来自谷歌和MIT的研究人员提出一种新型视觉模型训练方法SynCLR,它完全从生成模型中学习,而不需要任何真实数据。
SynCLR的核心思想是利用大语言模型(LLMs)生成大量的图像文本,然后通过文本到图像的生成模型来创建与这些文本相对应的图像。通过对比学习,这些合成图像被用来训练视觉表示模型,使得生成的表示能够很好地迁移到多种下游任务中,例如图像分类。
三个简单步骤
- 使用 Llama 2 生成大量文本
- 使用 Stable Diffusion 1.5 根据文本生成图像
- 通过对比学习+掩模图像建模训练视觉模型
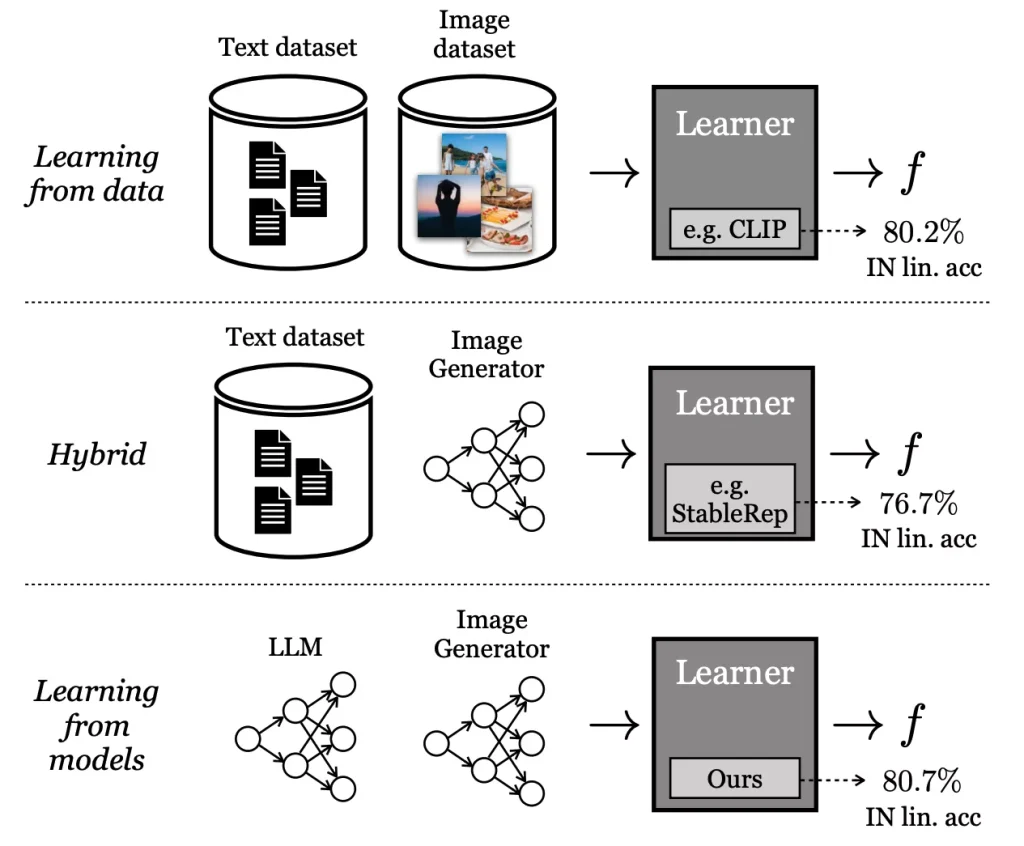
主要特点:
- 无需真实数据:SynCLR完全依赖于合成数据进行训练,这减少了对大规模真实数据集的依赖。
- 高质量的视觉表示:尽管只使用合成数据,SynCLR生成的视觉表示在多个任务上的表现与使用真实数据训练的模型(如CLIP)相当。
- 迁移能力强:在图像分类和语义分割等任务中,SynCLR展现出了强大的迁移能力,能够在没有额外微调的情况下,与真实数据训练的模型竞争。
工作原理:
SynCLR的工作流程可以分为三个主要步骤:
- 字幕合成:首先,使用LLMs生成大量的图像字幕,这些字幕描述了各种视觉概念。
- 图像生成:然后,利用文本到图像的生成模型,根据这些合成字幕生成对应的图像。
- 视觉表示学习:最后,通过对比学习的方法在这些合成图像上训练视觉表示模型,使得具有相同字幕的图像在表示空间中彼此接近。
应用场景:
- 图像分类:SynCLR可以用于训练图像分类模型,这些模型在没有真实图像数据的情况下也能学习到有效的视觉特征。
- 语义分割:在需要对图像中的不同区域进行精确识别的任务中,如自动驾驶车辆的路面识别,SynCLR可以提供高质量的预训练模型。
- 艺术创作:艺术家和设计师可以利用SynCLR生成的图像作为灵感,创作新的艺术作品或设计。
- 数据增强:在数据稀缺的领域,SynCLR可以生成合成图像作为真实数据的补充,帮助提高模型的泛化能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...