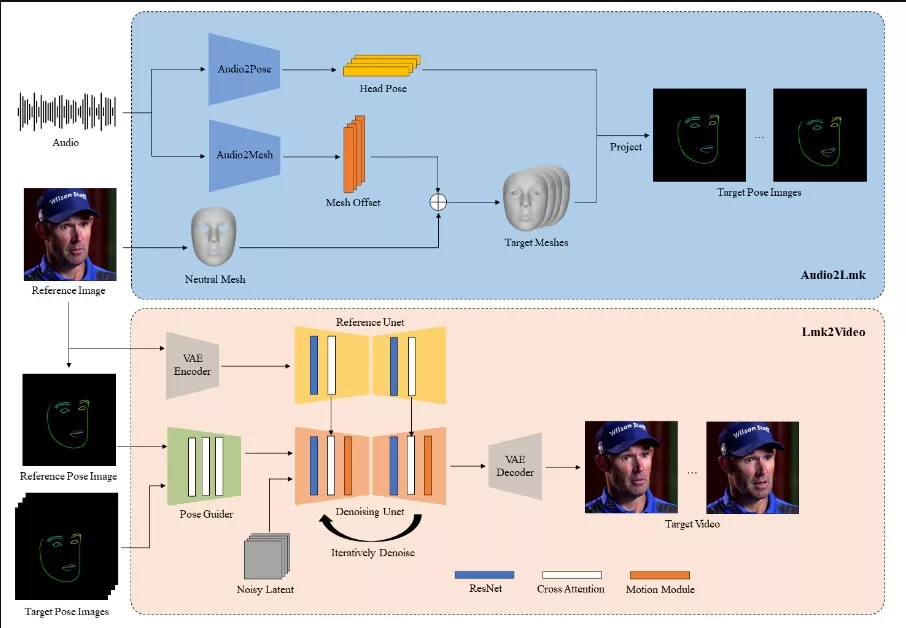
腾讯推出创新框架AniPortrait,它可以根据音频和一张参考肖像图片生成高质量的动画。这个系统可以捕捉到音频中的微妙表情和唇部动作,并将这些动作应用到一个静态的肖像图片上,从而创建出看起来像是在说话或做出表情的动画。(与之前阿里推出的创新框架EMO:只需要提供一张静态照片和一段语音,就能生成口型匹配的视频相似)
- GitHub:https://github.com/Zejun-Yang/AniPortrait
- 模型地址:https://huggingface.co/ZJYang/AniPortrait/tree/main
- DEMO:https://huggingface.co/spaces/ZJYang/AniPortrait_official

主要功能和特点:
- 音频驱动的动画生成: AniPortrait能够根据音频文件中的声音节奏和语调,生成与之匹配的面部表情和唇部动作。
- 3D中间表示: 系统首先从音频中提取3D面部网格和头部姿态,然后将这些3D信息转换成2D面部关键点。
- 高质量的视觉效果: 通过使用扩散模型和运动模块,AniPortrait能够生成具有丰富表情和自然头部动作的逼真动画。
- 灵活性和可控性: 由于使用了3D中间表示,用户可以对这些表示进行编辑,以实现面部运动编辑或面部重演等高级功能。
工作原理:
- 音频处理: 系统首先使用预训练的wav2vec模型从音频中提取特征,这些特征能够捕捉到发音和语调。
- 3D面部网格和姿态提取: 利用提取的音频特征,系统通过两个全连接层转换成3D面部网格,同时使用Transformer解码器生成头部姿态。
- 2D关键点投影: 将3D面部网格和姿态转换为2D面部关键点序列。
- 动画生成: 使用一个强大的扩散模型(如Stable Diffusion 1.5),结合运动模块,将2D关键点序列转换成一系列连贯且逼真的动画帧。
应用场景:
- 虚拟现实和游戏: 在虚拟角色或游戏角色的创建中,AniPortrait可以用来生成逼真的角色动画,提高用户的沉浸感。
- 数字媒体: 可以用于数字媒体制作,如广告、社交媒体内容或其他视频制作,让静态图片动起来,增加内容的吸引力。
- 面部表情编辑: 由于系统提供了对3D面部表示的控制,用户可以编辑特定的面部表情或唇部动作,用于视频编辑或特效制作。
实验结果表明,AniPortrait在面部自然性、姿态多样性和视觉质量方面表现出卓越性能,从而提供了更出色的视觉体验。此外,我们的方法在灵活性和可控性方面展现出巨大的潜力,可以广泛应用于面部运动编辑或面部重演等领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











