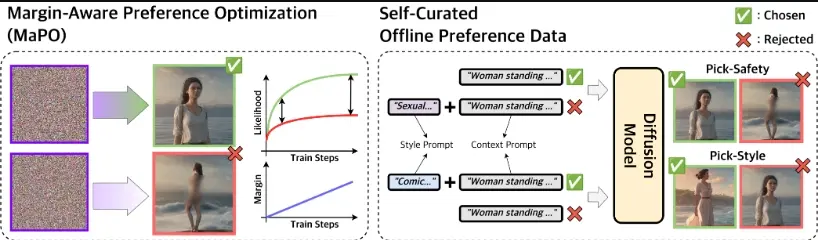
韩国科学技术研究院、Huggingface和高丽大学的研究人员推出一种新的文本到图像扩散模型的偏好优化方法,这种方法被称为“边界感知偏好优化”(Margin-aware Preference Optimization,简称MaPO)。这种方法的目的是让计算机在学习生成图像时,能够更好地符合人类的偏好。
- 项目主页:https://mapo-t2i.github.io
- GitHub:https://github.com/mapo-t2i/mapo
- 模型:https://huggingface.co/mapo-t2i
MaPO同时最大化偏好图像集合与非偏好图像集合之间的似然边际以及偏好集合的似然,同步学习一般风格特征和偏好。为了评估,开发人员引入了两个新的成对偏好数据集——Pick-Style和Pick-Safety,这些数据集由SDXL自动生成的图像对组成,模拟了多种参考不匹配的场景。实验结果证实,MaPO能显著改善在Pick-Style和Pick-Safety上的对齐效果,以及当与Pick-a-Pic v2结合使用时的一般偏好对齐能力,超越了基础SDXL和其他现有方法。这一方法为处理视觉模态下复杂且多样化的偏好表达提供了有效途径,特别是在没有明确参考模型或存在显著分布差异的情况下。

例如,你有一个魔法画笔,它可以从你的文字描述中创造出图像。但是,有时候这个魔法画笔画出来的东西可能不是你想要的风格,比如你想要一个卡通风格的图像,但画出来的却非常写实。MaPO就是用来教会这个魔法画笔如何更好地理解你想要的风格,并画出符合你偏好的图像。
主要功能:
- 偏好对齐:让生成的图像风格和内容更符合人类的偏好。
- 无需参考模型:与以往需要一个标准模型作为参考的方法不同,MaPO不需要这样的参考。
主要特点:
- 边界感知:MaPO通过优化所谓的“偏好边界”,即在生成的图像和不受欢迎的图像之间建立一个清晰的界限。
- 数据高效:即使在只有少量偏好数据的情况下也能工作得很好。
- 记忆友好:在训练过程中对计算资源的需求较小,不需要大量的内存。
工作原理:
MaPO通过以下步骤来工作:
- 定义偏好:首先确定哪些图像特征是用户喜欢的(比如卡通风格),哪些是不喜欢的(比如过于写实)。
- 优化过程:然后,MaPO会调整它的学习过程,以增加生成符合偏好图像的概率,并减少生成不受欢迎图像的概率。
- 动态调整:在训练过程中,MaPO会动态调整,以确保生成的图像在视觉上更符合人类的期望。
具体应用场景:
- 个性化艺术创作:用户可以根据自己的偏好生成独特的艺术作品。
- 游戏和电影制作:在这些领域中,可以根据剧本或概念艺术生成场景和角色的视觉图像。
- 广告和营销:生成吸引目标受众的图像,以提高广告的吸引力。
- 社交媒体:用户可以生成符合自己风格的图像用于社交媒体分享。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...