
清华大学和加州大学伯克利分校的研究人员推出高效稀疏注意力机制SpargeAttn,旨在加速大模型的推理过程,同时不损失模型性能。注意力机制在现代深度学习模型中扮演着重要角色,但由于其计算复杂度与序列长度呈二次关系,因此在处理长序列(如语言、图像和视频生成任务)时会显著增加计算负担。SpargeAttn 通过利用注意力图的稀疏性(即许多注意力值接近于零),跳过不必要的计算,从而实现高效加速。
以视频生成任务为例,现代视频生成模型(如 CogvideoX)需要处理长达数万甚至数十万帧的序列。在这种情况下,传统的全注意力机制会导致巨大的计算开销。SpargeAttn 通过智能地跳过不重要的注意力计算,显著减少了计算量,同时保持生成视频的质量。

主要功能
- 加速模型推理:通过稀疏化注意力计算,减少不必要的矩阵乘法操作,从而显著提高模型的推理速度。
- 保持模型性能:在加速的同时,确保模型的输出质量不受影响,即在各种任务中保持与全注意力机制相同的性能指标。
- 通用性:SpargeAttn 适用于多种模型和任务,包括语言生成、图像生成和视频生成等,不受限于特定的模型结构或任务类型。
主要特点
- 两阶段在线过滤机制:
- 第一阶段:通过快速准确预测注意力图,跳过部分矩阵乘法计算。
- 第二阶段:设计了一个在线 Softmax 感知过滤器,进一步跳过部分矩阵乘法,且不增加额外开销。
- 稀疏掩码动态生成:基于输入数据的自相似性动态生成稀疏掩码,无需预设模式或额外训练。
- 与量化技术结合:SpargeAttn 集成了 8 位量化技术(如 SageAttention),进一步提升计算效率。
- 希尔伯特曲线排列:通过希尔伯特曲线对输入数据进行排列,增强局部相似性,从而提高稀疏性。
工作原理
- 稀疏块预测:
- 计算查询(Q)和键(K)矩阵的块内自相似性。
- 对于高度自相似的块,将其压缩为单个代表性标记。
- 通过压缩后的 Q 和 K 计算稀疏注意力图,选择高置信度的块进行计算,其余块跳过。
- 在线 Softmax 感知过滤:
- 在 FlashAttention 的在线 Softmax 过程中,动态判断某些注意力值是否足够小,从而跳过后续的矩阵乘法。
- 希尔伯特曲线排列:
- 对于图像和视频数据,使用希尔伯特曲线重新排列输入标记,以增强局部相似性,从而提高稀疏性。
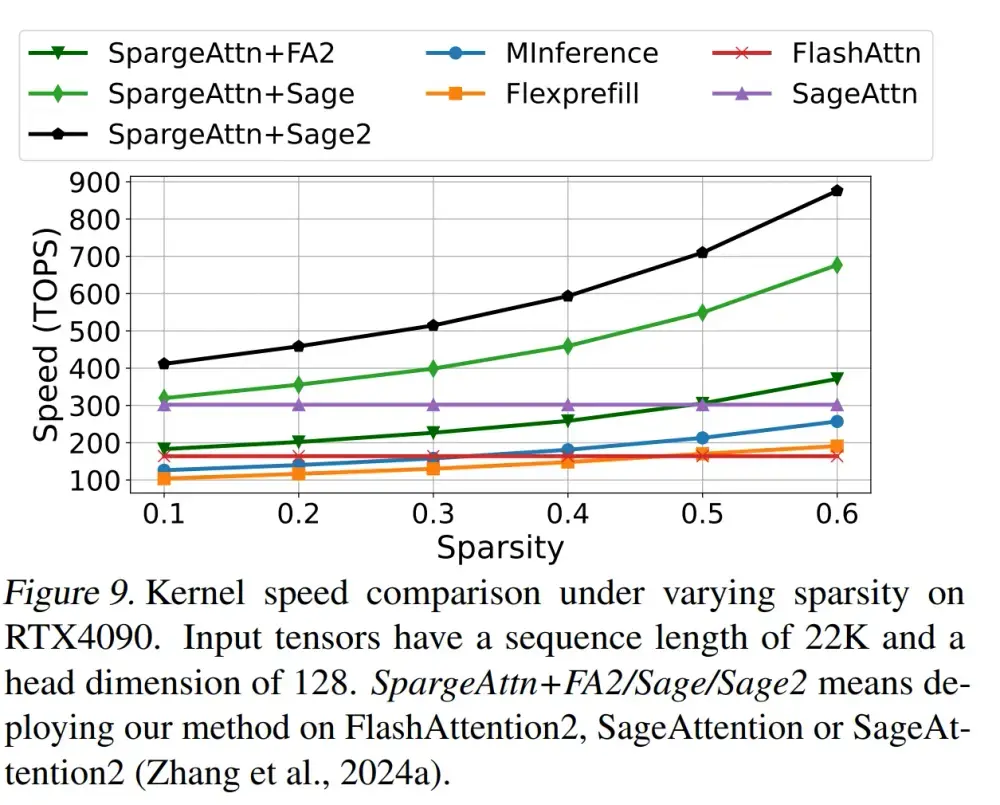
具体应用场景
- 语言生成:在长文本生成任务中,SpargeAttn 可以显著加速模型推理,同时保持生成文本的质量。
- 图像生成:在基于扩散模型的图像生成任务(如 Stable Diffusion 3.5)中,SpargeAttn 可以加速生成过程,同时保持生成图像的保真度和对齐度。
- 视频生成:在视频生成任务(如 CogvideoX)中,SpargeAttn 可以加速长视频序列的生成,同时保持视频质量和时间一致性。
- 多模态任务:在涉及文本、图像和视频的多模态任务中,SpargeAttn 可以高效处理跨模态的注意力计算,提升整体性能。
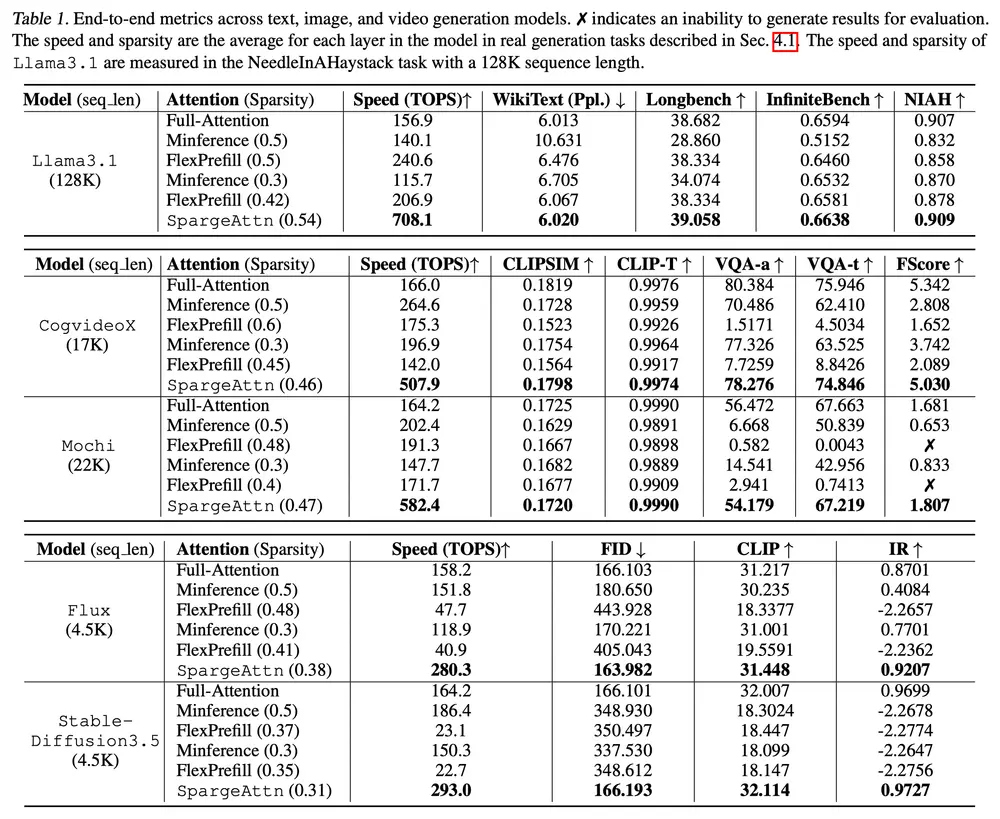
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











