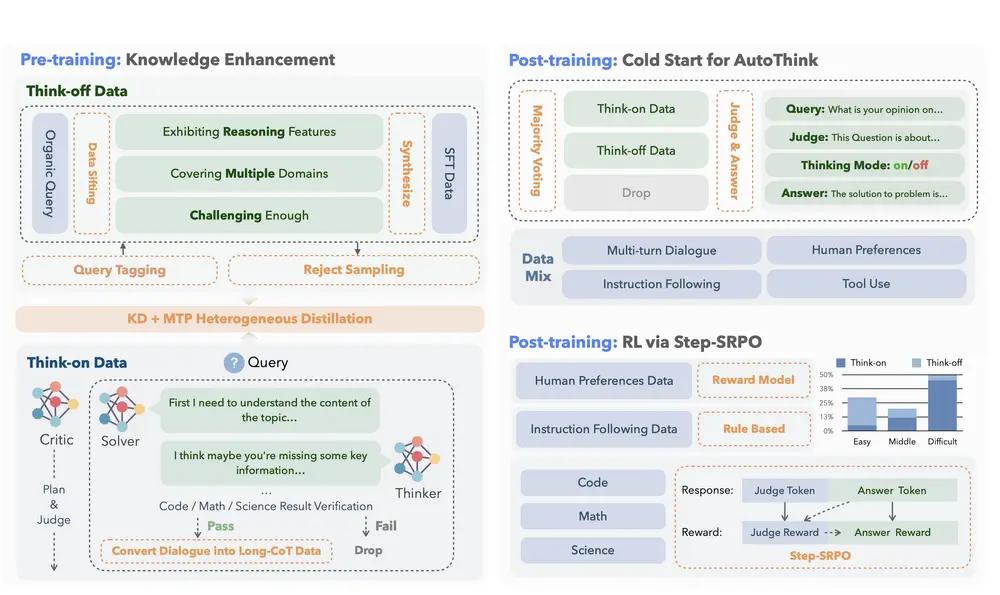
本周,微软发布了全新的大语言模型家族——BitNet b1.58 LLM。这一系列模型采用了创新的1-bit架构,参数规模达到20亿(2B4T),是迄今为止最大的开源1-bit模型。研究团队表示,这种新型模型不仅在内存占用和能耗上大幅优于主流Transformer架构的LLM,还特别适合在CPU或小型硬件平台上运行。
- GitHub:https://github.com/microsoft/BitNet
- 模型:https://huggingface.co/microsoft/BitNet-b1.58-2B-4T
- Demo:https://bitnet-demo.azurewebsites.net
BitNet b1.58的核心优势在于其三值量化技术,将权重压缩为-1、0和1三个值。相比传统的16位或8位模型,这种设计显著减少了存储需求和计算复杂度,同时保持了与全精度(FP16)模型相当的任务性能。
BitNet b1.58的实际表现如何?
在多项基准测试中,BitNet b1.58的表现令人瞩目。例如,在GSM8K(小学数学问题集)和PIQA(物理常识推理能力测试)中,该模型的表现优于Meta的Llama 3.2 1B、Google的Gemma 3 1B以及阿里巴巴的Qwen 2.5 1.5B等主流模型。
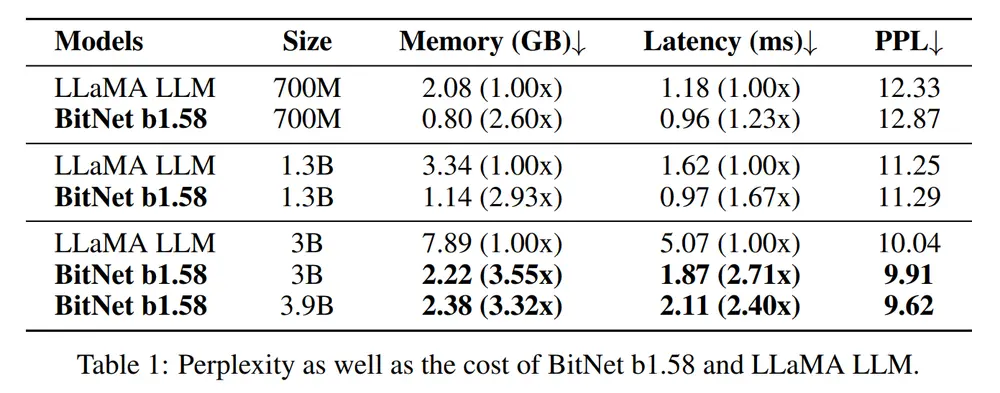
此外,研究团队还对不同版本的BitNet b1.58进行了详细的性能对比。以BitNet b1.58-3B/3.9B为例:
内存占用:分别为2.22GB和2.38GB,远低于LLaMA-3B的7.89GB。 延迟性:分别为1.87ms和2.11ms,显著优于LLaMA-3B的5.07ms。 困惑度(PPL)及零样本准确性:均优于LLaMA-3B,显示出更高的推理效率和任务适配能力。
这些数据表明,BitNet b1.58不仅在资源受限的环境中表现出色,还能在多种任务上与传统模型一较高下。
BitNet b1.58的技术原理与创新点
BitNet b1.58的核心创新在于其1-bit Transformer架构。通过将权重量化为-1、0和1,模型的存储和计算需求被极大压缩。具体而言:
三值量化:每个权重仅需1位存储空间,从而大幅减少内存占用。 BitLinear层:替代传统的 nn.Linear层,支持1-bit权重的训练,同时保持与全精度模型相当的性能。低功耗与高效推论:由于计算复杂度降低,模型在CPU等低功耗设备上的运行效率显著提升。
研究团队指出,BitNet b1.58的训练过程基于4兆字词的数据集,具备4096 token的上下文长度(context length)。尽管参数量仅为20亿,但其性能已经能够媲美甚至超越某些更大规模的模型。
为什么BitNet b1.58更适合边缘设备?
随着AI应用逐渐向边缘计算和移动设备扩展,传统的Transformer模型因高内存占用和高能耗而面临挑战。而BitNet b1.58的设计正是为了解决这些问题:
更低的内存需求:得益于三值量化技术,BitNet b1.58可以在低端硬件上运行,例如苹果M2处理器或其他消费级CPU。 更少的能源消耗:高效的计算方式使其成为边缘设备的理想选择,例如智能音箱、物联网设备或嵌入式系统。 快速推论:官方提供的C++实现版本(bitnet.cpp)进一步优化了推论速度,使得模型在实际部署中表现出色。
然而,研究团队也提醒开发者,当前流行的Transformers库并未针对BitNet进行高度优化,因此直接使用现有框架可能无法完全体现其性能优势。若想体验论文中提到的低功耗和高效推论,建议使用官方提供的C++实现版本。
开源
微软已通过Hugging Face开源了三个版本的BitNet b1.58模型权重:
BitNet b1.58 2B4T:适合模型部署。 BitNet-b1.58-2B-4T-bf16:仅适用于模型训练或微调。 BitNet-b1.58-2B-4T-gguf:包含GGUF格式权重,兼容bitnet.cpp库用于CPU推论。
研究团队相信,1-bit模型的出现将推动新一代硬件和系统的开发,进一步优化AI模型在边缘设备上的表现。未来,BitNet b1.58可能会成为低功耗AI应用的重要基石。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











