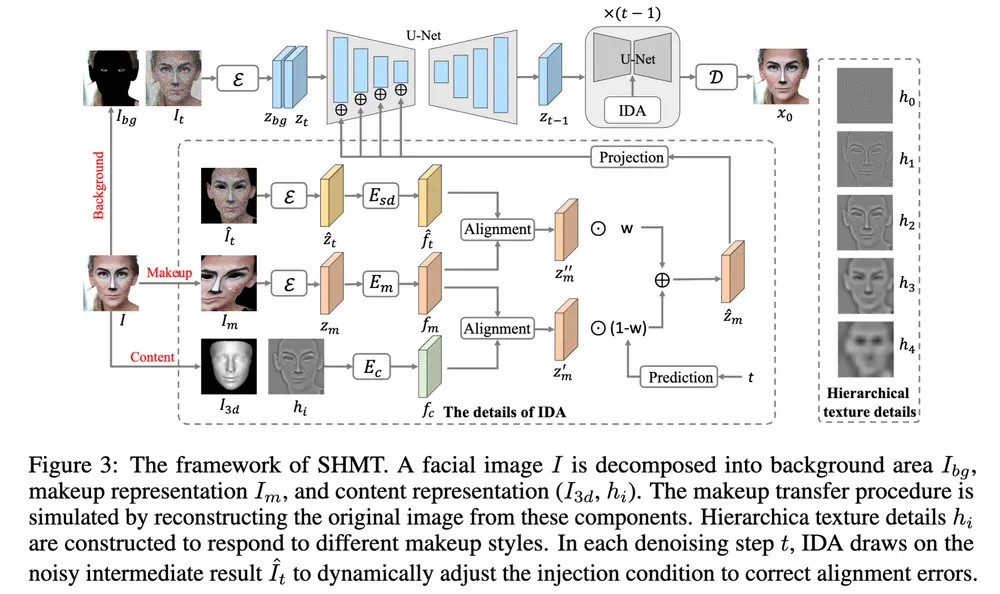
武汉理工大学计算机与人工智能学院、武汉理工大学三亚科教创新园、阿里巴巴集团达摩院、湖畔实验室 和上海人工智能实验室的研究人员推出一种名为 Self-supervised Hierarchical Makeup Transfer(SHMT)的方法,用于解决具有挑战性的妆容迁移任务。该方法旨在将不同的妆容风格精准自然地应用于给定的面部图像,克服了现有方法在无配对数据情况下合成伪真实数据导致妆容保真度低以及难以处理不同妆容风格多样性的问题。
例如,你是一名网红,想要在不同场合展示不同的妆容风格,但不想每次都亲自化妆。使用SHMT方法,你可以上传一张自己的面部照片和一张参考妆容的照片,模型将能够将参考妆容精确地迁移到你的面部上,生成一张新的面部图像,同时保留你的面部特征和表情。

- 精准妆容迁移:能够将参考图像中的妆容风格应用到源图像上,同时保留源图像的内容信息,如背景、面部结构、姿态和表情等,生成高度逼真且妆容风格准确的新面部图像。
- 灵活适应不同妆容风格:通过分层纹理细节处理,可根据妆容风格的复杂程度,选择合适的纹理细节进行重建,有效适应从简单到复杂的各种妆容风格。
- 自监督学习策略:采用 “解耦与重建” 范式,通过将面部图像分解为内容和妆容表示,并从这些组件中重建原始图像,以自监督方式进行模型训练,避免了受不精确伪配对数据的误导。
- 分层纹理细节处理:利用拉普拉斯金字塔分解输入图像的纹理信息,构建分层纹理细节,能够灵活控制不同妆容风格下内容细节的保留或丢弃,更好地适应妆容风格多样性。
- 迭代双重对齐(IDA)模块:结合扩散模型的逐步去噪特性,在每个去噪步骤中,利用中间结果动态调整注入条件,纠正由于内容和妆容表示之间的域差距导致的对齐误差,提高妆容保真度,并可实现空间感知的妆容风格控制。
- 基于潜在扩散模型(LDM):利用 LDM 的结构,包括图像编码器、解码器和 UNet 去噪器。编码器将图像压缩到低维潜在空间,解码器从潜在变量重建原始图像,UNet 去噪器在潜在空间预测噪声。
- 自监督策略
- 前景和背景分割:使用预训练的人脸解析模型分割前景(面部区域)和背景,背景区域与带噪声的图像一起输入模型,模型根据内容和妆容表示填充未知的面部区域。
- 妆容表示:通过对前景图像应用随机裁剪、旋转和弹性扭曲等空间变换来破坏图像内容信息,得到保留妆容信息的表示,这些变换还能模拟语义不对齐情况,增强模型对姿态和表情的鲁棒性。
- 内容表示:将面部内容简化为面部形状和纹理细节。面部形状通过 3DDFA-V2 模型提取,并进行下采样以匹配潜在空间分辨率;纹理细节通过将前景图像转换为灰度图,利用拉普拉斯金字塔分解得到一系列从细到粗的分层纹理细节,根据妆容风格选择合适的纹理细节与面部形状组合作为内容表示。
- 迭代双重对齐(IDA)
- 空间注意力对齐:通过计算内容表示和妆容表示的语义特征之间的像素级相关矩阵,将其作为变形映射函数,对妆容表示的特征图进行空间变形,使其与内容表示语义对齐。
- 动态调整对齐:由于域差距仍可能存在对齐误差,利用去噪过程中的中间结果(去除背景后的带噪声图像)与妆容表示再次计算额外的对齐预测,通过 MLP 模块根据时间步预测两者的混合比例,得到最终混合预测,与内容表示连接后注入去噪器编码器,动态纠正对齐错误。
- 社交媒体和娱乐领域:用户可在社交媒体上分享经过妆容迁移后的个性化照片,或用于虚拟形象的妆容设计,如在虚拟社交平台、在线游戏等场景中,增强角色的个性化和真实感。
- 电子商务领域:在化妆品销售平台上,为顾客提供虚拟试妆功能,帮助顾客直观看到不同妆容在自己脸上的效果,辅助购买决策。
- 影视和广告制作:可为演员或模特快速生成不同妆容效果的图像,用于前期创意构思、角色设计或广告宣传中的视觉效果展示,提高制作效率。
- 美容教学和培训:作为教学辅助工具,帮助化妆师和学员更直观地理解不同妆容风格的特点和效果,提升化妆技巧和审美水平。