百度正式开源了其最新的 ERNIE 4.5 系列,这是继 ERNIE 系列之后又一重磅发布的基础语言模型家族。该系列包含 10 款不同规模与架构的模型,从仅 0.3B(十亿)参数的小型密集模型 到高达 424B 参数的稀疏激活 MoE(混合专家)模型,全面覆盖从边缘设备到大规模推理的各种应用场景。
- 项目主页:https://yiyan.baidu.com/blog/zh/posts/ernie4.5
- GitHub:https://github.com/PaddlePaddle/ERNIE
- 模型:https://huggingface.co/collections/baidu/ernie-45-6861cd4c9be84540645f35c9
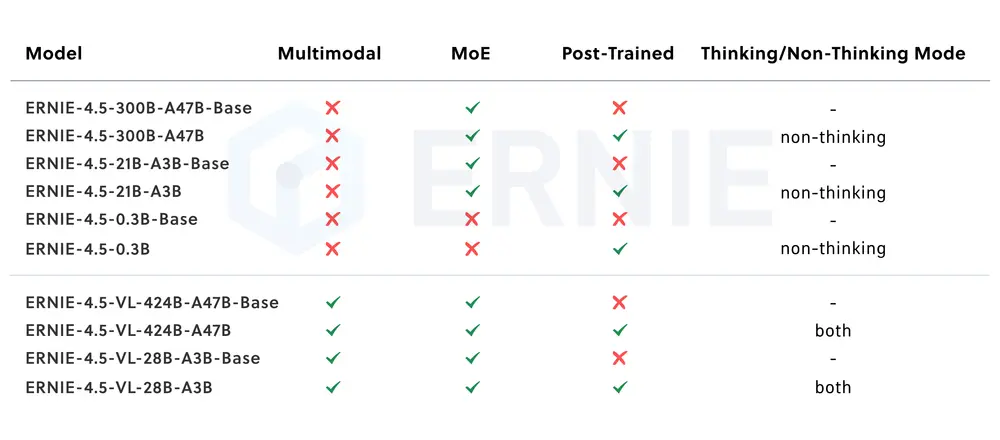
核心特性与技术亮点
✅ 多种模型变体,满足多样化需求
| 类型 | 模型名称 | 总参数量 | 活跃参数量 |
|---|---|---|---|
| 密集模型 | ERNIE 4.5-0.3B | 0.3B | 0.3B |
| 密集模型 | ERNIE 4.5-0.5B | 0.5B | 0.5B |
| 密集模型 | ERNIE 4.5-1.8B | 1.8B | 1.8B |
| 密集模型 | ERNIE 4.5-4B | 4B | 4B |
| MoE 模型 | ERNIE 4.5-MoE-3B | 6B | 3B |
| MoE 模型 | ERNIE 4.5-MoE-4B | 8B | 4B |
| MoE 模型 | ERNIE 4.5-MoE-6B | 12B | 6B |
| MoE 模型 | ERNIE 4.5-MoE-15B | 30B | 15B |
| MoE 模型 | ERNIE 4.5-MoE-47B | 94B | 47B |
| MoE 模型 | ERNIE 4.5-MoE-424B | 424B | 可变 |
MoE 技术说明:每个输入令牌仅激活部分“专家”(如 64 个专家中激活 2 个),在控制计算资源的同时实现高表达能力。
✅ 先进训练策略提升性能表现
ERNIE 4.5 使用多种前沿方法进行训练:
- 监督微调(SFT)
- 基于人类反馈的强化学习(RLHF)
- 对比对齐训练
训练语料库总计 5.6 万亿 token,涵盖中文、英文及其他多语言领域内容,使用百度自研的多阶段预训练流水线,确保模型具备强大的泛化能力和指令遵循能力。
基准测试表现亮眼
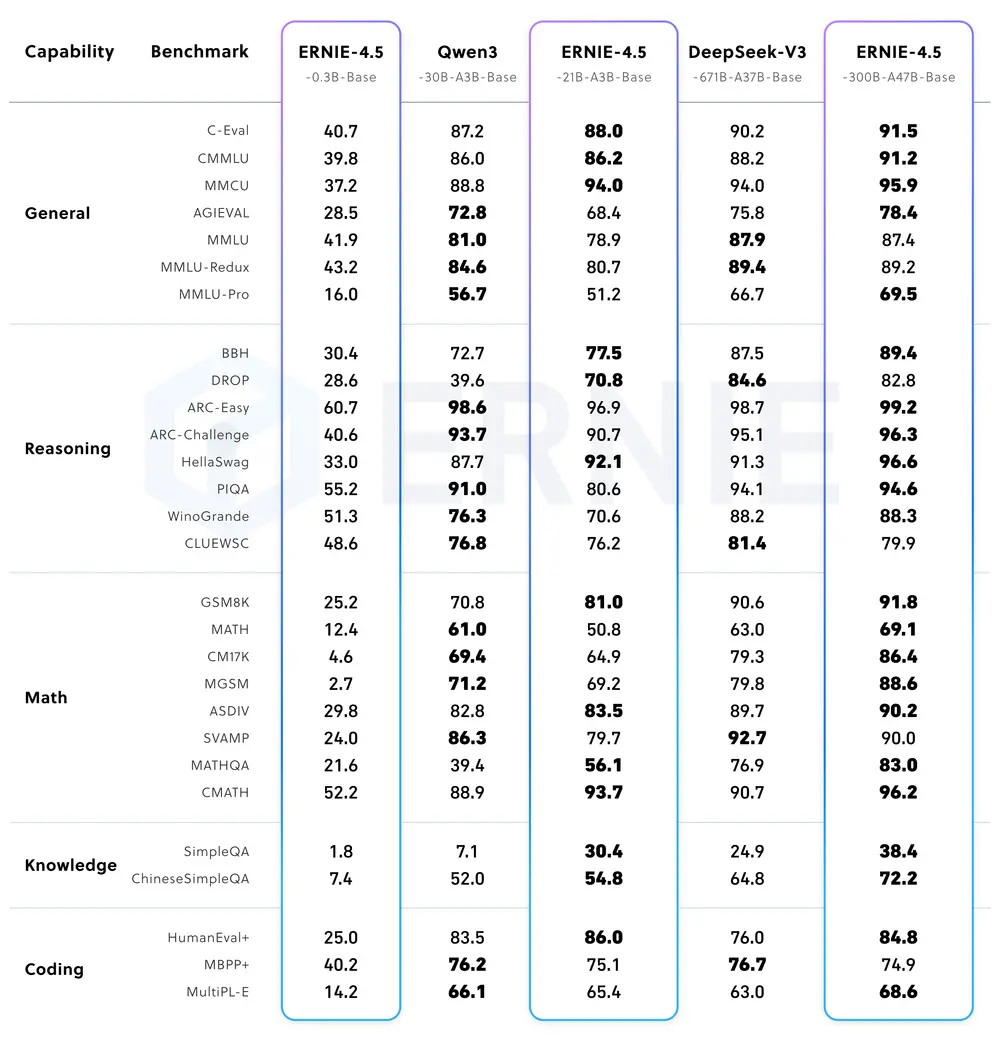
中文理解与生成能力领先
- 在 CMMLU(Chinese Multi-modal Language Understanding) 测试中,ERNIE 4.5 超越前代模型,在多个任务上达到当前中文理解领域的最先进水平。
- 在 BBH(Big-Bench Hard) 和 CMATH 数学推理任务中,ERNIE 4.5-21B-A3B-Base 表现优于 Qwen3-30B-A3B-Base。
多语言与国际基准媲美 GPT-4 / Claude
- 在 MMLU(Multi-choice Multi-language Understanding) 上,ERNIE 4.5-47B 的表现与 GPT-4 和 Claude 相当。
- 在 DeepSeek-V3-671B-A37B-Base 对比中,ERNIE-4.5-300B-A47B-Base 在 28 项测试中的 22 项中胜出。
长文本生成质量更优
- 百度内部评估指标显示,ERNIE 4.5 在长文本生成方面获得了更高的连贯性和事实性评分。
- 通过对比微调减少幻觉率,显著提升输出准确性和可解释性。
应用场景广泛支持
ERNIE 4.5 系列专为以下应用场景优化:
| 场景 | 描述 |
|---|---|
| 聊天机器人与 AI 助手 | 多语言支持 + 指令对齐使其适合构建智能客服、语音助手等 |
| 搜索与问答系统 | 支持高保真检索和生成,易于集成 RAG(Retrieval-Augmented Generation)流程 |
| 内容创作与编辑 | 长文本生成能力更强,适用于新闻写作、摘要生成、知识总结等 |
| 代码理解与生成 | 尽管当前版本聚焦于文本,但未来将扩展至代码与多模态 |
| 高效部署支持 | 提供 FP16 和 INT8 量化版本,便于在服务器或边缘设备上运行 |
此外,部分模型支持高达 128K 上下文长度,非常适合处理长文档、对话历史记忆、复杂逻辑推理等任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











