想象一个不仅能快速回答问题,还能像人类一样逐步思考、自我反思、甚至中途改变主意的人工智能。这不是科幻场景,而是 Dhanishtha-2.0 带来的现实。
这款由 HelpingAI 团队开发 的新一代因果语言模型,是世界上首个具备“中间思维(Intermediate Thinking)”能力的 AI 模型,它能在生成响应的过程中多次暂停、重新评估并改进自己的推理路径。
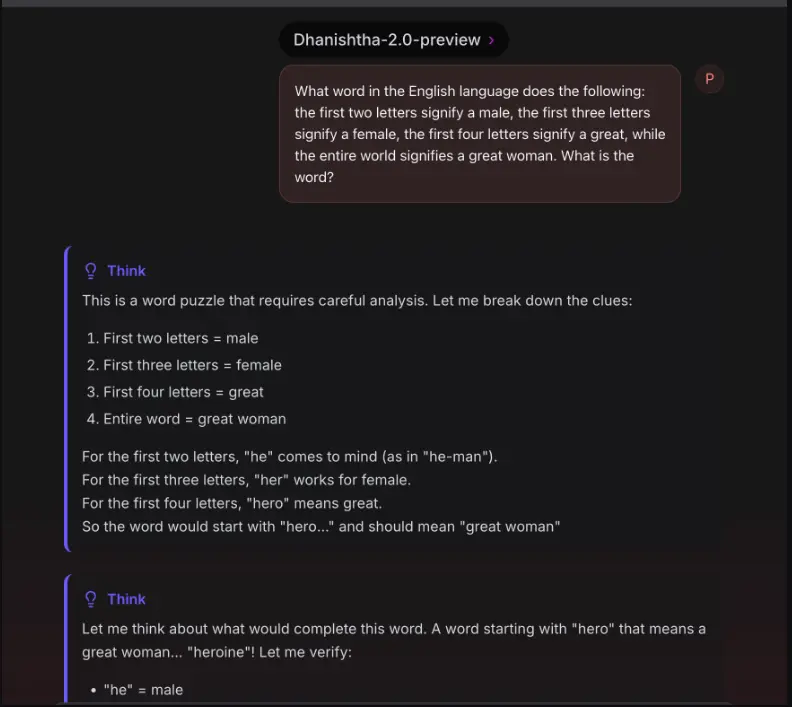
为什么 Dhanishtha-2.0 如此特别?
✅ 对普通用户而言:
- 它能展示完整的思考过程,不再只是“直接给出答案”。
- 在意识到更好的方法时,它可以中途调整思路,提升回答的准确性和逻辑性。
✅ 对开发者而言:
- 首个支持多阶段推理的模型;
- 支持 39 种以上语言,覆盖广泛的语言生态;
- 可用于构建需要深度理解、推理和解释的应用系统。
模型概览
| 属性 | 内容 |
|---|---|
| 模型名称 | Dhanishtha-2.0 |
| 开发者 | HelpingAI 团队 |
| 基础模型 | 微调自 Qwen/Qwen3-14B-Base |
| 参数规模 | 140 亿(继承自基础模型) |
| 上下文长度 | 40,960 tokens |
| 语言支持 | 39+ 种语言(多语言能力来自基础模型) |
| 许可证 | Apache 2.0 |
| 模型类型 | 具备“中间思维”能力的因果语言模型 |
| 状态 | 原型/预览版 |
核心创新功能
1️⃣ 中间思维机制(Intermediate Thinking)
这是 Dhanishtha-2.0 最核心的突破:在一次输出中嵌入多个推理步骤块 <think>...</think>,实现多轮推理、暂停、重思和重构。这种能力让 AI 更接近人类解决问题的方式。
2️⃣ 自我纠正能力
模型能够在生成过程中识别自身逻辑中的不一致,并主动修正错误,从而提供更加可靠的回答。
3️⃣ 动态推理流程
从分析、沟通到反思,Dhanishtha-2.0 能够在不同推理阶段之间灵活切换,适应复杂任务的需求。
4️⃣ 结构化情感推理(SER)
通过 <ser>...</ser> 标记,模型可生成具有同理心和情绪感知的回应,适用于客服、教育、心理辅助等场景。
5️⃣ 多语言与代码推理一致性
支持 39 种以上语言,同时具备自然语言与代码之间的无缝推理能力,适用于多语言编程环境和跨文化交互应用。
6️⃣ 复杂问题解决能力
尤其擅长处理需要回溯、多步推理的问题,如数学难题、谜题、哲学讨论等。
🛠 应用场景
✅ 直接使用场景:
- 复杂问题求解:如科学问题、逻辑推理、多步骤数学计算。
- 教育辅助:帮助学生理解解题过程,而不仅仅是结果。
- 研究支持:为认知科学、AI 教学、推理模型研究提供新工具。
- 创意写作与哲学对话:展现 AI 的多维度表达能力。
✅ 下游定制应用场景:
- 特定领域推理优化:如医学、法律、工程等领域微调。
- 增强型多语言推理:针对非英语用户的深度本地化推理需求。
- 特定问题建模:如考试辅导、个性化学习路径生成等。
⚠️ 不适用场景:
- 安全关键型决策(如医疗诊断、金融风控)
- 实时性要求极高的系统响应
- 需要未经推理过程保证事实准确性的任务
⚠️ 限制与潜在风险
| 类别 | 描述 |
|---|---|
| 性能限制 | 多阶段推理可能使响应变慢,推理块会额外消耗上下文 token。 |
| 原型状态 | 当前仍处于实验阶段,部分功能需持续优化。 |
| 偏见与偏差 | 可能反映基础模型及训练数据中的偏见。 |
| 潜在风险 |
- 在复杂情境中可能出现循环推理;
- 不同语言间的推理表现可能存在差异;
- 情感推理模块可能无法始终贴合实际语境。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











