思科宣布其在AI领域的重大进展——推出首个由全新成立的Foundation AI团队开发的大语言模型(LLM):Llama-3.1-FoundationAI-SecurityLLM-base-8B(简称Foundation-sec-8b)。这款模型专为网络安全设计,拥有80亿参数,采用开源权重,旨在帮助安全团队更高效地应对日益复杂的威胁环境。
Foundation-sec-8b不仅是一个技术突破,更是网络安全领域AI应用的重要一步。它结合了深厚的领域专业知识与灵活的部署能力,为安全团队提供了一个强大的工具,以加速防御、减轻疲劳,并在复杂的威胁环境中保持清晰度。
为什么需要专门为安全设计的AI模型?
当前的安全团队面临着前所未有的压力。威胁增长迅速,攻击手段愈发复杂,而传统工具已无法满足需求。尽管通用AI模型正在成为一种关键力量倍增器,但它们往往缺乏针对网络安全工作流的深度优化。
通用模型的局限性:
提示和检索流程难以满足安全运营对精度、一致性和质量的要求。 微调闭源模型成本高昂,控制有限,且存在数据隐私和法规遵从性的挑战。 大多数开源模型缺乏安全团队所需的特定领域知识。
Foundation-sec-8b正是为解决这些问题而生。它从头开始设计,专注于理解和处理网络安全的语言、逻辑和工作流,填补了通用模型在专业领域的空白。
Foundation-sec-8b的核心优势
1. 深度领域对齐
Foundation-sec-8b基于Llama 3.1 8B框架构建,并在思科内部精心策划的数据集上进行了预训练。该数据集涵盖以下内容:
漏洞数据库和威胁行为映射(如CVE、CWE、MITRE ATT&CK) 威胁情报报告、红队演练手册和真实事件摘要 跨云、身份和基础设施领域的安全工具文档 合规性参考和安全开发实践(如NIST、OWASP、安全编码指南)
这种领域对齐使Foundation-sec-8b能够立即融入分析师的工作流,提供更深入的见解、更少的幻觉(hallucination),并显著缩短响应时间。
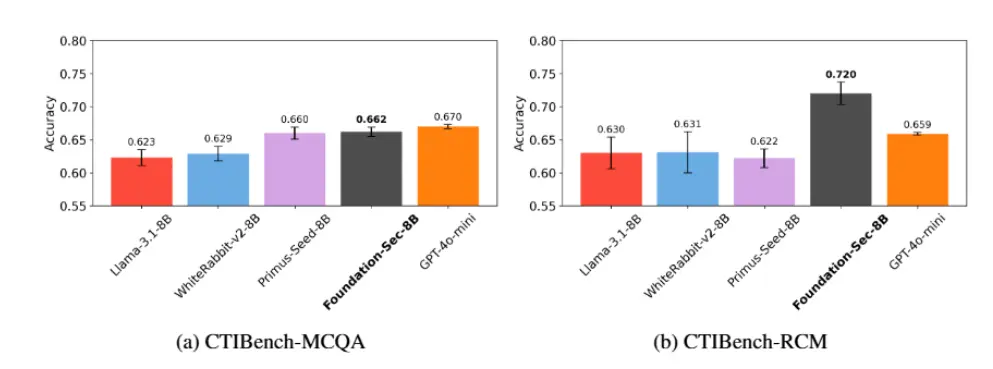
2. 表现超出其规模
尽管参数规模仅为80亿,Foundation-sec-8b的表现却可与近10倍大的模型相媲美。以下是其在核心网络安全基准测试中的表现:
| 基准测试 | Foundation-sec-8b | Llama-3.1-8b | Llama-3.1-70B |
|---|---|---|---|
| CTI-MCQA | 67.39 | 64.14 | 68.23 |
| CTI-RCM | 75.26 | 66.43 | 72.66 |
此外,Foundation-sec-8b在通用语言性能(如MMLU基准测试)中也表现优异,确保其既能流畅解释威胁行为,又能支持长篇调查叙述和自然响应。
3. 开源与灵活性
Foundation-sec-8b采用开源权重发布,赋予组织对其部署的完全控制权。这意味着:
可在本地、气隙环境或安全的云隔离区中运行模型。 敏感数据保留在本地,无需依赖推理API或第三方共享。 自由调整和扩展模型架构或训练流程,以满足独特的安全和隐私需求。
实际应用场景
Foundation-sec-8b在网络安全生命周期中的应用广泛且实用,包括但不限于以下场景:
1. SOC加速
自动化警报分类,减少误报。 总结事件背景,协助快速调查。 提供即时建议,帮助分析师更快决策。
2. 主动威胁防御
模拟攻击路径,识别潜在漏洞。 根据组织基础设施对威胁进行建模,优先级排序。 预测未来攻击趋势,提前部署防御措施。
3. 工程赋能
AI辅助代码审查,确保代码安全性。 验证配置合规性,降低人为错误风险。 根据组织环境评估合规性证据,简化审计流程。
4. 自定义集成
使用组织特有的遥测数据、检测规则或威胁情报对模型进行微调。 构建适应组织独特需求的新工作流,确保真实世界部署中的精确性。
公开发布与社区参与
Foundation-sec-8b现已在Hugging Face上公开发布,开发者可以免费下载并探索其潜力。研究论文详细介绍了模型的技术细节,未来还将开源用于构建模型的训练流程。
思科强调,信任是网络安全领域的基石。通过开源和宽松许可,Foundation-sec-8b为组织提供了更高的透明度和控制权,同时鼓励社区共同推动AI驱动安全的发展。
这只是开始:未来的更多计划
Foundation-sec-8b只是思科Foundation AI团队的第一步。在未来几个月内,团队将陆续推出以下内容:
网络安全推理模型:为复杂的安全工作流带来更高的可解释性和分析深度。 新的基准测试套件:根据真实世界的、由从业者定义的任务评估AI模型的安全性。 额外工具和组件:帮助团队安全有效地微调、操作并将AI嵌入其安全堆栈。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











