Voyage AI 正式推出 Voyage 4 系列文本嵌入模型,带来两项行业首创技术:统一的共享嵌入空间 与 首个生产级 MoE(专家混合)嵌入模型。这一系列不仅在检索精度上树立新标杆,更通过灵活的模型组合策略,显著降低企业级应用的长期成本。
无论你是构建 RAG 系统、智能体记忆库,还是高并发语义搜索服务,Voyage 4 都提供了前所未有的灵活性与性价比。
四款模型,一套嵌入空间
Voyage 4 系列包含四个版本,全部生成兼容的嵌入向量,可在同一向量空间中互操作:
| 模型 | 定位 | 特点 |
|---|---|---|
voyage-4-large | 旗舰版 | 首个 MoE 架构嵌入模型,精度最高,服务成本比同类稠密模型低 40% |
voyage-4 | 平衡版 | 接近 voyage-3-large 的精度,保持中等规模效率 |
voyage-4-lite | 轻量版 | 精度媲美 voyage-3.5,参数更少,成本更低 |
voyage-4-nano | 开源版 | Apache 2.0 许可,免费发布于 Hugging Face,适合本地开发与原型验证 |
✅ 所有模型支持 256/512/1024/2048 维套娃式嵌入(MRL) 和 多种量化格式(FP32、INT8、二值化),可大幅压缩向量数据库存储与计算开销。
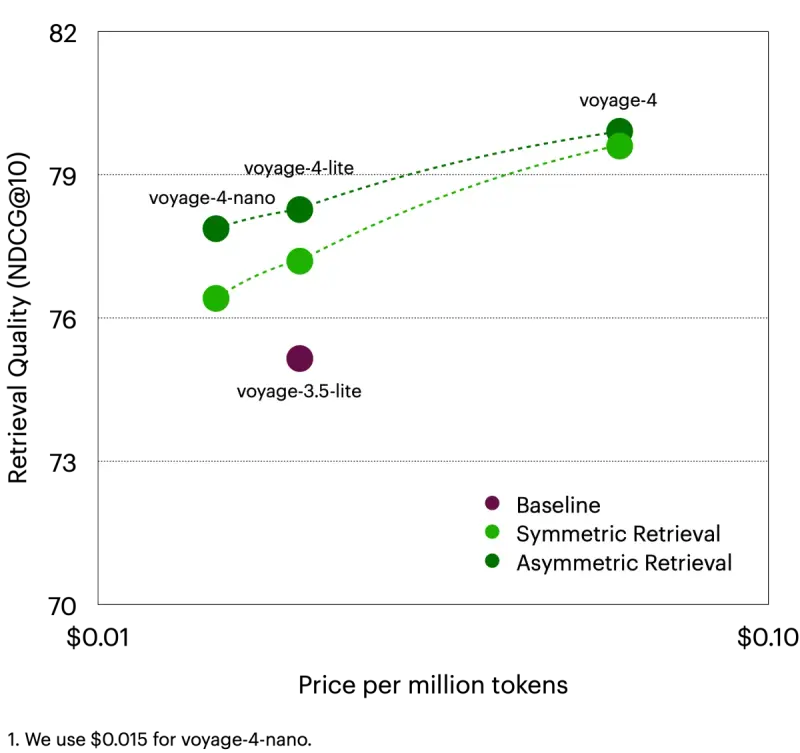
行业首创:共享嵌入空间 + 非对称检索
这是 Voyage 4 最具突破性的设计——不同模型生成的查询与文档嵌入可直接匹配。
例如:
- 用
voyage-4-large对整个文档库做一次高精度向量化(一次性成本) - 用
voyage-4-nano或voyage-4-lite实时处理用户查询(持续低成本)
这种 “非对称检索” 模式特别适合生产环境:
- 文档更新频率低 → 用大模型保证表示质量
- 查询流量高 → 用小模型控制延迟与费用
无需重新索引文档,即可随时升级查询模型,实现“精度-成本”动态平衡。
技术亮点:MoE 架构首次用于嵌入模型
voyage-4-large 是全球首个采用 专家混合(Mixture of Experts, MoE)架构 的生产级嵌入模型。它在推理时仅激活部分参数子集,从而:
- 达到当前最高的检索精度(在 29 个基准数据集上平均领先 OpenAI v3 Large 14.05%)
- 服务成本比同等稠密模型低 40%
- 保持高吞吐,适合高并发场景
这意味着你不再需要在“精度”和“成本”之间做痛苦取舍。
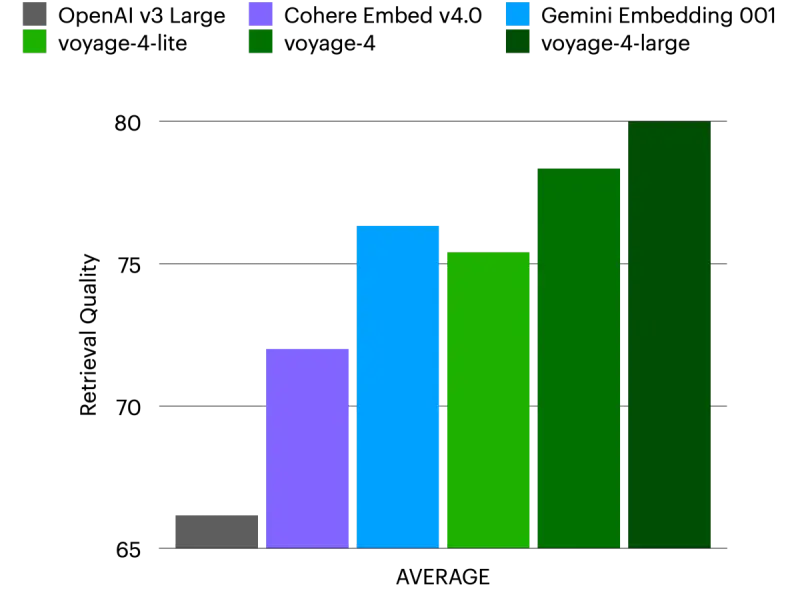
性能表现:全面超越主流竞品
在涵盖 医疗、法律、代码、金融、技术文档等 8 大领域的评估中:
- 通用检索:
voyage-4-large平均 NDCG@10 领先- Cohere Embed v4:+8.20%
- OpenAI text-embedding-v3-large:+14.05%
- 非对称检索:即使查询端使用轻量模型,精度仍显著优于对称方案
注:评估基于标准余弦相似度 + NDCG@10 指标,确保结果可复现、可比对。
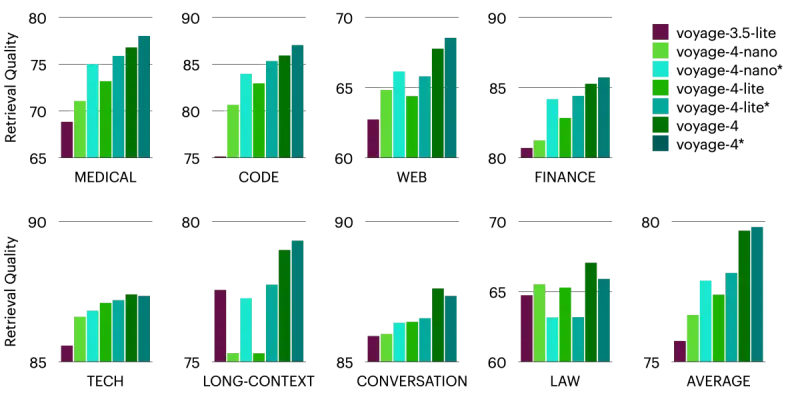
如何开始使用?
- 云端 API:
voyage-4-large/voyage-4/voyage-4-lite已上线 Voyage API,前 2 亿 tokens 免费。MongoDB Atlas 用户可通过 Atlas 嵌入与重排 API 直接调用。 - 本地开源:
voyage-4-nano已发布至 Hugging Face,Apache 2.0 许可,支持私有部署,欢迎社区贡献。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











