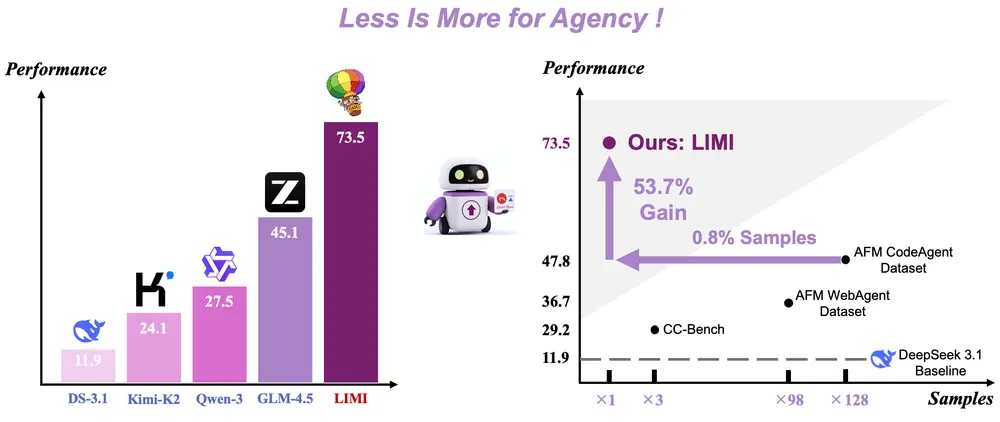
中国科学院深圳先进技术研究院、中国科学院大学、上海人工智能实验室和上海交通大学的研究人员推出一个通用且简洁的 TransAgent 框架,它的目标是提升视觉-语言基础模型(比如CLIP)在新领域中的泛化能力。这些模型在预训练阶段会学习大量的图像和文本对,但在实际应用中,目标领域的数据可能与预训练阶段的数据有很大差异,这使得模型很难适应新环境。为了解决这个问题,TransAgent通过与多种不同的“专家模型”合作,将它们的知识整合起来,以增强基础模型的泛化能力。
例如,我们有一个任务,需要识别一系列卫星图像中的不同地形类型。由于这些图像与模型在预训练时看到的网络图像差异很大,直接使用预训练模型可能效果不佳。TransAgent可以通过整合专门处理卫星图像的专家模型的知识,帮助基础模型更快地适应这个新领域,从而提高识别的准确性。
主要功能和特点:
- 知识多样性:TransAgent利用了11种不同的异构代理模型,这些模型在视觉识别、密集预测、聊天机器人、文本编码和多模态生成等领域具有丰富的知识。
- 转移灵活性:TransAgent提供了一种通用的知识提取方法,允许在未来灵活地扩展更多代理模型。它还引入了一种混合代理门控机制,可以自动通过软权重选择不同领域的代理模型。
- 部署效率:通过多源知识蒸馏,TransAgent将异构代理模型的知识转移到CLIP模型中。由于所有预训练模型在训练阶段都是固定的,微调工作量很小,且在推理阶段可以卸载所有外部代理模型,保持了与原始CLIP相同的推理流程。
工作原理:
TransAgent通过以下步骤工作:
- 视觉代理协作(VAC):通过混合代理门控机制整合不同视觉代理模型的特征,然后通过特征蒸馏将这些知识转移到CLIP的视觉编码器中。
- 语言代理协作(LAC):与视觉代理协作类似,但针对的是文本特征,通过与聊天机器人等语言模型的交互,丰富类别描述,然后通过特征蒸馏增强CLIP的文本表示。
- 多模态代理协作(MAC):利用多模态代理模型(如文本到图像生成模型和图像到文本描述模型)来进一步对齐视觉和文本提示,通过KL散度蒸馏学习分数向量。
具体应用场景:
- 跨领域图像识别:例如,在一个包含卫星图像的数据集中,这些图像与预训练时使用的网络图像差异很大,TransAgent可以帮助模型更好地适应这种领域转变。
- 少样本学习:在只有少量标注数据的情况下,TransAgent可以通过整合不同代理模型的知识,提高模型在新任务上的学习能力。
- 多模态任务:在需要同时处理图像和文本的任务中,如图像描述生成或视觉问答,TransAgent可以增强模型的多模态理解能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...