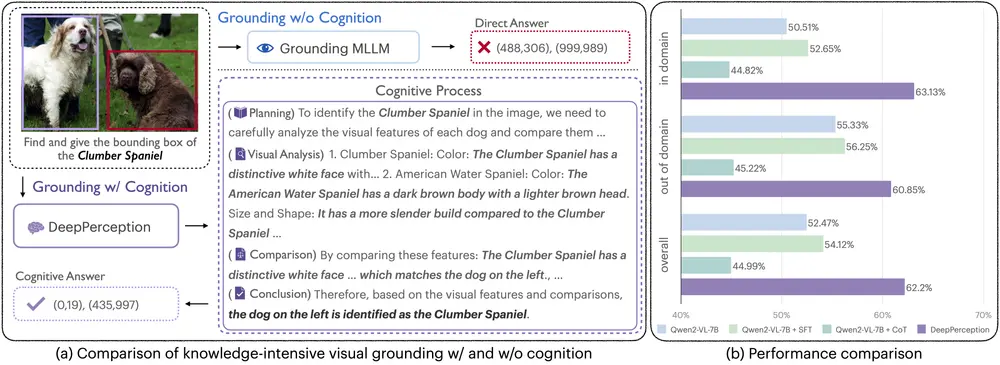
微软印度研究院和微软雷蒙德研究院的研究人员推出运动引导扩散模型Pix2Gif,该模型可用于图像到GIF(视频)的生成。
他们采取了与众不同的方法,将任务定位为受文本和运动幅度提示指导的图像翻译问题。为了确保模型能够遵循运动引导,设计了一个全新的运动引导扭曲模块,该模块能够根据两类提示对源图像的特征进行空间变换。此外,还引入了感知损失,确保变换后的特征图与目标图像处于同一空间,从而保持内容的一致性和连贯性。
在模型训练前,他们从TGIF视频字幕数据集中精心筛选出连贯的图像帧。这个数据集提供了关于主体时间变化的丰富信息。经过预训练后,以零样本的方式将模型应用于多个视频数据集。大量的定性和定量实验表明,Pix2Gif非常有效——它不仅能够捕捉到文本中的语义提示,还能够捕捉到运动引导中的空间提示。

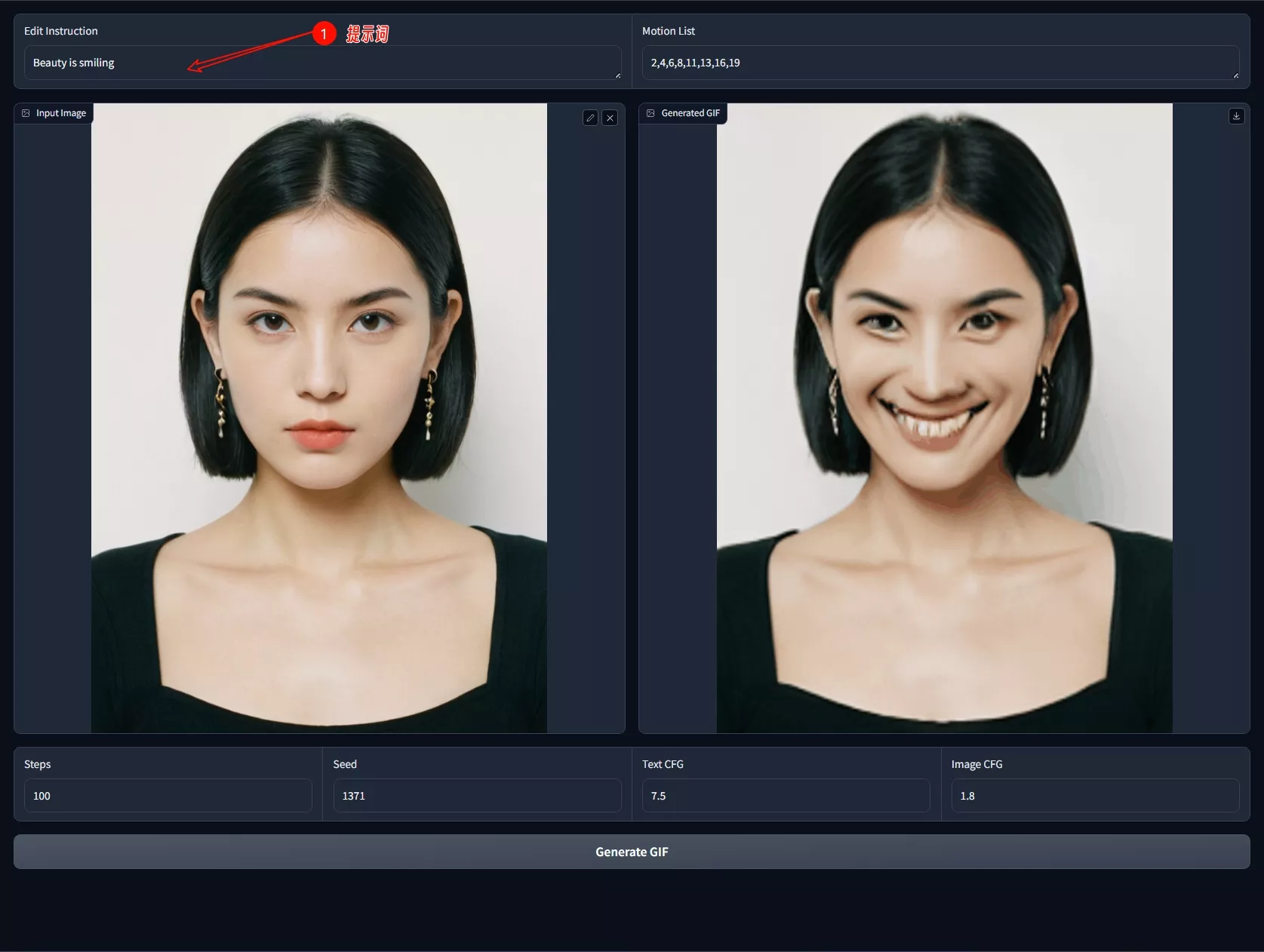
想象一下,你有一张图片,比如一只猫的照片,你想要让这只猫在图片中动起来,比如摇尾巴或者跳跃。Pix2Gif就能够根据你的描述(比如“猫在玩耍”)和指定的动作幅度(比如动作幅度8),生成一系列动态的GIF帧,让静态的猫看起来像是在动。
主要功能:
- 静态图片转动态GIF: 用户可以输入一张图片和一个描述动作的文本,模型会生成一系列动态的GIF帧。
- 动作幅度控制: 用户可以指定动作的幅度,模型会根据这个幅度生成相应动作的GIF。
主要特点:
- 高质量生成: 生成的GIF具有高空间质量和时间一致性。
- 文本和动作引导: 模型不仅能够理解文本描述,还能根据动作幅度生成相应的动态效果。
- 数据集准备: 研究者们精心策划了一个数据集,从中提取了连贯的图像帧,这些帧提供了丰富的关于主体时间变化的信息。
工作原理:
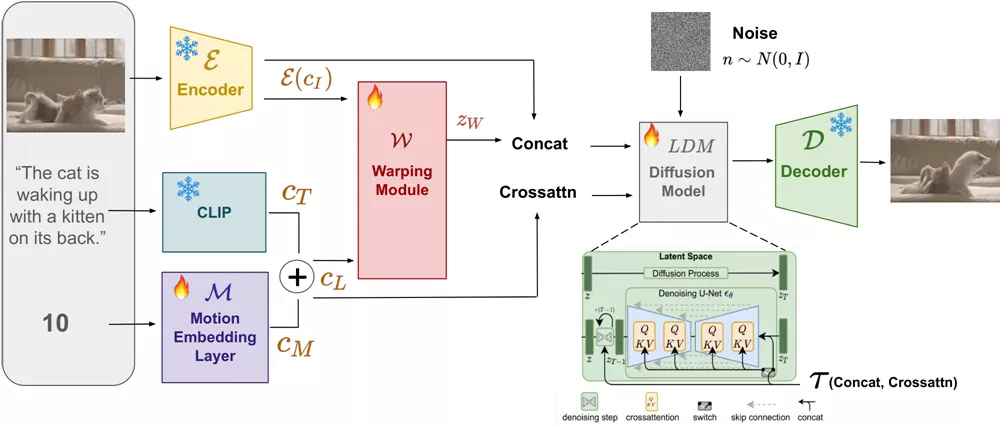
- 数据集构建: 使用Tumblr GIF(TGIF)数据集,提取GIF帧并计算帧之间的光流(optical flow),以捕捉动作信息。
- 模型训练: 模型基于潜在扩散模型(latent diffusion models, LDMs),通过训练学习如何根据文本和动作幅度提示生成GIF。
- 运动引导变形模块: 为了确保模型遵循动作引导,提出了一个新的运动引导变形模块,它根据文本和动作幅度提示空间变换源图像的特征。
- 感知损失: 引入了感知损失(perceptual loss),以确保变换后的特征图与目标图像在同一空间内,确保内容的一致性和连贯性。
Pix2Gif是一个创新的工具,它通过结合文本描述和动作幅度,将静态图片转化为动态GIF,这在设计、娱乐和内容创作等领域有着广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











