阿里巴巴集团智能计算研究院、中国科学院自动化研究所、清华大学和中国科学院大学的研究人员推出大规模视频动作数据集EgoVid-5M,专为第一人称视角(egocentric)视频生成而设计。该数据集包含了500万个第一人称视频剪辑,并且富含详细的动作注释,包括精细的运动控制和高级文本描述。此外,该数据集通过强大的数据清洗策略确保了帧一致性、动作连贯性和运动平滑性,以适应第一人称视角的条件。
- 项目主页:https://egovid.github.io
- GitHub:https://github.com/JeffWang987/EgoVid
- 数据:https://modelscope.cn/datasets/iic/EgoVid
例如,考虑一个厨师在厨房烹饪的场景。EgoVid-5M数据集中可能包含从厨师的第一人称视角拍摄的视频剪辑,详细记录了切菜、炒菜等动作。这些视频不仅包含了动作的视觉信息,还有相应的文本描述(如“厨师正在切洋葱”)和运动控制数据(如手部移动的速度和方向),这为训练和生成第一人称视角的视频提供了丰富的信息。

主要功能和特点
- 大规模和高质量:EgoVid-5M提供了500万个1080p分辨率的第一人称视频剪辑,经过严格的数据清洗过程。
- 全面的场景覆盖:数据集涵盖了家庭环境、户外场景、办公活动、运动和技能操作等多种场景,包含数百个动作类别。
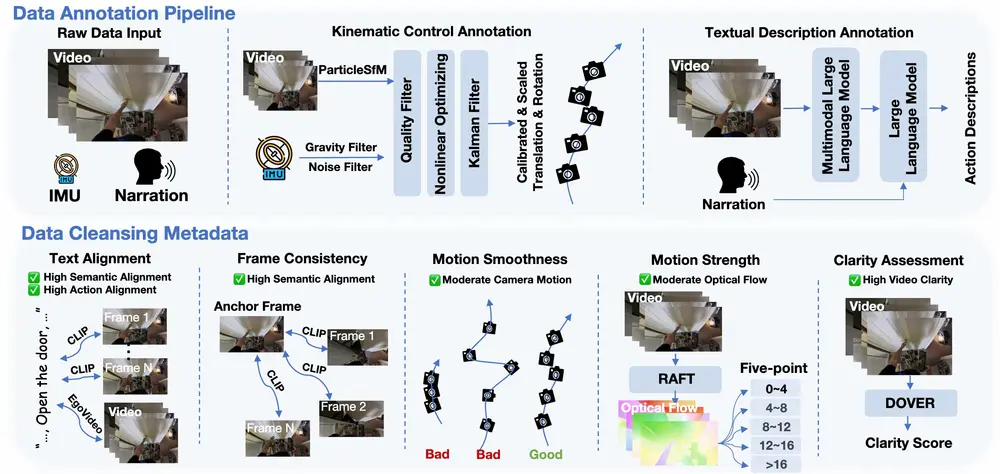
- 详细且精确的注释:包括精细的运动控制(如视觉惯性里程计VIO提供的精确注释)和高级动作描述(利用大型语言模型生成的详细文本注释)。
- 数据清洗:通过数据清洗流程确保动作描述与视频内容的对齐、运动的幅度和帧之间的一致性。
工作原理
EgoVid-5M的工作原理包括以下几个步骤:
- 数据注释流程:利用视觉惯性里程计(VIO)方法构建运动控制信号,并使用大型语言模型生成详细的文本注释。
- 数据清洗流程:通过CLIP模型评估文本描述与视频帧之间的对齐,以及帧之间的语义一致性,同时评估运动的平滑度和视频的清晰度。
- EgoDreamer模型:提出了EgoDreamer模型,能够同时由动作描述和运动控制信号驱动生成第一人称视频。
具体应用场景
EgoVid-5M数据集的应用场景包括:
- 虚拟现实(VR):在虚拟环境中提供更加沉浸式和互动式的体验。
- 增强现实(AR):在现实世界中叠加虚拟信息时,提供第一人称视角的自然交互。
- 游戏:在游戏中创建更加真实的第一人称视角体验。
- 模拟训练:用于模拟训练,如驾驶模拟器或手术模拟器,提供基于真实数据的虚拟训练环境。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











