谷歌的研究团队推出了新的文生图模型MobileDiffusion,它能够在手机上几乎瞬间(亚秒级)生成高质量的图片。该模型在架构和采样技术方面进行广泛优化,在iPhone 15 Pro上,MobileDiffusion能够在0.2秒内生成512×512像素的高质量图片,这在移动设备上是前所未有的。
以下是官方原文对该模型的介绍:
文生图(T2I)模型已经在将文本提示转化为高质量图像方面表现出卓越的能力。然而,这些领先的模型包含了数十亿个参数,导致运行成本极高,通常需要依赖性能强大的台式机或服务器(例如 Stable Diffusion、DALL·E 和 Imagen)。尽管在过去一年中,Android 通过 MediaPipe 和 iOS 通过 Core ML 的推理解决方案取得了进展,但移动设备上的快速(亚秒级)文生图仍然是一个难以实现的目标。

为了解决这个问题,我们提出了专为移动设备量身定做的文生图模型MobileDiffusion。在推理过程中,我们还采用了 DiffusionGAN 来实现一步采样,这种方法在微调预训练扩散模型的同时,利用生成对抗网络(GAN)来模拟去噪步骤。我们在 iOS 和 Android 的高端设备上对 MobileDiffusion 进行了测试,该模型能够在半秒钟内生成一个 512x512 的高质量图像。其相对较小的模型尺寸,仅520M参数,使其特别适合移动部署。

背景
文生图模型的效率问题主要源于两大挑战。首先,这类模型生成图像时需要进行迭代去噪处理,这意味着模型需要多次执行。其次,文生图模型中的网络架构复杂性涉及大量参数,通常达到数十亿,这使得模型评估的计算成本非常高昂。因此,尽管在移动设备上部署生成模型具有潜在的好处,如提升用户体验和解决新兴的隐私问题,但在当前文献中,这仍然是相对未被探索的领域。
提高文生图模型的推理效率是当前研究的热点。先前的研究主要集中在解决第一个挑战,即减少函数评估的次数(NFEs)。通过采用先进的数值求解器(如 DPM)或蒸馏技术(如渐进蒸馏、一致性蒸馏),必要的采样步骤已从数百次降至个位数。最新技术如 DiffusionGAN 和对抗性扩散蒸馏( Adversarial Diffusion Distillation)甚至实现了单步采样。
但在移动设备上,即使评估步骤很少,模型的复杂架构也可能导致速度缓慢。到目前为止,文生图模型架构的效率问题相对较少受到关注。一些早期研究曾简要提及这个问题,例如通过移除多余的神经网络块(如 SnapFusion)来提高效率。然而,这些研究并未对模型架构中的每个组件进行深入分析,因此未能提供一个全面的高效率架构设计指南。
MobileDiffusion
为了有效应对移动设备计算能力限制所带来的挑战,我们需要对模型架构的效率进行深入和全面的探究。为了达成这一目标,我们的研究对 Stable Diffusion 的 UNet 架构(UNet architecture)中的每个组件和计算操作进行了详尽的分析。我们提出了一整套全面的指导原则,用于打造高效的文生图扩散模型,最终成果便是 MobileDiffusion。
MobileDiffusion 的设计遵循潜在扩散模型( latent diffusion models),由三个主要部分构成:文本编码器、扩散 UNet 和图像解码器。在文本编码器方面,我们采用了 CLIP-ViT/L14( CLIP-ViT/L14,),这是一个参数量较小(125M 参数)的模型,非常适合移动设备使用。接下来,我们将研究的重点放在了扩散 UNet 和图像解码器上。
Diffusion UNet
如下图所示,Diffusion UNet通常会在transformer 块和convolution 块之间交错排列。我们对这两种基本构建块进行了全面的研究。在整个研究中,我们控制了训练流程(例如,数据,优化器),以研究不同架构的效果。
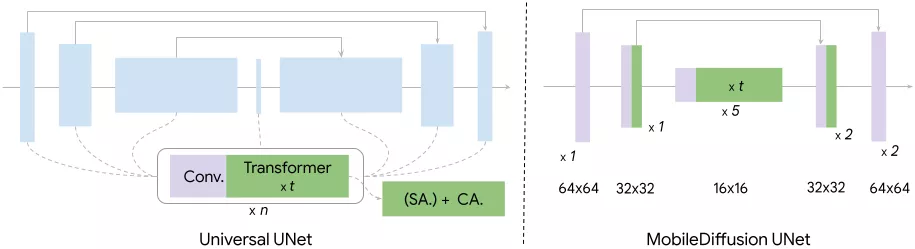
在经典的文生图模型中,一个Transformer块由一个自注意力层(SA)组成,用于模拟视觉特征之间的长距离依赖关系,一个交叉注意力层(CA)用于捕捉文本条件和视觉特征之间的交互,以及一个前馈层(FF)来后处理注意力层的输出。这些Transformer块在文生图模型中扮演着关键角色,作为主要负责文本理解的组件。然而,由于注意力操作的计算成本与序列长度的平方成正比,它们也带来了显著的效率挑战。我们遵循了UViT架构的理念,该架构在UNet的瓶颈处放置了更多的Transformer块。这种设计选择的动机在于,由于瓶颈处的维度较低,注意力计算在瓶颈处的资源消耗较少。
convolution块,特别是ResNet块,在UNet的每个层级都得到了部署。虽然这些块对于特征提取和信息流动至关重要,但在高分辨率级别上,相关的计算成本可能会非常大。在这种情况下,一种经过验证的方法是使用可分离卷积。我们观察到,在UNet的深层部分用轻量级的可分离卷积层替换常规卷积层可以产生类似的性能。
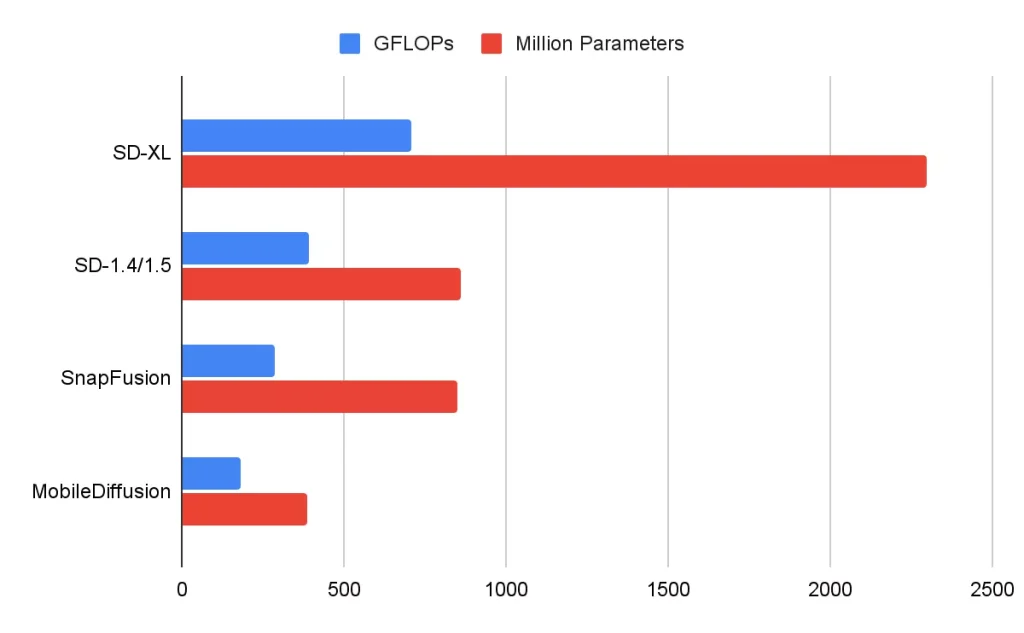
在下图中,我们比较了几个扩散模型的UNet。我们的MobileDiffusion在浮点运算(FLOPs)和参数数量方面表现出了更高的效率。
图像解码器(Image decoder)
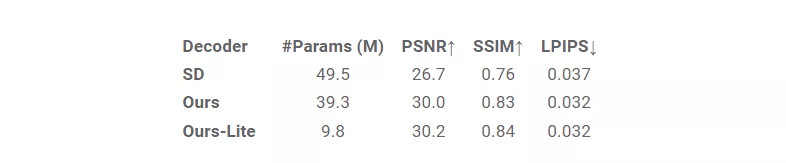
除了UNet之外,我们还优化了图像解码器。我们训练了一个变分自编码器(VAE)来将RGB图像编码为一个8通道的潜在变量,其空间大小是图像的1/8。潜在变量可以被解码为图像,并在大小上扩大8倍。为了进一步提高效率,我们通过修剪原始解码器的宽度和深度来设计了一个轻量级解码器架构。由此产生的轻量级解码器带来了显著的性能提升,延迟减少了近50%,并且图像质量也有所提高。更多细节,请参考我们的论文。

一步采样(One-step sampling)
除了优化模型架构,我们还采用了DiffusionGAN混合模型来实现一步采样。训练用于文生图的DiffusionGAN混合模型遇到了几个复杂问题。特别是,判别器(一个区分真实数据和生成数据的分类器)必须基于纹理和语义做出判断。此外,训练文本到图像模型的成本可能非常高,特别是在基于GAN的模型中,判别器引入了额外的参数。纯粹基于GAN的文本到图像模型(例如,StyleGAN-T,GigaGAN)面临类似的复杂性,导致训练过程高度复杂且成本高昂。
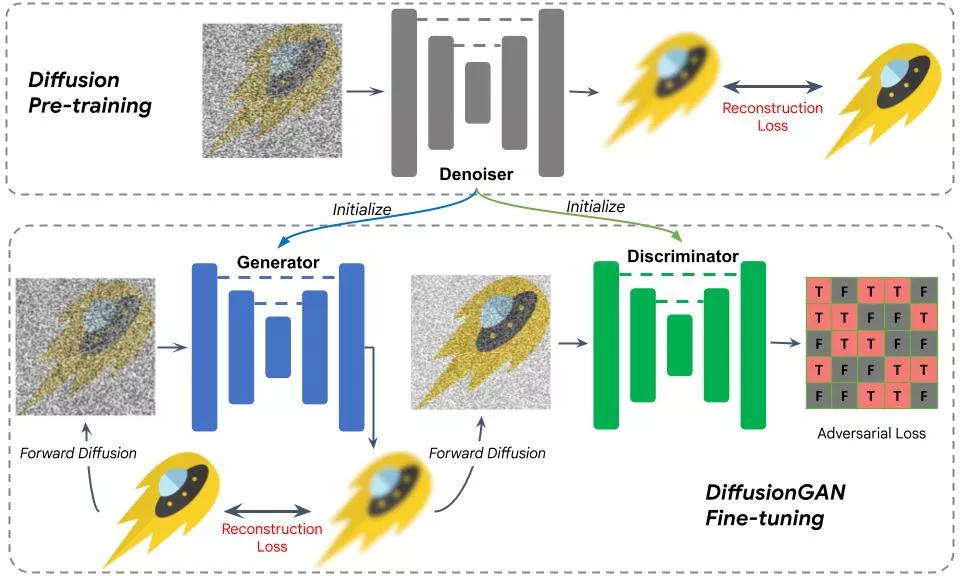
为了克服这些挑战,我们使用预训练的扩散UNet来初始化生成器和判别器。这种设计使得可以无缝初始化预训练的扩散模型。我们假设扩散模型内部特征包含了文本和视觉数据之间复杂交互的丰富信息。这种初始化策略显著简化了训练过程。
下图展示了训练过程。初始化后,将一个噪声图像发送到生成器进行一步扩散。结果与真实图像进行比较,使用重建损失,这与扩散模型训练类似。然后我们对输出添加噪声并将其发送到判别器,判别器的结果使用GAN损失进行评估,有效地采用GAN来模拟去噪步骤。通过使用预训练权重来初始化生成器和鉴别器,训练变成了一个微调过程,收敛在不到10,000次迭代内。
结果
下面我们展示了由我们的MobileDiffusion通过DiffusionGAN一步采样生成的示例图像。这样一个紧凑的模型(总共520M参数),MobileDiffusion可以为各种领域生成高质量多样化的图像。

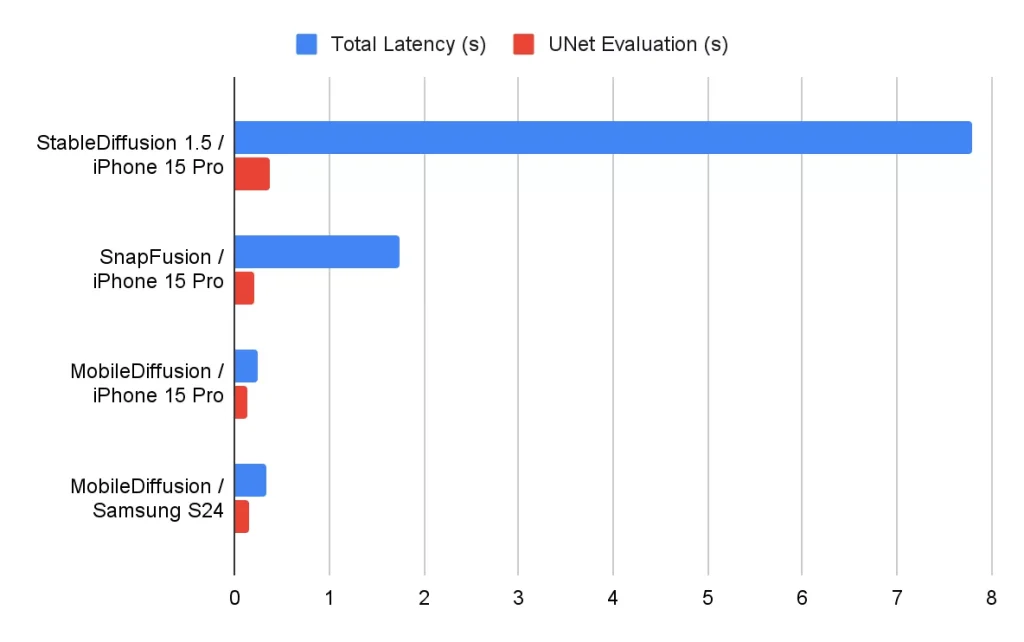
我们使用不同的运行时优化器,在iOS和Android设备上测试了MobileDiffusion的性能。报告的延迟时间如下所示。MobileDiffusion展现出极高的效率,能够在半秒内生成一张512x512的图像。这种快速的生成速度潜在地为移动设备上许多有趣的应用场景提供了可能。
结论
MobileDiffusion在延迟和大小方面的高效性能,使其成为移动部署的理想选择,尤其是实时生图能力方面。我们将确保这项技术的应用与谷歌的负责任AI实践保持一致。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











