
阿里巴巴通义实验室的研究人员推出一种基于扩散模型的视频修复方法DiffuEraser,能够生成更详细、更连贯的结构,并通过引入先验信息和优化时间一致性来提升性能。比如,在一段视频中,如果某个物体被意外遮挡形成掩码区域,视频修复技术需要利用周围信息填充该区域,让视频看起来自然流畅。当前主流算法结合基于流的像素传播和基于 Transformer 的生成方法,但处理大掩码时存在模糊和时间不一致的问题。DiffuEraser 基于稳定扩散模型,致力于克服这些问题,生成更详细、结构更连贯的修复内容。
- 项目主页:https://lixiaowen-xw.github.io/DiffuEraser-page
- GitHub:https://github.com/lixiaowen-xw/DiffuEraser
- 模型:https://huggingface.co/lixiaowen/diffuEraser
主要功能
- 高细节和连贯性修复:DiffuEraser能够生成更详细、更精细的纹理,相比基于Transformer的方法(如Propainter),在修复大面积遮挡时表现出更少的模糊和时间不一致性。
- 时间一致性优化:通过扩展先验模型和DiffuEraser的时间感受野(temporal receptive fields),以及利用视频扩散模型(Video Diffusion Models, VDM)的时间平滑特性,DiffuEraser显著提升了长序列推理中的时间一致性。
- 先验信息注入:通过引入先验信息,DiffuEraser能够更稳定地初始化修复过程,减少噪声伪影和幻觉(hallucinations),从而生成更准确和真实的修复结果。
主要特点
- 基于扩散模型的视频修复:DiffuEraser利用扩散模型的强大生成能力,克服了Transformer模型在生成大面积遮挡区域时的模糊和马赛克问题。
- 先验信息的利用:通过引入先验信息,DiffuEraser能够更稳定地初始化修复过程,减少噪声伪影和幻觉,从而生成更准确和真实的修复结果。
- 时间一致性增强:通过扩展时间感受野和利用VDM的时间平滑特性,DiffuEraser显著提升了长序列推理中的时间一致性。
- 高效的推理:利用分阶段一致性模型(Phased Consistency Models, PCM),DiffuEraser能够在仅两步中生成样本,显著提高了推理效率。
工作原理
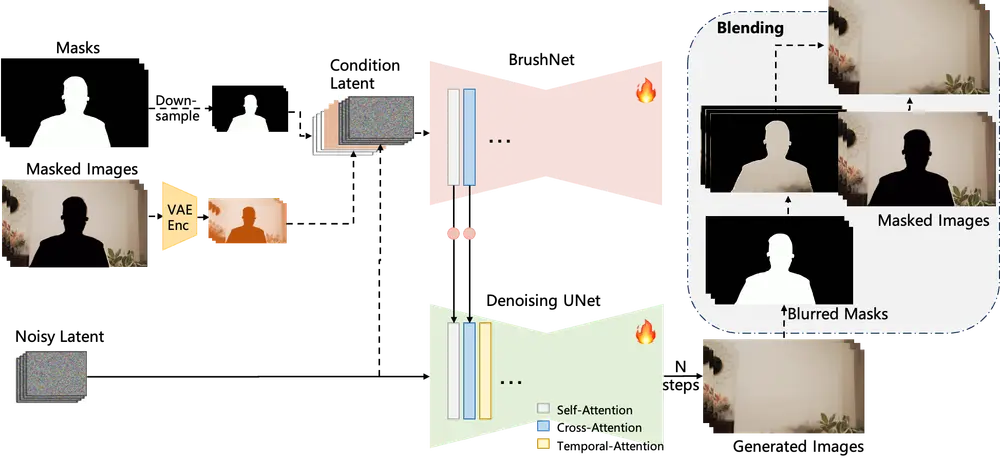
- 网络架构:由主去噪 UNet 和辅助 BrushNet 组成。BrushNet 从掩码图像中提取特征,经零卷积块后逐层融入去噪 UNet。去噪 UNet 处理噪声潜变量,在自注意力和交叉注意力层后引入时间注意力机制增强时间一致性,最后生成的图像与输入掩码图像用模糊掩码融合。
- 已知像素传播:运动模块支持时间传播,同时利用先验模型(如 Propainter)的输出进行 DDIM 反演并融入噪声潜变量,实现已知像素的传播和更好的初始化。
- 未知像素生成:稳定扩散模型发挥强大的生成能力,为未知像素生成内容。
- 时间一致性优化:利用视频扩散模型的时间平滑特性,采用交错去噪方法;同时扩展先验模型和 DiffuEraser 的时间感受野,通过预推理采样处理视频帧,引导逐帧推理,确保时间一致性。
具体应用场景
- 视频内容修复:去除视频中不需要的物体或修复因遮挡、损坏等造成的缺失区域,使视频内容完整。例如,去除视频中突然闯入的路人,修复老旧视频中的划痕和斑点。
- 视频编辑创作:在视频编辑过程中,对特定区域进行修改或添加内容时,DiffuEraser 可保证修改后的视频在时间上连贯自然。如在电影特效制作中,对虚拟场景的局部进行调整和优化。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











