
近日,苹果与香港的研究团队联合提出了一种全新的基于扩散机制的大语言模型(Diffusion Large Language Model, dLLM)——DiffuCoder,专为代码生成任务设计。
该模型基于掩码扩散模型(Masked Diffusion Models, MDMs),并引入一种新型强化学习训练策略 Coupled-GRPO,显著提升了代码生成的质量与多样性。
此次苹果释出了3个DiffuCoder-7B模型:
- DiffuCoder-7B-Base (基座模型)
- DiffuCoder-7B-Instruct (后训练模型)
- DiffuCoder-7B-cpGRPO (cpGRPO 优化模型)
这些模型都是基于 Qwen2.5-Coder-7B 魔改的
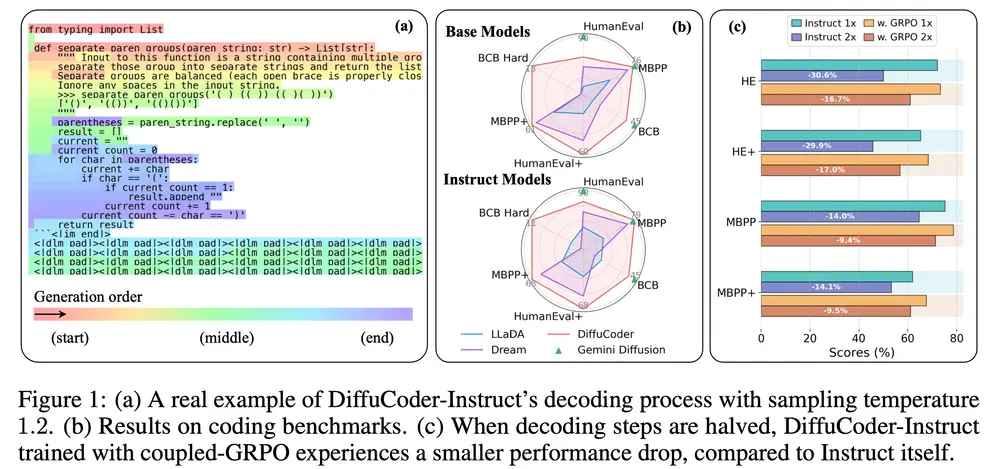
背景:dLLM 与代码生成
近年来,扩散大语言模型(dLLMs)如 LLaDA 和 Dream,在多个自然语言任务中已展现出可媲美自回归模型(AR)的表现。而近期商用级模型如 Mercury 和 Gemini,也进一步验证了扩散模型在编程任务中的潜力。
尽管如此,dLLMs 在代码生成领域的生成模式与后训练策略仍未被充分探索。本研究围绕以下几个核心问题展开:
- dLLMs 的生成模式与 AR 模型有何不同?
- 编程任务与数学任务在建模上有哪些差异?
- 如何提升 dLLMs 的生成多样性,并优化其训练方式?
为此,研究人员基于 DiffuLLaMA 的适配方法,训练出 DiffuCoder,并提出新指标 自回归得分(Autoregressiveness Score) 来量化 dLLM 的因果性特征。

主要发现
- 生成模式差异:dLLMs 尽管仍表现出一定的“从左到右”倾向,但能够打破传统 AR 模型的严格顺序限制。
- 任务特性差异:在预训练阶段,代码任务比数学任务表现出更低的全局自回归性(AR-ness)。
- 采样机制影响:改变采样温度不仅影响 token 的选择,还会改变整个生成顺序本身。
Coupled-GRPO:强化学习训练策略
在扩散模型中,每个时间步的损失 $ L_t $ 通常只在被掩码的 token 上计算,导致估计方差较大、效率较低。
为此,研究团队提出 Coupled-GRPO,通过以下机制提升训练效果:
核心思想:耦合采样策略
- 对于每个样本,选取一对时间步 $ (t, t') $,满足 $ t + t' = T $;
- 使用两种互补的 token 掩码方式,确保每个目标 token 在两次前向传播中恰好被揭开一次。
优势:
- 每个 token 至少获得一次非零梯度信号;
- 在部分掩码的上下文中评估 token,提高概率估计准确性;
- 仅需 $ 2\lambda $ 次采样($ \lambda = 1 $),即可实现更高精度估计,代价可控。
该方法已在开源项目 open-r1 中实现。
主要功能
DiffuCoder 的核心能力是根据自然语言指令生成高质量代码,适用于多种编程场景,包括但不限于:
- 函数定义与逻辑实现
- 数据结构操作
- 算法实现
- 代码补全与修复
主要特点
| 特性 | 描述 |
|---|---|
| 非自回归生成 | 不依赖逐词生成,而是对整个序列进行并行迭代细化,提升效率。 |
| 全局规划能力 | 在生成过程中具备整体代码结构意识,更擅长处理复杂逻辑。 |
| 强化学习优化 | 引入 Coupled-GRPO 方法,降低 token 概率估计方差,提升生成质量。 |
工作原理
DiffuCoder 基于扩散模型的基本流程构建:
- 前向过程:将原始代码逐步加噪,直至完全随机;
- 后向过程:从噪声中逐步恢复原始代码;
- 训练目标:最小化重建误差,使模型学会“去噪”并生成正确代码。
此外,结合 Coupled-GRPO 训练策略,模型能够在训练中更好地探索多样路径,从而提升最终生成质量。
📊 性能测试结果
DiffuCoder 在多个代码生成基准测试中表现优异:
| 测试集 | 提升幅度 |
|---|---|
| EvalPlus | +4.4% |
| HumanEval | 显著优于基线 |
| MBPP | 生成准确率大幅提升 |
这些结果表明,DiffuCoder 在保持非自回归优势的同时,具备生成高质量、语义正确的代码的能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











