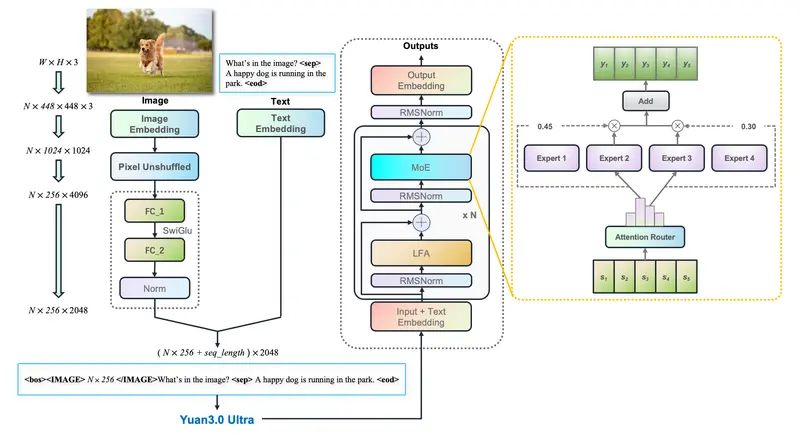
Google DeepMind、密歇根大学和布朗大学的研究人员推出一个名为“Motion Prompting”的框架,它用于控制视频生成中的动作轨迹。该框架通过使用运动轨迹作为条件信号,来生成具有特定动作和动态表现的视频内容。例如,我们想要生成一个视频,内容是“一只猫转动它的头”。使用Motion Prompting框架,我们可以通过指定猫头部的运动轨迹来精确控制视频中猫头的转动动作。这比仅使用文本提示(例如“猫快速转头”)更精确,因为文本提示可能被以多种不同的方式解释。

主要功能:
- 动作控制:通过指定运动轨迹来控制视频中对象的动作。
- 运动提示扩展:将用户高层次的动作请求(如“围绕xz平面移动相机”)转换成详细的运动轨迹。
- 视频生成:基于给定的第一帧图像、文本提示和运动提示生成视频。
- 交互式编辑:允许用户通过鼠标拖动等交互方式直接“操作”图像或视频。
主要特点:
- 灵活性:能够编码任意数量的轨迹,包括对象特定的或全局场景的运动。
- 运动表示:使用点轨迹(也称为粒子视频或点跟踪)来表示运动,这可以捕捉任何类型的动作。
- 自我监督学习:通过原始文本-视频对作为条件,利用视频本身作为去噪目标,实现自我监督学习。
- 统一框架:适用于多种任务,如对象控制、相机控制、运动转移和图像编辑。
工作原理:
Motion Prompting框架基于预训练的视频扩散模型(如Lumiere),通过在模型上训练一个ControlNet来接受运动提示条件。在训练过程中,使用从视频中提取的运动轨迹作为条件信号,并将这些轨迹编码到一个时空体积中。在推理时,用户可以提供稀疏或密集的运动轨迹,模型将这些轨迹转换为视频内容。此外,该框架还可以通过计算机视觉信号将高级用户请求转换为详细的运动轨迹,实现更细粒度的控制。
具体应用场景:
- 电影和视频制作:生成具有特定动作和动态的视频内容。
- 交互式媒体:允许用户通过交互式操作来编辑或生成视频。
- 虚拟现实和游戏:根据用户的动作输入实时生成视频内容。
- 教育和培训:创建模拟真实世界动态的教学视频。
- 艺术创作:艺术家和设计师可以探索新的创作工具,通过运动控制来创造动态艺术作品。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...