
南加州大学、字节跳动公司、斯坦福大学、加州大学洛杉矶分校和加州大学圣地亚哥分校的研究团队推出一种新型的零样本(zero-shot)人像视频动画生成技术X-Dyna,基于扩散模型(diffusion-based)实现。它能够通过驱动视频中的面部表情和身体动作,对单张人像图片进行动画化,并生成具有逼真动态效果的视频。这些动态效果不仅包括人物的动作和表情,还涵盖了周围环境的动态变化(如流动的瀑布、飘动的头发、飘动的衣物等)。X-Dyna 的核心在于通过创新的模块设计和训练策略,解决了以往方法中动态细节丢失的问题,显著提升了动画的真实感和表现力。
- 项目主页:https://x-dyna.github.io/xdyna.github.io
- GitHub:https://github.com/bytedance/X-Dyna
- 模型:https://huggingface.co/Boese0601/X-Dyna
例如,用户上传了一张静态的人像照片,并提供了一段舞蹈视频作为驱动。X-Dyna 能够将舞蹈视频中的动作和表情迁移到人像照片上,生成一个动态的舞蹈视频。同时,生成的视频中人物的头发和衣物会随着动作飘动,背景中的瀑布也会流动,使整个视频看起来生动逼真。

主要功能
- 零样本动画生成:用户只需提供一张人像图片和一段驱动视频,X-Dyna 能够在无需额外训练的情况下,将驱动视频中的动作和表情迁移到人像图片上,生成连贯的动画。
- 动态细节增强:生成的视频不仅包含人物的动作,还能模拟自然环境中的动态效果,如流动的瀑布、飘动的头发、飘动的衣物等。
- 表情和动作控制:通过面部表情和身体姿势的精确控制,生成的动画能够实现高度逼真的表情和动作迁移。
- 实时渲染:支持高效的实时渲染,适用于多种应用场景。
技术亮点
动态适配器(Dynamics-Adapter)
X-Dyna的核心在于其独特的动态适配器设计,这是一种轻量级模块,旨在将参考外观上下文有效地整合进扩散模型骨干的空间注意力中,同时保留运动模块合成流畅而复杂的动态细节的能力。这一机制确保了即使在高度动态的场景中也能保持精细的动作表现。
局部控制模块
为了实现更加精确的表情迁移,X-Dyna还包含了一个专门用于捕捉与身份解耦的面部表情的局部控制模块。这使得该系统能够在动画场景中精准地再现面部表情,进一步增强真实感。
架构概览
- 预训练的扩散UNet骨干网络:作为基础,用于可控的人体图像动画生成。
- 动态适配器:将参考图像上下文作为可训练的残差无缝集成到空间注意力中,与去噪过程并行进行,同时保留原有的空间和时间注意力机制。
- 局部面部控制模块:从跨身份的面部图像块中隐式学习面部表情控制,以实现精确的表情迁移。
这些组件共同作用,形成了一个统一的框架,可以从多样化的人体运动和自然场景视频数据集中学习,进而生成高度逼真且富有表现力的动画。
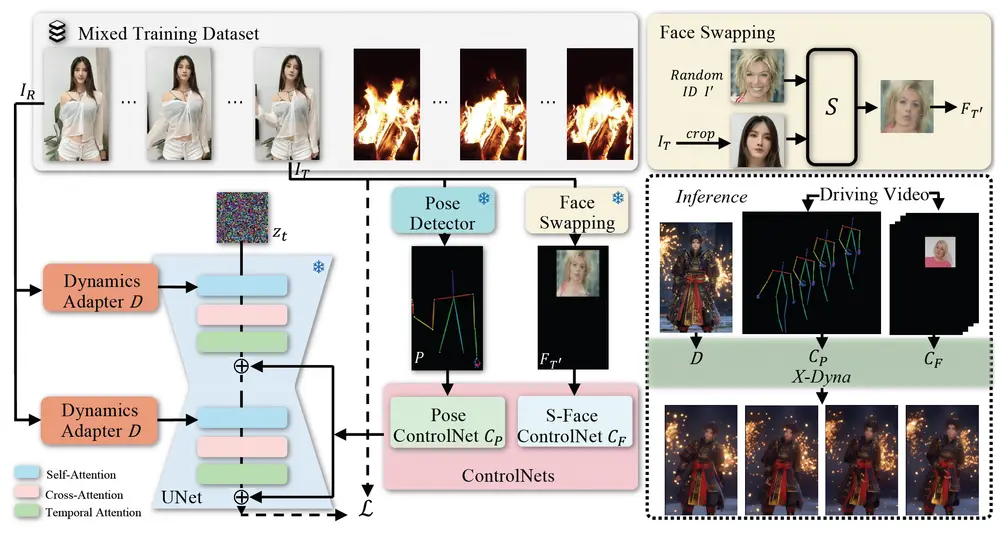
定性和定量评估
全面的实验表明,X-Dyna在多项指标上超越了现有的最先进方法,特别是在动态细节的表现和运动的真实感方面。这种技术的进步为未来的人体动画制作提供了新的可能性,无论是在影视制作、游戏开发还是虚拟现实等领域都有着广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











