来自上海科技大学、影眸科技、香港大学和叠境数字科技的研究人员提出一个基于扩散的生成模型Media2Face,它能够根据语音信号和多模态条件(如文本、图像)生成同步的面部动画和头部姿势。
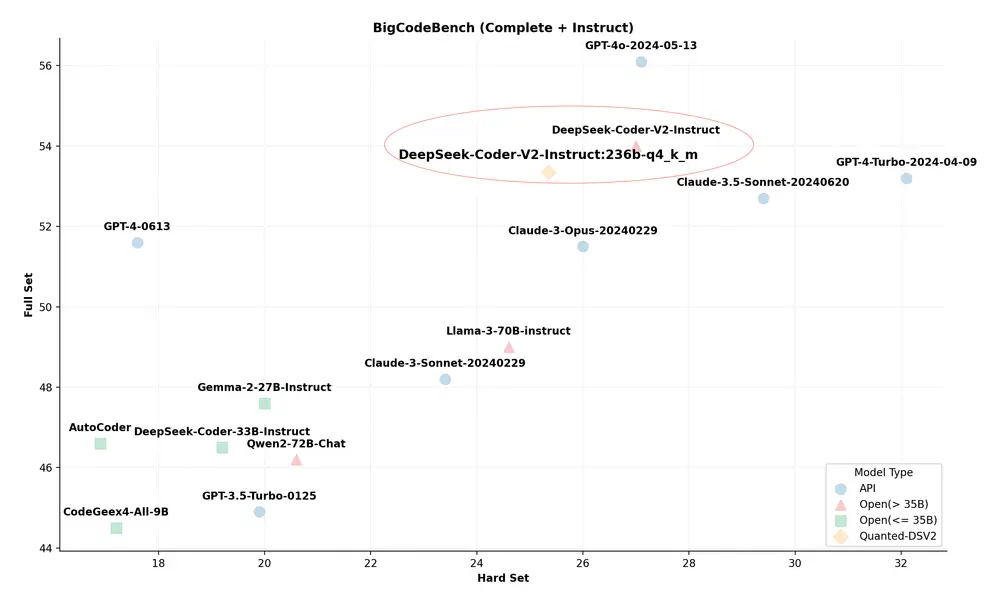
Media2Face的核心是一个名为Generalized Neural Parametric Facial Asset(GNPFA)的模型,它能够从大量的视频中提取高质量的面部表情和准确的头部姿势。这个系统不仅能够生成逼真的面部动画,还能够根据文本或图像提示调整风格,使得生成的动画更加多样化和个性化。
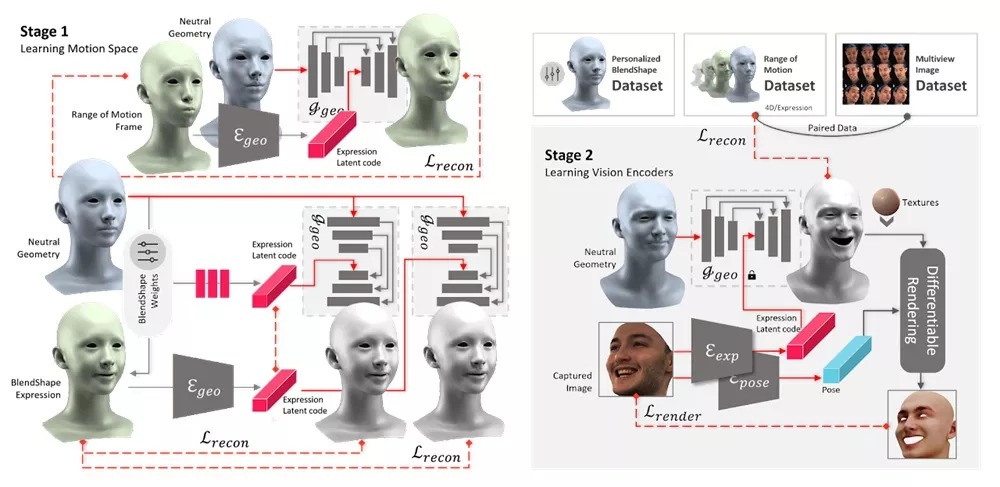
主要特点:
- 多模态输入:Media2Face能够接受音频、文本和图像等多种输入,生成与这些输入相匹配的面部动画。
- 高质量的面部动画:通过GNPFA模型,Media2Face能够生成高质量的面部表情和头部姿势,使得动画更加逼真。
- 风格控制:系统能够根据用户提供的风格提示(如文本描述或图像)来调整生成的动画风格。
- 快速生成:Media2Face采用了扩散模型,能够在较短的时间内生成高质量的动画。
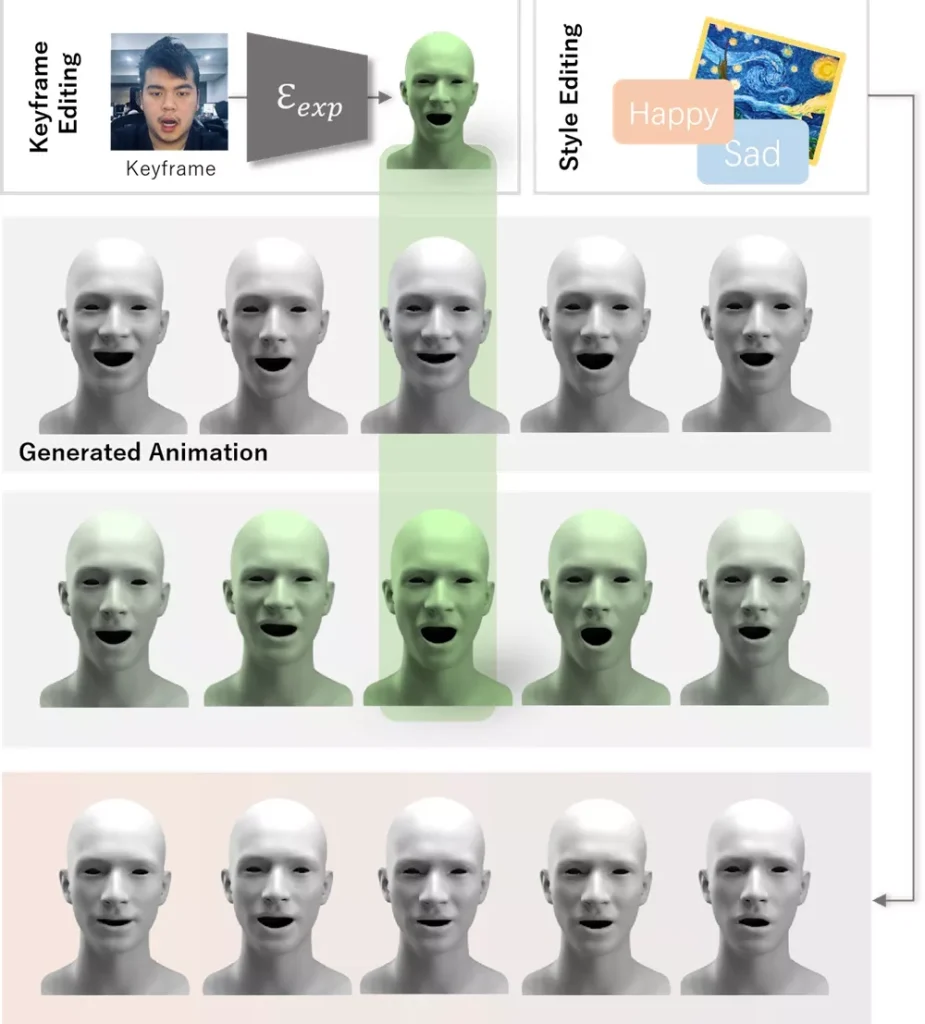
工作原理:
Media2Face的工作原理可以分为以下几个步骤:
- GNPFA训练:首先,使用大量的4D面部扫描数据训练GNPFA,学习面部表情和头部姿势的潜在空间表示。
- 数据提取:利用GNPFA从各种视频中提取面部表情和头部姿势,构建一个多样化的3D面部动画数据集(M2F-D)。
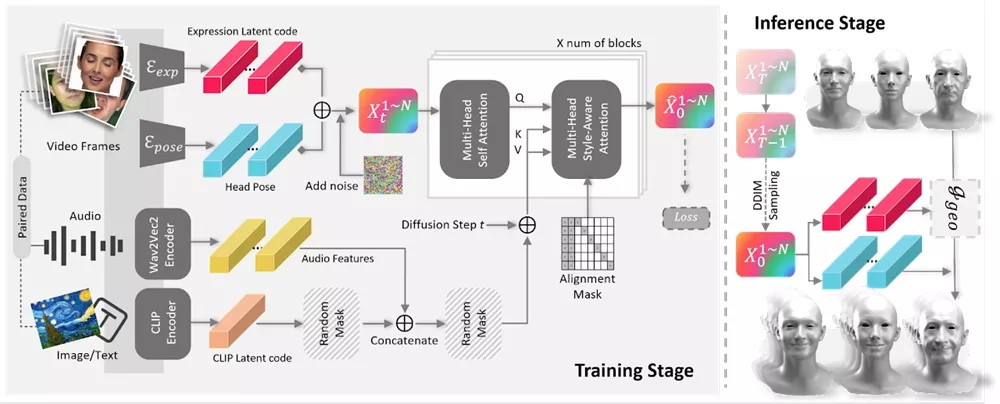
- 扩散模型训练:在GNPFA的潜在空间中训练Media2Face,使其能够根据音频特征和文本/图像提示生成面部动画。
- 条件生成:在生成过程中,Media2Face结合音频和风格提示,通过扩散模型逐步去除噪声,生成与输入条件相匹配的面部动画。
应用场景:
- 虚拟角色:在游戏、电影和动画制作中,Media2Face可以用来生成与角色语音同步的面部动画,提高角色的真实感。
- 社交媒体:用户可以通过Media2Face创建个性化的虚拟形象,用于社交媒体互动或内容创作。
- 教育和培训:在语言学习或演讲训练中,Media2Face可以帮助用户通过观察和模仿生成的面部动画来提高表达能力。
- 娱乐和艺术创作:艺术家和设计师可以利用Media2Face生成具有特定风格和情感的面部动画,用于艺术作品或创意项目。
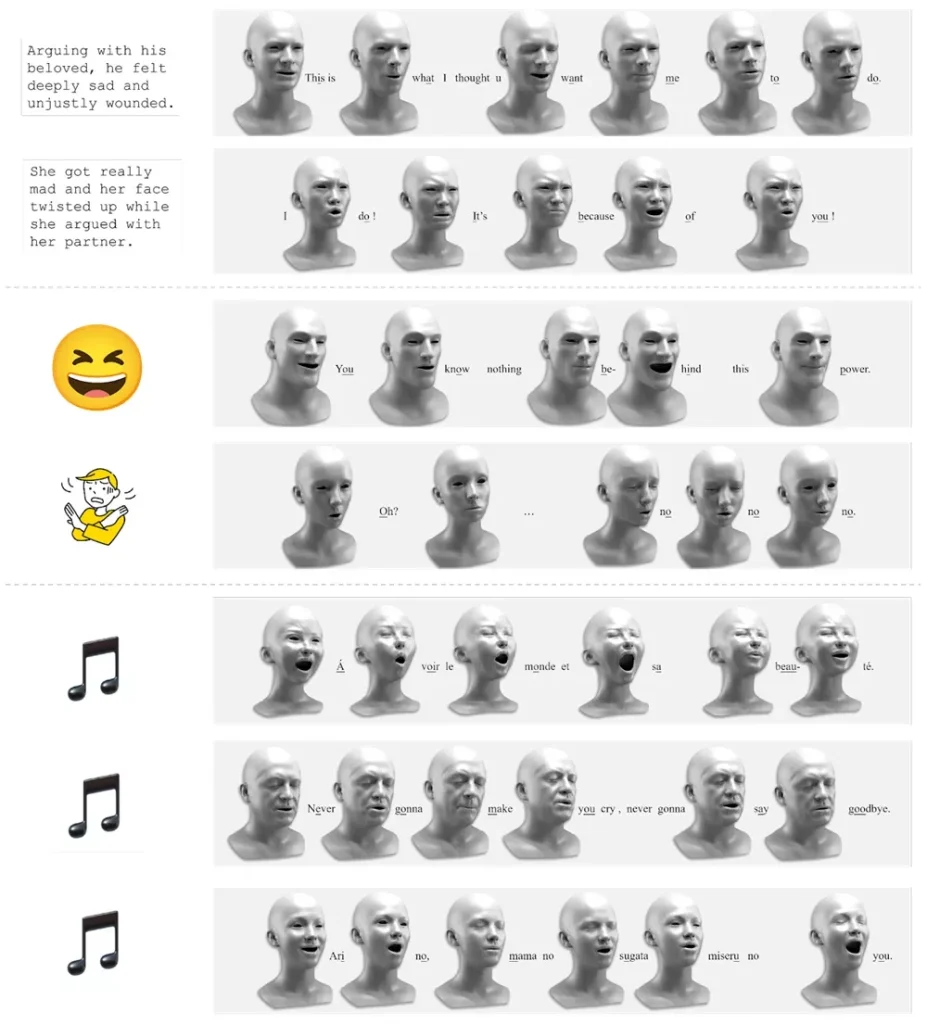
实验结果表明,Media2Face在面部动画合成方面取得了很好的效果,并且可以广泛应用于各种多模态引导的场景中,例如从音频、文本和图像中生成逼真的面部动画。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











