8 月 6 日,OpenAI 开源两款大模型,主打“低成本部署”与“医疗能力突破”。仅仅五天后,百川智能推出 Baichuan-M2 ——一款在更小参数规模下实现医疗能力反超的开源模型。
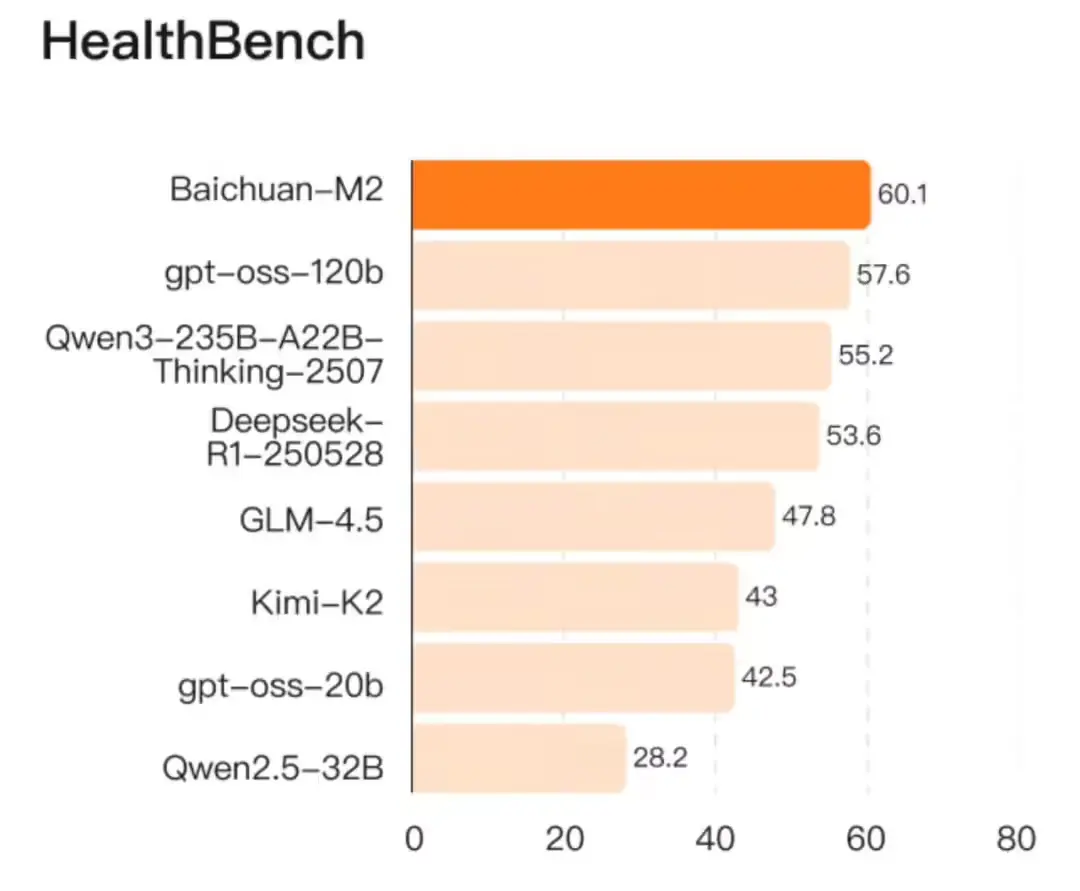
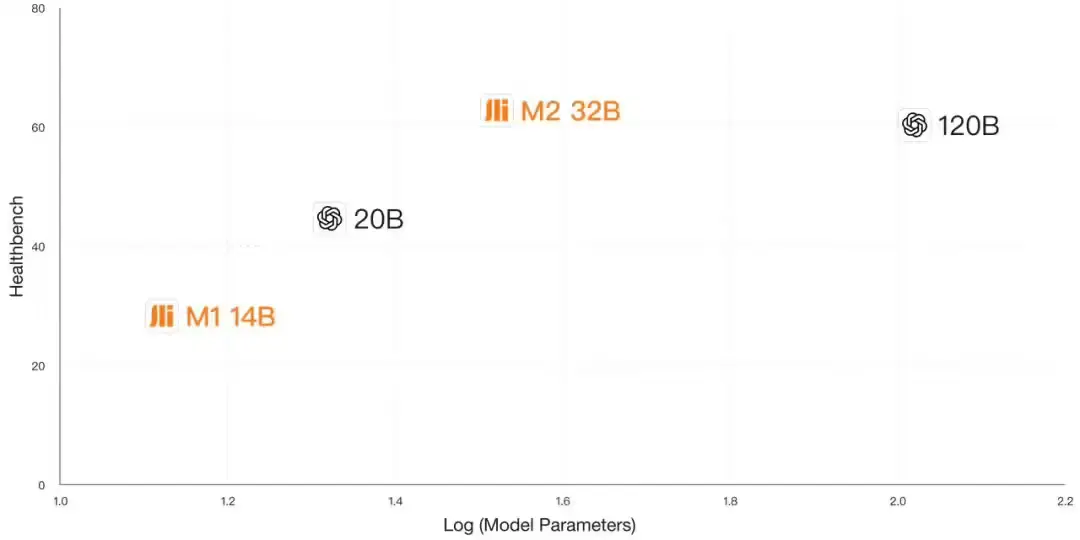
它不是简单跟进,而是一次精准突破:用 32B 参数模型,在权威医疗评测 HealthBench 上拿下 60.1 分,超越 gpt-oss120b(57.6)、Qwen3-235B、Deepseek R1、Kimi K2 等所有当前开源大模型,位列全球第一。
更关键的是,这一性能突破并未以牺牲通用能力为代价——数学、写作、指令遵循等核心能力不降反升。
Baichuan-M2 的出现,标志着开源医疗大模型正式进入“高性能+低门槛”并行的新阶段。
核心成绩:在 HealthBench 上全面领先
HealthBench 是目前最权威的开源医疗大模型评测基准,涵盖诊断推理、医学知识问答、病历理解、用药建议等多个维度。
| 模型 | HealthBench 总分 |
|---|---|
| Baichuan-M2 | 60.1 ✅ |
| gpt-oss120b(OpenAI) | 57.6 |
| Qwen3-235B | 56.8 |
| Deepseek R1 | 55.3 |
| Kimi K2 | 54.9 |
Baichuan-M2 不仅总分第一,在子项如“复杂病例分析”“多跳推理”中也表现突出。
更进一步:挑战 GPT-5 的医疗极限
OpenAI 在 GPT-5 发布时曾强调:
GPT-5 是 HealthBench Hard 评测中,全球唯一得分超过 32 分的模型。
如今,Baichuan-M2 在同一子集上取得 34.7 分,成为全球第二款突破 32 分的模型。
这意味着:在处理高难度、多步骤、需专业背景的医疗问题时,Baichuan-M2 已具备与顶尖闭源模型比肩的能力。
极致轻量化:RTX 4090 单卡部署,成本降至 1/57
医疗场景对数据隐私要求极高,私有化部署是刚需。但多数高性能模型动辄需要多卡甚至多节点集群,部署成本高昂。
Baichuan-M2 针对这一痛点进行了极致优化:
- 经过量化后,模型精度接近无损;
- 可在 RTX 4090(24GB)上单卡运行;
- 相比 DeepSeek-R1 需 H20 双节点部署方案,硬件成本降低至 1/57。
这意味着:
- 县级医院、社区诊所也能负担得起;
- 无需专用服务器,利用现有工作站即可部署;
- 更适合边缘场景和本地化应用。
同时,模型已完成对国产主流芯片(如昇腾、寒武纪)的适配,支持国产化替代。
速度优化:急诊场景下的实时交互能力
在门诊、急诊等对响应速度要求极高的场景中,延迟直接影响使用体验。
为此,百川推出了基于 Eagle-3 架构优化的 MTP 版本(Multi-Token Prediction),在单用户场景下实现:
token 生成速度提升 74.9%
这使得模型能够更快地响应医生提问,支持连续对话与实时辅助决策,真正融入临床工作流。
通用能力不降反升:医疗数据也能“反哺”通用性
一个常见担忧是:过度专业化是否会导致模型“偏科”?
百川团队通过实验证明:高质量医疗数据本身具有高信息密度和强逻辑结构,对提升模型通用能力也有显著价值。
在多个通用任务评测中,Baichuan-M2 表现如下:
| 能力 | 表现 |
|---|---|
| 数学推理 | 超越前代 Baichuan-M1,接近同级通用模型 |
| 指令遵循 | 显著提升,支持复杂多步任务 |
| 写作与摘要 | 逻辑更严密,术语使用更准确 |
这说明:医疗领域的高质量监督信号,正在成为提升大模型整体智能水平的重要路径。
适用场景:不止于问答,更面向真实医疗流程
凭借高精度、低延迟、可私有化部署的特点,Baichuan-M2 可应用于多个关键场景:
| 场景 | 应用示例 |
|---|---|
| 临床辅助决策 | 根据症状和检查结果提供鉴别诊断建议 |
| 电子病历生成 | 自动整理问诊内容,生成结构化病历 |
| 医学教育 | 为医学生提供病例解析与知识问答 |
| 患者问答系统 | 在医院公众号或App中提供智能导诊 |
| 药物信息查询 | 快速检索药品适应症、禁忌、相互作用 |
它不是一个“玩具级”医疗插件,而是一个可集成到真实业务系统中的专业级基座模型。
开源意义:推动医疗AI走向普惠
Baichuan-M2 的开源,具有三重意义:
- 打破闭源垄断:在医疗这一高壁垒领域,首次有开源模型在性能上超越主流闭源方案。
- 降低使用门槛:单卡可跑、国产芯片适配,让更多机构用得起、用得上。
- 促进生态共建:开源后,医院、高校、企业可基于其进行二次开发,共同提升医疗AI水平。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...