在 AI 搜索领域,闭源商业产品长期占据主导地位。而今天,开源社区迎来了一位强有力的挑战者——Jan-v1。
作为 Jan 模型家族的首个正式版本,Jan-v1 基于 Qwen3-4B-Thinking 架构,并针对代理式推理与工具调用进行深度微调,旨在提供一个完全本地运行、可审计、无数据外泄风险的 Perplexity Pro 开源替代方案。
它不仅能回答问题,更能主动执行网络搜索、整合信息、生成结构化回答,且整个过程无需离开你的设备。

核心定位:为“本地智能代理”而生
Jan-v1 并非一个通用聊天模型,而是专为 代理任务(Agentic Tasks) 设计的推理引擎,典型应用场景包括:
- 网络搜索与事实核查:像 Perplexity 一样,通过调用搜索引擎获取最新信息。
- 深度研究:对复杂问题进行多步查询、信息整合与逻辑推理。
其底层模型 Qwen3-4B-Thinking 支持高达 256K 上下文长度,能够处理长文档、保留推理轨迹,并在本地完成完整的“思考-搜索-验证”闭环。
技术架构与优化
Jan-v1 基于 Lucy 模型体系,通过模型扩展(model expansion)与任务微调实现性能跃升。关键特性包括:
| 特性 | 说明 |
|---|---|
| 模型基座 | Qwen3-4B-Thinking,专为推理优化 |
| 上下文长度 | 最高支持 256K,适合长文本分析 |
| 工具调用能力 | 支持 MCP(Model Context Protocol)协议,可集成 Serper 等搜索服务 |
| 本地运行 | 可在 Jan App、llama.cpp、vLLM 等主流框架中部署 |
该模型在保持 4B 级参数规模的同时,实现了接近甚至超越更大模型的推理能力,体现了“小模型、大任务”的设计哲学。
性能表现:事实性问答的新标杆
在 SimpleQA 基准测试中,Jan-v1 达到了 91.1% 的准确率,略高于 Perplexity Pro 的表现。
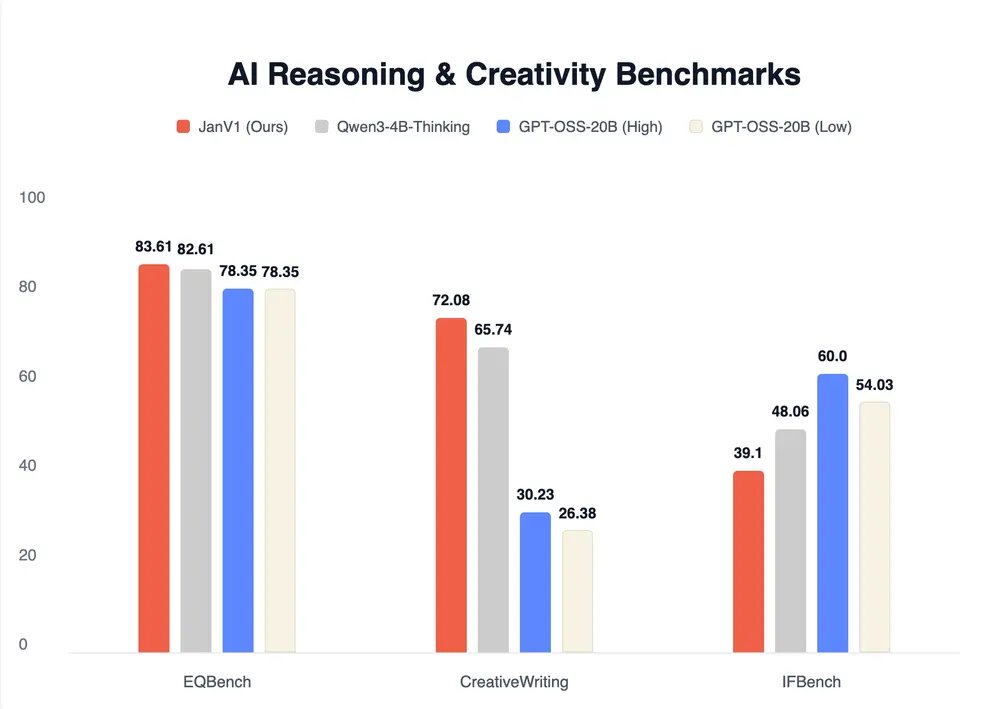
这一成绩对于一个 4B 规模的开源模型而言,标志着在事实性问答领域的重大突破。它证明了:
- 通过合理的微调与架构设计,小模型也能胜任复杂任务;
- 本地模型在信息准确性上,已具备与闭源商业产品竞争的能力。
🔍 SimpleQA 是一个评估模型事实检索与回答准确性的基准,要求模型基于真实世界知识作答,而非生成性回答。
如何使用:三步开启本地智能搜索
Jan-v1 已深度集成于 Jan App,使用流程简洁高效:
- 选择模型
在 Jan App 中选择Jan-v1作为当前模型。 - 开启实验功能
进入 设置 → 实验功能 → 开启“代理推理” - 启用 MCP 搜索服务
进入 设置 → MCP 服务器,启用与搜索相关的 MCP 服务(如 Serper)
完成配置后,你只需输入问题,例如:
“2025 年全球 AI 投资趋势有哪些?”
Jan-v1 将自动:
- 生成搜索查询
- 调用搜索引擎获取结果
- 提取关键信息
- 组织成连贯回答
全过程在本地完成,数据不上传、不记录、可审计。
为什么选择 Jan-v1?
| 优势 | 说明 |
|---|---|
| ✅ 完全本地运行 | 所有计算在用户设备完成,保护隐私与数据安全 |
| ✅ 开源透明 | 模型权重与推理流程可审查,无黑箱操作 |
| ✅ 支持主流框架 | 不仅限于 Jan App,也可在 llama.cpp、vLLM 中部署 |
| ✅ 低成本部署 | 4B 模型可在消费级 GPU 甚至高性能 CPU 上运行 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











