
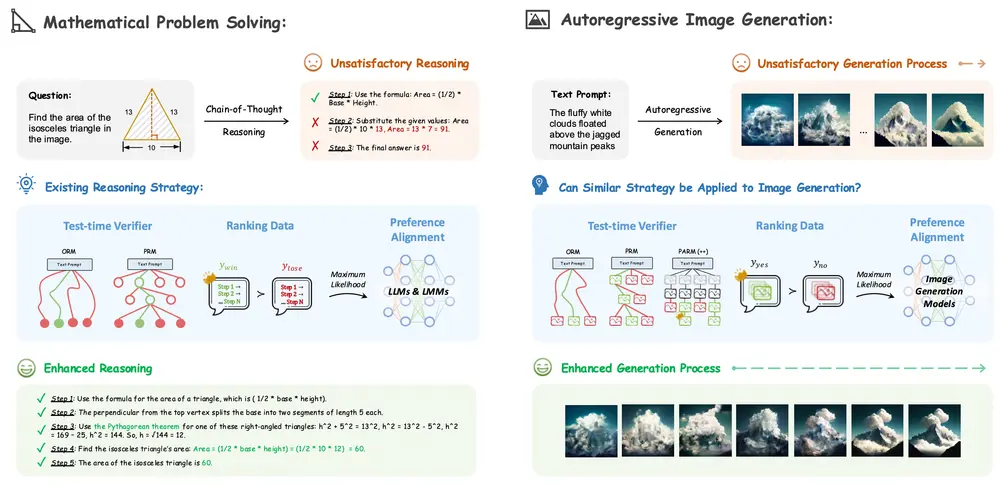
香港中文大学、北京大学和上海人工智能实验室的研究人员探索思维链(Chain-of-Thought, CoT)推理策略在自回归图像生成中的应用潜力。思维链是一种通过逐步分解复杂问题来解决问题的策略,在语言模型和多模态模型中已被证明非常有效。然而,将其应用于图像生成领域仍是一个未被充分探索的问题。论文通过系统性研究,探讨了如何利用CoT推理策略来增强自回归图像生成模型的性能,包括测试时验证(test-time verification)、偏好对齐(preference alignment)以及它们的组合。
- GitHub:https://github.com/ZiyuGuo99/Image-Generation-CoT
- 模型:https://huggingface.co/ZiyuG/Image-Generation-CoT
主要功能
- 图像生成质量提升:通过引入CoT推理策略,显著提升图像生成模型在视觉质量和文本对齐方面的表现。
- 测试时验证(Test-time Verification):利用奖励模型(Reward Models)在生成过程中进行实时验证,选择最优的生成路径。
- 偏好对齐(Preference Alignment):通过直接偏好优化(Direct Preference Optimization, DPO)等技术,调整模型的输出以更好地符合人类偏好。
- 自适应奖励评估:提出了一种新的奖励模型——Potential Assessment Reward Model(PARM),用于自适应地评估生成过程中的每一步。
- 自我修正(Self-correction):进一步引入PARM++,通过反射机制(reflection mechanism)检测生成图像与文本提示之间的不一致性,并进行自我修正。
主要特点
- 系统性研究:首次全面探讨了CoT推理策略在自回归图像生成中的应用,提供了独特的见解。
- 创新的奖励模型:提出了PARM和PARM++,专门针对自回归图像生成设计,能够自适应地进行逐步评估和自我修正。
- 显著的性能提升:通过实验验证,这些策略显著提高了图像生成模型的性能,特别是在复杂属性(如对象数量、颜色、位置等)上的表现。
- 组合策略的有效性:展示了测试时验证和偏好对齐的组合使用可以实现更大的性能提升。
工作原理
1、测试时验证(Test-time Verification):
- Outcome Reward Model (ORM):在生成的最终图像上进行评估,选择最符合文本提示的图像。
- Process Reward Model (PRM):在生成过程中的每一步进行评估,选择最有潜力的路径继续生成。
- Potential Assessment Reward Model (PARM):结合ORM和PRM的优点,自适应地评估每一步的生成质量,选择最有潜力的路径,并在最终步骤中进行全局选择。
2、偏好对齐(Preference Alignment):
- Direct Preference Optimization (DPO):通过训练模型以最大化奖励模型的得分,调整模型的输出以更好地符合人类偏好。
- 迭代DPO:通过多次迭代优化,进一步提升模型的性能。
3、自我修正(Self-correction):
- PARM++:在生成的最终图像上进行反射评估,如果发现图像与文本提示不一致,提供详细的错误描述,并引导模型进行自我修正,直到生成的图像通过评估。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











