在 Gemini 3 引发广泛关注的同时,谷歌悄然推出了一款面向边缘设备的专用小模型——FunctionGemma。它不是另一个聊天机器人,而是一个能在手机、浏览器或 IoT 设备上本地运行的“行动引擎”:将自然语言指令直接转化为可执行的结构化函数调用,全程无需联网。

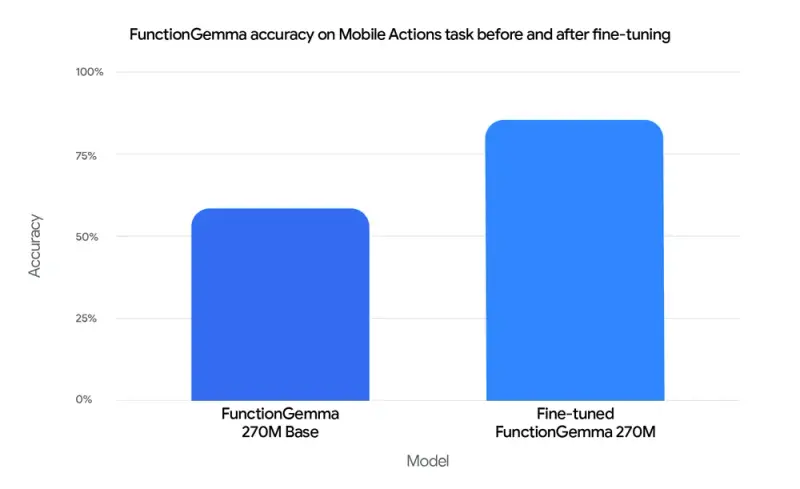
FunctionGemma 基于 Gemma 3 270M 架构微调而来,参数量仅 2.7 亿,却在函数调用任务上达到 85% 的准确率(通用小模型基线仅 58%),性能接近数倍规模的通用模型。它标志着谷歌 AI 战略的一个关键转向:从“云端大模型”到“边缘智能体”的落地路径。
为什么需要 FunctionGemma?
当前大模型擅长对话,但可靠执行软件操作仍是难题——尤其在资源受限的设备上。用户说“明天上午 10 点提醒我开会”,系统需准确解析时间、事件,并调用日历 API。这一“执行鸿沟(Execution Gap)”正是 FunctionGemma 要解决的核心问题。
与通用模型不同,FunctionGemma 专为确定性、低延迟、高可靠性设计,适用于:
- 智能家居控制(“打开客厅灯”)
- 系统操作(“开启飞行模式”)
- 应用自动化(“给 John 发消息:会议推迟到 3 点”)
- 游戏交互(“在 (3,5) 位置种植向日葵”)
技术亮点
✅ 专精微调,小而可靠
- 在 6 万亿 token 上预训练,再用 “Mobile Actions” 数据集微调
- 函数调用准确率从 58% → 85%,证明专业化优于盲目扩参
- 支持多轮逻辑解析(如“先关灯,再设闹钟”)
✅ 为边缘而生
- 模型仅 2.7 亿参数,可在 手机、NVIDIA Jetson Nano、浏览器(via Transformers.js)上实时运行
- 利用 Gemma 的 256k 词表高效处理 JSON 与多语言输入
- 延迟极低,敏感数据(如联系人、日历)永不离开设备
✅ 统一“对话”与“执行”
- 能生成结构化函数调用(如
{"function": "setAlarm", "args": {"time": "10:00"}}) - 也能切换回自然语言,向用户解释操作结果(如“已为您设置上午 10 点的闹钟”)
✅ 全栈开发者支持
- 训练:兼容 Hugging Face Transformers、Unsloth、Keras、NVIDIA NeMo
- 部署:支持 LiteRT-LM、vLLM、Llama.cpp、Ollama、MLX、Vertex AI
- 示例:提供 Colab 微调笔记本、Mobile Actions 数据集、Edge Gallery 演示 App
典型应用场景
1. 边缘“流量控制器”架构
- 在设备端部署 FunctionGemma 作为第一层
- 简单命令(媒体控制、导航)本地即时处理
- 复杂请求(如“总结这篇论文”)路由至云端大模型(如 Gemma 3 27B)
- 优势:降低 90%+ 云端调用成本,提升响应速度
2. 隐私敏感领域
- 医疗、金融、企业应用中,PII 数据无需上传
- 符合 GDPR、HIPAA 等合规要求
3. 交互式边缘体验
- TinyGarden 游戏:语音命令管理虚拟农田,模型解析网格坐标并调用
plantCrop() - 物理游乐场:在浏览器中用自然语言解谜,完全本地运行
许可与使用
FunctionGemma 采用 Gemma 定制许可证:
- ✅ 允许免费商业使用、修改、分发
- ⚠️ 禁止用于生成恶意软件、仇恨内容等“受限用途”
- ⚠️ 非 OSI 认证开源协议(不同于 MIT/Apache 2.0),企业需审慎评估合规性
对大多数开发者而言,该协议足够宽松;但对需严格著佐权的项目,建议仔细阅读条款。
如何开始?
- 下载模型:Hugging Face / Kaggle
- 体验演示:安装 Google AI Edge Gallery(Play 商店)
- 微调自己的版本:
- 使用提供的 Mobile Actions 数据集
- 参考 微调指南 适配你的 API 接口
- 部署到设备:通过 LiteRT-LM 或 Ollama 集成至移动 App
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...