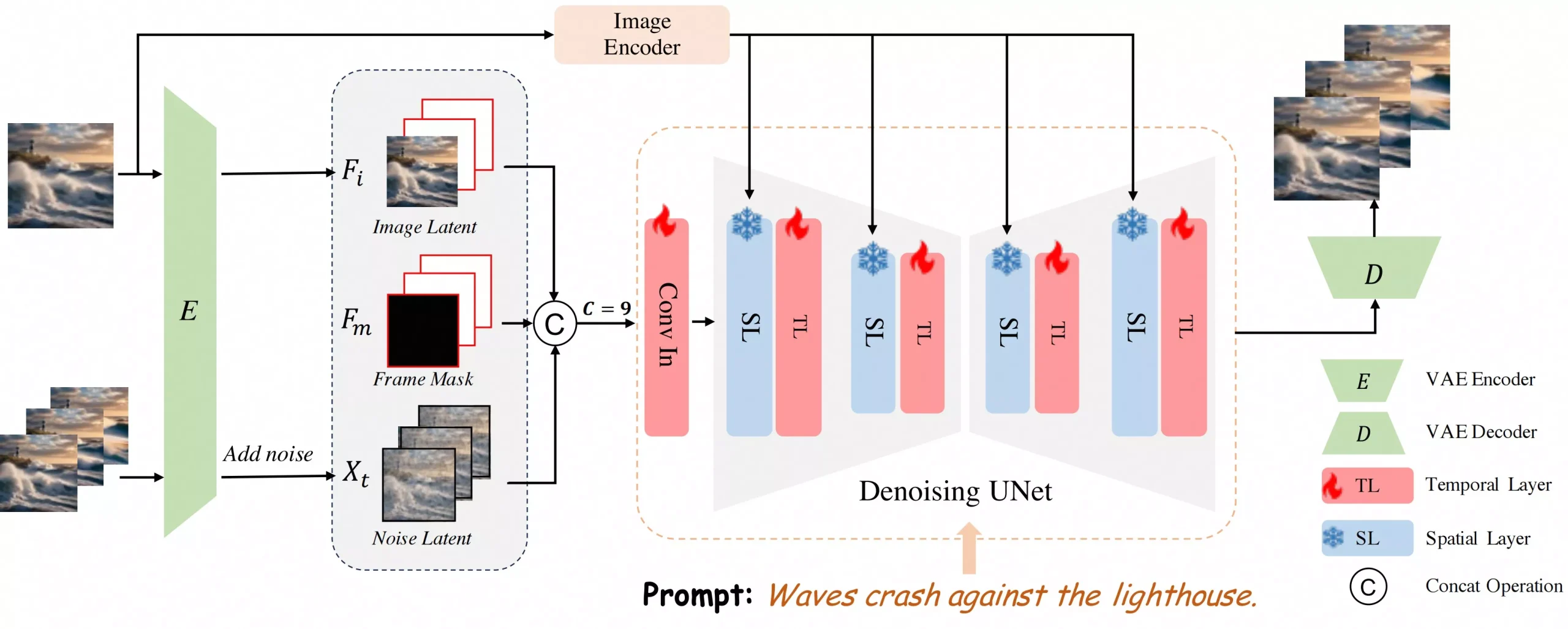
- 图像信息注入: 通过变分自编码器(VAE)将输入图像编码为低级表示,并结合CLIP模型得到的高级语义表示,通过交叉注意力机制注入到模型中。
- 时间层训练: 在训练过程中,只训练添加的时间层和输入层参数,而保持预训练的文本到图像(T2I)模型参数不变。
- 视频帧预测: 通过迭代方式预测后续视频帧,实现长视频的生成。
- 训练和推理: 使用零终端信噪比(SNR)和v-预测策略进行训练,以提高生成视频的稳定性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











