快手Klear项目组推出推理模型 Klear-Reasoner,它通过结合长链推理(Long Chain-of-Thought, Long CoT)监督微调和梯度保留剪辑策略优化(Gradient-Preserving Clipping Policy Optimization, GPPO)来提升模型在数学和编程任务中的推理能力。
主要功能
Klear-Reasoner 的主要功能是解决复杂的数学和编程问题,通过长链推理和强化学习(Reinforcement Learning, RL)来优化模型的推理能力。它能够:
- 长链推理:通过监督微调(Supervised Fine-Tuning, SFT)学习高质量的推理模式。
- 强化学习:通过 GPPO 优化策略,提升模型在复杂任务中的表现。
- 高效利用数据:通过精心设计的数据策略,确保模型能够从有限的数据中学习到高质量的推理模式。
主要特点
- 长链推理监督微调:Klear-Reasoner 通过高质量的长链推理数据进行监督微调,确保模型能够学习到准确的推理模式。
- 梯度保留剪辑策略优化:通过 GPPO,Klear-Reasoner 能够在训练过程中保留被剪辑的梯度信息,从而在保持训练稳定性的同时,提升模型的探索能力。
- 数据策略:Klear-Reasoner 优先使用高质量的数据源,而不是依赖大量多样化的数据源,从而提高模型的推理能力。
- 强化学习中的软奖励机制:在代码任务中,Klear-Reasoner 采用基于测试用例通过率的软奖励机制,缓解了奖励稀疏性问题,提高了模型的学习效率。
工作原理
Klear-Reasoner 的工作原理可以分为以下几个步骤:
- 长链推理监督微调:使用高质量的长链推理数据对模型进行监督微调,确保模型能够学习到准确的推理模式。
- 强化学习:通过 GPPO 优化策略,Klear-Reasoner 在训练过程中能够保留被剪辑的梯度信息,从而在保持训练稳定性的同时,提升模型的探索能力。
- 数据策略:Klear-Reasoner 优先使用高质量的数据源,而不是依赖大量多样化的数据源,从而提高模型的推理能力。
- 软奖励机制:在代码任务中,Klear-Reasoner 采用基于测试用例通过率的软奖励机制,缓解了奖励稀疏性问题,提高了模型的学习效率。
测试结果
Klear-Reasoner 在多个基准测试中表现出色:
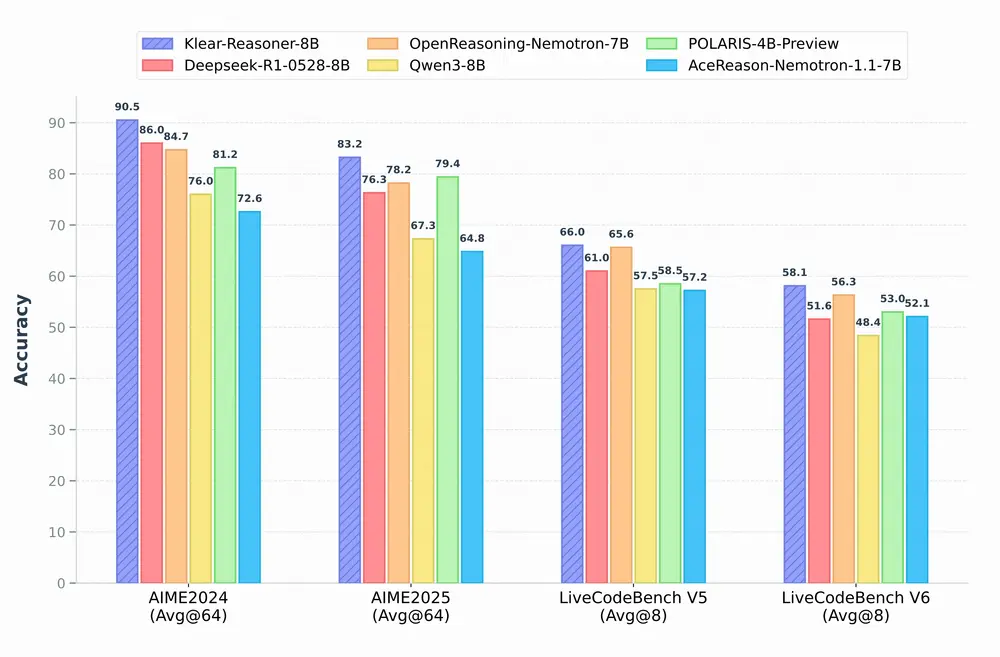
- 在 AIME 2024 和 AIME 2025 数学竞赛中,Klear-Reasoner 分别达到了 90.5% 和 83.2% 的准确率。
- 在 LiveCodeBench V5 和 LiveCodeBench V6 编程任务中,Klear-Reasoner 分别达到了 66.0% 和 58.1% 的准确率。
- 在 HMMT 2025 数学竞赛中,Klear-Reasoner 达到了 70.8% 的准确率。
这些结果表明,Klear-Reasoner 在数学和编程任务中均达到了与现有最先进模型相当甚至更高的水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...










