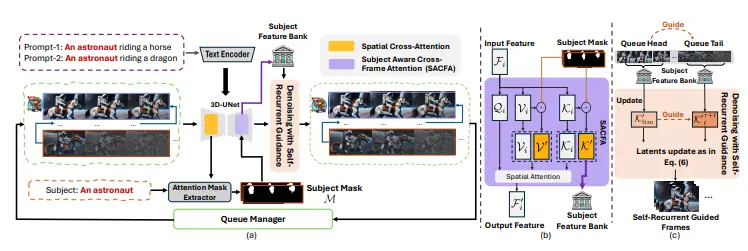
南开大学、巴塞罗那自治大学计算机视觉中心、穆罕默德·本·扎耶德人工智能大学,林雪平大学和软银的研究人员推出1Prompt1Story,旨在解决文本到图像(Text-to-Image,T2I)生成中的一致性问题。具体来说,该方法能够在给定单一提示(prompt)的情况下,生成一系列具有身份一致性的图像,适用于故事叙述、动画制作、视频生成等场景。
- 项目主页:https://byliutao.github.io/1Prompt1Story.github.io
- GitHub:https://github.com/byliutao/1Prompt1Story
- Demo:https://c5e9af216625826dc6.gradio.live
例如,我们有一个关于“一只小狗”的故事,故事中有多个场景:小狗在花园里玩耍、小狗躺在草地上、小狗穿着超人披风等。传统的T2I模型在生成这些场景时,可能会导致小狗的外观在不同场景中发生变化,从而失去身份一致性。而“1Prompt1Story”方法能够确保小狗在所有场景中都保持一致的外观,同时每个场景的背景和细节又能准确反映对应的描述。

主要功能
- 身份一致性:确保在不同场景中生成的图像中的主体(如人物、动物等)保持一致的身份特征。
- 文本对齐:生成的图像能够准确反映输入文本描述的内容。
- 无需训练:该方法无需对预训练的T2I模型进行额外的训练或微调,直接在推理阶段修改输入提示,即可实现一致性生成。
主要特点
- 单提示输入:将所有场景描述整合到一个长提示中,利用语言模型的上下文一致性来保持身份信息。
- 高效性:无需额外训练或复杂的模块设计,直接在现有T2I模型上实现一致性生成。
- 灵活性:可以与现有的控制生成方法(如ControlNet)结合,实现空间控制;也可以与其他方法(如PhotoMaker)结合,提升身份一致性。
工作原理
- 提示整合(Prompt Consolidation):将身份提示(描述主体的特征)和多个场景提示(描述不同场景)合并为一个长提示。
- 奇异值重加权(Singular-Value Reweighting,SVR):通过增强当前场景提示的语义信息,同时抑制其他场景提示的语义信息,减少背景和细节的混合。
- 身份保持交叉注意力(Identity-Preserving Cross-Attention,IPCA):在交叉注意力层中,通过增强身份提示的语义信息,进一步提升生成图像的身份一致性。
具体应用场景
- 动画制作:为动画角色生成不同场景下的连贯图像,确保角色在故事中的身份一致性。
- 故事叙述:在生成故事插图时,保持角色或物体的身份一致性,同时准确反映每个场景的描述。
- 视频生成:为视频生成中的每一帧生成一致的主体,确保视频的连贯性和一致性。
- 互动故事:在互动故事应用中,根据用户的输入动态生成连贯的图像,增强用户体验。
- 个性化图像生成:结合真实图像或其他方法,生成具有特定身份特征的个性化图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











