艾伦人工智能研究所(AI2)发布了 Olmo 3.1,这是 Olmo 3 系列的最新迭代。此次更新包含两个 32B 参数的新模型检查点,以及多个 7B 规模的强化学习变体,进一步推动了高性能与全开源的统一。

核心模型更新
1. Olmo 3.1 Think 32B
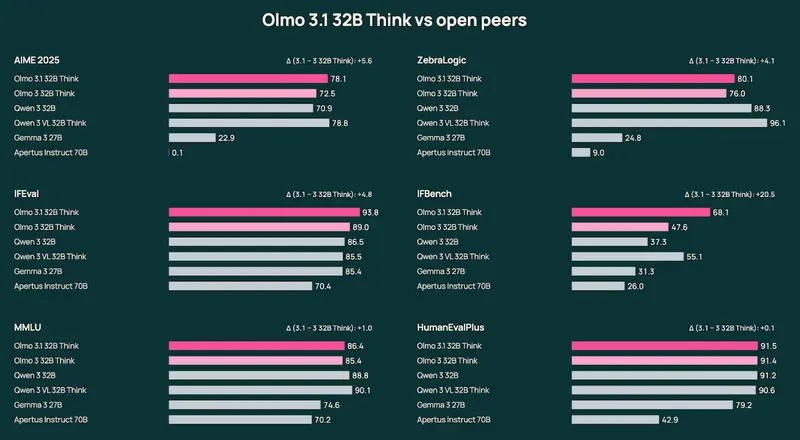
基于 Olmo 3 32B Think 的强化学习(RL)训练,团队在 224 个 GPU 上额外训练 21 天,使用扩展版 Dolci-Think-RL 数据集进行多轮优化。
性能提升显著:
- AIME(数学推理):+5+ 分
- ZebraLogic(逻辑推理):+4+ 分
- IFEval(指令遵循):+4+ 分
- IFBench(多步骤任务):+20+ 分
同时在代码生成与复杂任务规划上表现更强。
2. Olmo 3.1 Instruct 32B
将此前成功应用于 Olmo 3 Instruct 7B 的指令微调方法扩展至 32B 规模。
该模型专为多轮对话、工具调用和通用聊天场景设计,是 AI2 目前能力最强的完全开源聊天模型,也是当前最强大的开源 32B 指令微调模型之一。
所有模型均遵循 Olmo 的开源承诺:训练数据、代码、超参数和评估结果全部公开。
其他更新:7B 强化学习基线
为支持强化学习研究,AI2 同时发布了两个 RL-Zero 的改进版本:
- Olmo 3.1 RL Zero 7B Code
- Olmo 3.1 RL Zero 7B Math
这些模型基于更长、更稳定的训练流程,为 RL 算法研究提供了更强的基线,并推动了可复现的 RL 训练实践。

开源与可用性
所有 Olmo 3.1 模型均以 Apache 2.0 许可证开源,可通过以下方式获取:
- Hugging Face:https://huggingface.co/collections/allenai/olmo-3
- AI2 Playground:在线试用(含交互式推理)
- API 接入:通过 AI2 合作推理平台调用(如 Fireworks、Together 等)
为什么 Olmo 3.1 值得关注?
- 性能与开放性并重
在不牺牲透明度的前提下,通过延长训练、优化 RL 策略,显著提升模型能力。 - 端到端可复现
从预训练数据(Dolma)、训练代码(OpenTrain)到评估脚本,全部公开,支持社区验证与改进。 - 明确的能力分工
- Think 系列:面向推理、规划、代码等复杂任务;
- Instruct 系列:面向对话、工具使用等交互场景。
- 推动 RL 研究
RL-Zero 变体为学术界提供了高质量、可扩展的强化学习基线。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...