
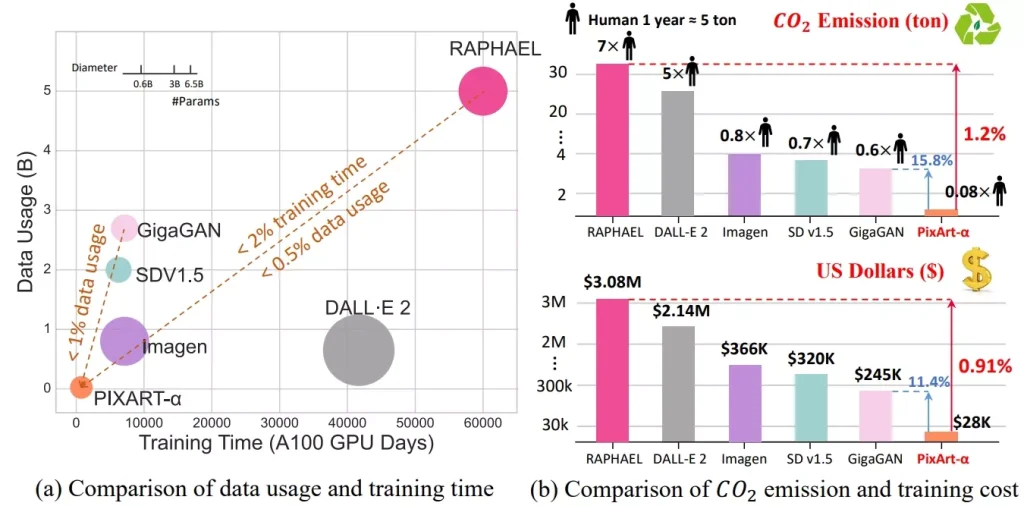
来自华为诺亚方舟实验室、大连理工大学、香港大学、香港科技大学的研究人员推出了文本到图像合成框架PIXART-δ,这是去年发布的PIXART-α模型的一个升级版本。PIXART-α以其高效的训练过程和生成高质量1024像素分辨率图像的能力而闻名。
PIXART-δ通过整合潜在一致性模型(LCM)和ControlNet,显著提高了推理速度,能够在2-4步内生成高质量的图像。PIXART-被设计为能够在单天内在32GB V100 GPU上进行高效训练。它还具备8-bit的推理能力,可以在8GB GPU内存限制下生成1024px图像,大大提高了其可用性。

此外,将ControlNet样模块纳入其中,使用户能够细粒度控制文本到图像的扩散模型。开发者还设计了一个新颖的ControlNet-Transformer架构,专门针对Transformer模型设计,实现明确可控性并获得高质量图像生成。

主要特点:
- 快速推理:PIXART-δ能够在0.5秒内生成1024×1024像素的图像,比PIXART-α快7倍。
- 8位推理能力:在8GB GPU内存限制下,PIXART-δ能够合成1024px的图像,提高了其可用性和可访问性。
- 精细控制:通过整合类似ControlNet的模块,PIXART-δ能够对文本到图像扩散模型的输出进行精细控制。
- ControlNet-Transformer架构:专门为Transformer模型设计的ControlNet-Transformer架构,实现了明确的控制能力,同时保持了高质量的图像生成。
工作原理:
PIXART-δ的工作原理主要基于以下几个关键技术:
- Latent Consistency Model (LCM):通过将反向扩散过程视为解决增强概率流常微分方程(PF-ODE),LCM能够快速生成样本,同时保持生成图像的质量。
- ControlNet-Transformer:这是一个为Transformer模型量身定制的ControlNet架构,它通过在模型的前几个基础块中创建可训练的副本,并与冻结块的输出相结合,实现了对生成图像的精细控制。
- 训练效率:PIXART-δ能够在有限的GPU内存下进行训练,支持高分辨率图像生成,并且训练过程快速收敛。

具体应用场景:
- 实时图像生成:PIXART-δ的快速推理能力使其适用于需要实时图像生成的应用,如游戏、虚拟现实(VR)和增强现实(AR)。
- 艺术创作:艺术家和设计师可以利用PIXART-δ生成具有精细控制的高质量图像,用于创作独特的艺术作品。
- 内容创作和社交媒体:用户可以通过简单的文本提示生成个性化的图像,用于社交媒体、广告或个人项目。
- 教育和研究:PIXART-δ可以用于教育领域,帮助学生和研究人员理解图像生成过程,或者用于研究新的图像生成技术和算法。

ControlNet-Transformer相比ControlNet-UNet的主要优势包括:
- 更流畅的数据流:ControlNet-Transformer的设计更贴合Transformer模型的数据流,能够更好地利用Transformer的优势,而ControlNet-UNet引入了不存在的“编码器”和“解码器”阶段,偏离了Transformer的天然数据处理模式。
- 更强的可控性:ControlNet-Transformer的可控性随着复制块数的增加而增强,在类似人脸和身体边缘等挑战性条件下,表现明显优于ControlNet-UNet。
- 更快的收敛速度:ControlNet-Transformer在边缘条件下的收敛速度明显优于ControlNet-UNet,通常在1000步内就可以取得令人满意的边缘结果。
- 更高质量的生成:实验结果显示,ControlNet-Transformer的生成质量明显优于ControlNet-UNet,无论是边缘细节还是整体生成效果。

如何使用PIXART-δ?
目前开发人员释出了2个Hugging Face Demo和1个谷歌Colab Demo,点击进入Demo即可使用。
Hugging Face Demo
这两个 Demo一个是PixArt-α,一个是PixArt-LCM,进入Demo输入提示词即可开始生成图片。
Hugging Face Demo
PixArt-α
目前只支持英文提示词,填写提示词后即可开始进行生图,按照SD模型的格式进行书写即可。

👇设置项目

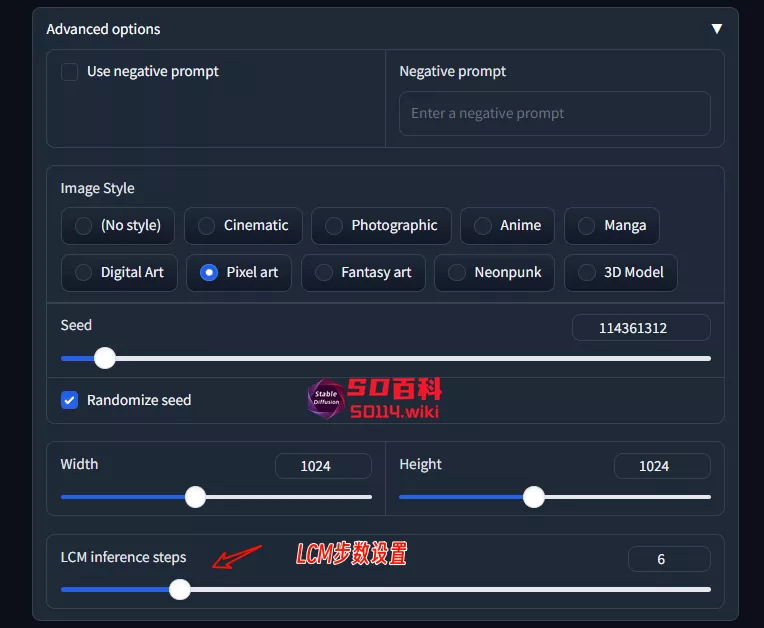
PixArt-LCM
使用方法与PixArt-α相同,只是在高级设置中调节LCM步数即可

👇设置项目
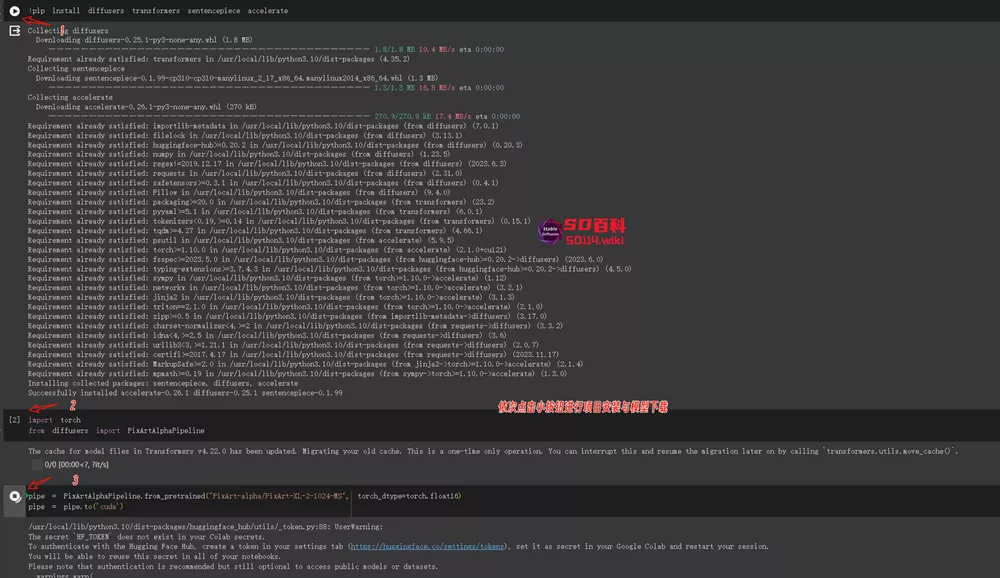
谷歌Colab Demo
进入Colab后依次点击进行项目加载与模型下载
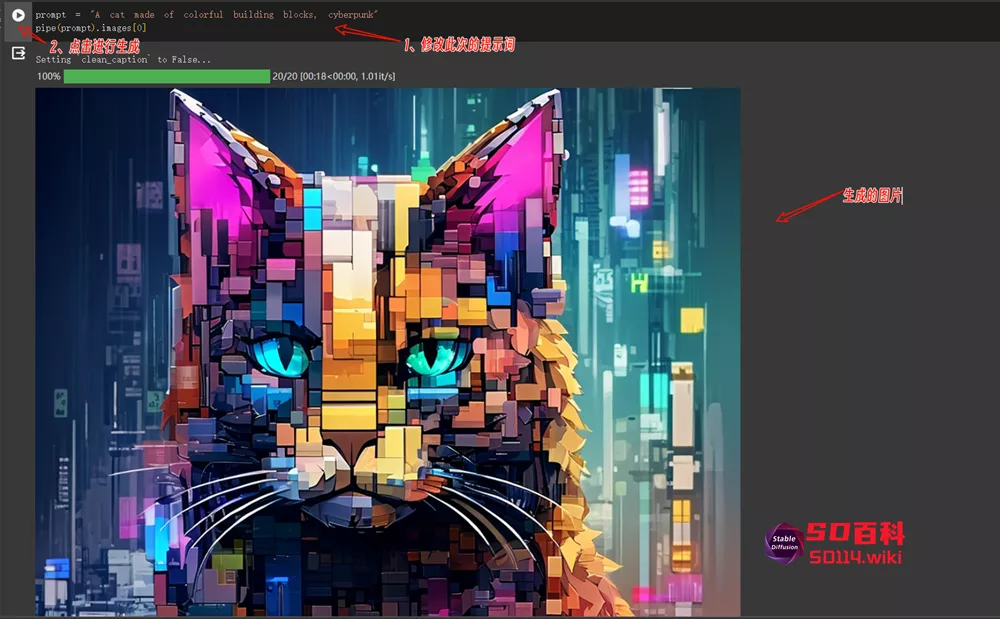
下载完模型后即可修改提示词进行生图
本地安装
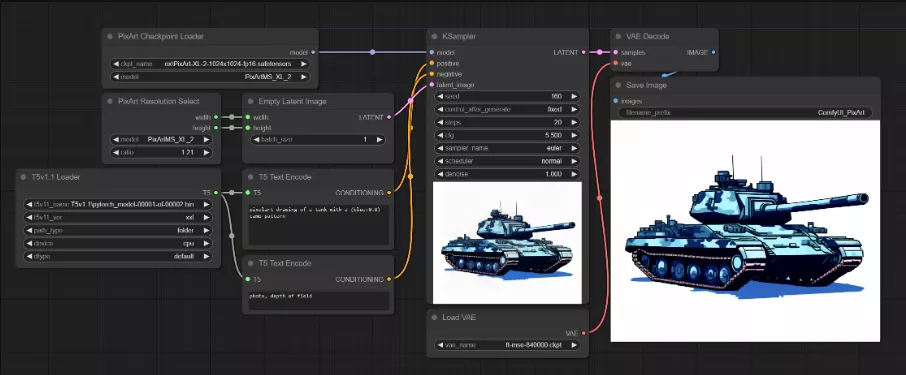
安装官方GitHub页面提供的安装方法即可进行安装,但安装比较麻烦,目前已有开发者开发了ComfyUI插件,让大家可以在ComfyUI上运行此模型。
总结
目前PixArt-α与PixArt-LCM生成的图片,依旧没有解决人物手指问题,与SD模型相比,虽然PixArt-α去年就已经开源发布,但用户很少,因此没有开发者针对此模型开发应用与微调模型,不过还是希望此模型继续进行开发。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











