
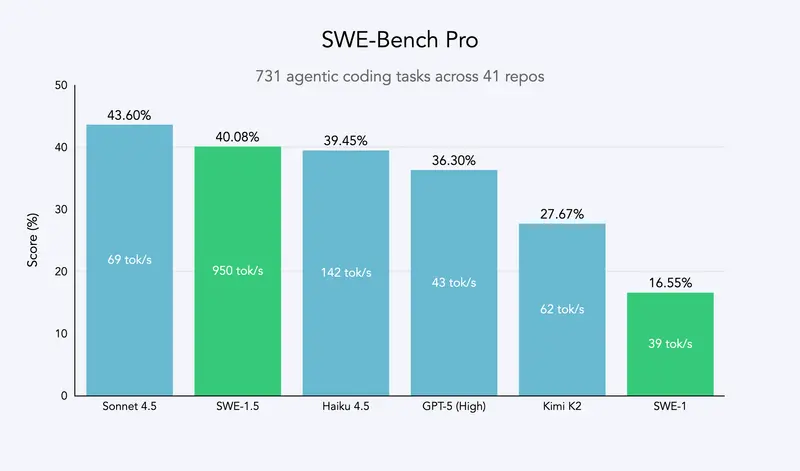
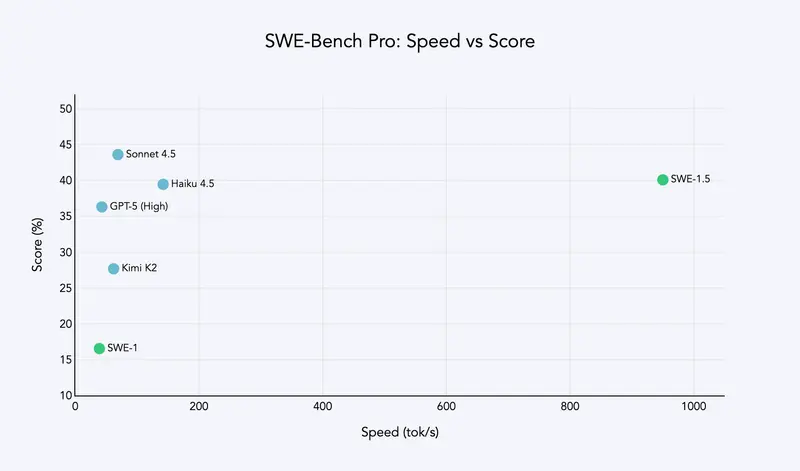
Cognition 正式推出软件工程专用模型家族新成员——SWE-1.5。作为一款拥有数千亿参数的前沿规模模型,它不仅实现了接近当前最佳水平(SOTA)的编程性能,更在速度上打破现有标准:通过与 Cerebras 合作,其服务速度最高可达 950 tok/s,分别是 Haiku 4.5 的 6 倍、Sonnet 4.5 的 13 倍。目前,SWE-1.5 已在 Windsurf 平台开放使用。
开发动机:打破“速度与智能”的固有权衡
在 AI 编程领域,开发者长期面临一个困境——必须在“快速响应的 AI”和“高性能的 AI”之间做选择。为消除这一限制,Cognition 此前已迈出关键一步:10 月 16 日发布 SWE-grep 智能体模型,通过训练实现快速上下文工程,同时不牺牲性能。
而 SWE-1.5 在此基础上进一步突破:它不再孤立优化单一组件,而是将模型、推理系统、智能体框架重构为一个统一系统,从全栈层面同步优化速度与智能,让开发者无需再做取舍。
核心突破:重构智能体-模型接口
作为专注智能体研发的实验室,Cognition 的目标并非训练孤立模型,而是打造完整可用的智能体。在 SWE-1.5 的开发中,团队重点优化了易被忽略的“智能体-模型接口”,具体通过四步实现:
- 端到端强化学习:基于领先的开源基础模型,在真实任务环境中,通过自定义的 Cascade 智能体框架开展强化学习(RL)。
- 全流程迭代优化:持续同步推进模型训练、框架改进、工具升级与提示工程,确保各环节适配。
- 核心组件重写:当模型速度提升 10 倍后,原有部分工具成为瓶颈,团队遂从头重写核心工具与系统,这些改进同时提升了 Windsurf 平台其他模型的性能。
- 真实场景验证:大量依赖内部“狗食测试”(dogfooding)驱动调优,结合多版“Falcon Alpha”beta 测试,根据实际用户体验调整智能体与模型,而非依赖通用奖励函数。
经调优后,SWE-1.5 在自有框架中的性能显著优于替代框架。需注意的是,这并非框架本身的优劣差异——为其他框架专门调优的模型(如 Claude Code 中的 Sonnet)也能达到同等甚至更优效果,替代框架中分数较低的主要原因是工具调用失败率更高。
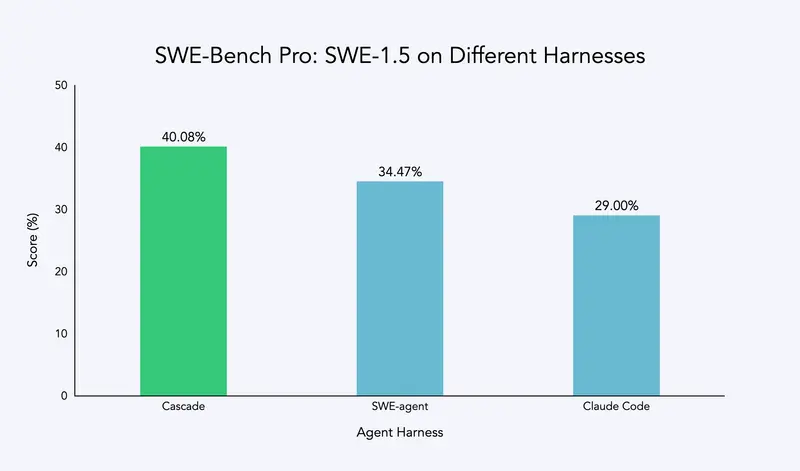
这一过程也印证了:选择编程智能体,不仅要看模型本身,其周围的编排系统对性能的影响同样关键。此前开发 Devin 时,团队就希望实现“模型与框架共同开发”,而 SWE-1.5 的发布终于达成这一目标。
技术支撑:高保真 RL 编程环境
Cognition 认为,RL 任务中编程环境的质量,直接决定下游模型的性能。针对现有常用编程环境的两大痛点,团队打造了专属的高保真环境:
1. 解决现有环境的核心问题
- 任务分布狭窄:多数实验室依赖 SWE-Bench 基准,但该基准的仓库与任务类型覆盖范围有限,无法匹配真实开发场景。
- 忽略软因素:仅用单元测试等“可验证正确性奖励”,会导致模型倾向于生成“AI 垃圾”——代码冗长、过度使用 try-catch 块等反模式,缺乏对代码质量的考量。
2. 构建高保真环境的关键举措
- 自定义数据集:手动创建数据集,覆盖 Devin 与 Windsurf 中真实存在的任务类型与编程语言,确保场景多样性。
- 三方协作设计:联合顶级高级工程师、开源维护者与工程领导者,共同搭建环境,同时引入三种互补的评分机制:
- 经典测试(单元测试、集成测试):验证代码正确性;
- 质量评分标准:评估代码质量与实现方法;
- 智能体端到端评分:通过浏览器模拟用户操作,测试产品功能。
- 奖励硬化流程:为避免“奖励黑客行为”(模型规避评分规则),由人类专家尝试寻找评分漏洞,多轮优化后,显著降低经典测试的假阳性率,填补评估空白。
目前,SWE-1.5 是基于该环境训练的首个模型,且训练规模仍处于初期阶段。团队预计,未来随着环境规模扩大,模型在代码质量等软因素上的表现将进一步提升。
训练与基础设施:依托 GB200 集群与协同优化
SWE-1.5 的性能突破,离不开底层基础设施与训练策略的支撑:
1. 硬件:首发 GB200 NVL72 集群
SWE-1.5 训练于由数千个 GB200 NVL72 芯片组成的集群,是业内首个基于新一代 GB200 芯片训练的公共生产模型。早在 6 月初,Cognition 就获得该硬件访问权限,当时固件尚未成熟、开源生态缺失,团队通过构建鲁棒的健康检查系统、耐故障训练机制,以及优化机架规模 NVLink 的使用,攻克了硬件初期的适配难题。
2. 训练策略:模型与框架协同优化
- 基础模型选择:经评估与消融实验后,选定某强大开源模型作为基础,再通过强化学习适配自有产品与任务。
- 迭代式协同优化:反复进行“狗食测试”,发现框架问题后调整工具与提示策略,再基于更新后的框架重新训练模型,实现模型与框架的同步迭代。
- 稳定训练保障:针对长多轮轨迹训练的稳定性,采用无偏策略梯度变体(具体方法见 SWE-grep 博客)。
3. 环境一致性:依托 otterlink 管理程序
RL 训练需要支持代码执行、网络浏览的高保真环境,团队通过自研 VM 管理程序 otterlink 实现这一需求:它可将 Devin 扩展至数万台并发机器,既保障训练环境与 Devin 生产环境一致,又能支持高并发训练。
性能验证:从基准测试到真实场景
1. 公共基准测试:接近 SOTA 且速度领先
尽管 Cognition 自 2024 年起不再报告 SWE-Bench 数据(认为其无法完全反映真实体验),但在更先进的 SWE-Bench Pro 基准(Scale AI 推出,覆盖多样化代码库的复杂任务)中,SWE-1.5 仍实现了接近前沿的性能,且完成任务的时间仅为同类模型的几分之一。
2. 真实场景应用:成为工程师日常工具
目前,Cognition 多位工程师已将 SWE-1.5 作为日常开发工具,核心应用场景包括:
- 深入探索与理解大型代码库(同时为 beta 版 Codemaps 功能提供支持);
- 构建端到端全栈应用;
- 快速编辑配置文件,无需记忆复杂字段名称。
以 Kubernetes 清单编辑为例:原有智能体完成该任务需约 20 秒,而 SWE-1.5 可将时间压缩至 5 秒内,完全处于“半异步死亡谷”的“流窗口”中,大幅提升开发效率。
速度优化:从推理到系统的全链路改进
为实现“最快编程智能体”的目标,Cognition 从推理合作到系统重构进行了多维度优化:
- 与 Cerebras 深度合作:借助 Cerebras 的推理能力,训练优化的草稿模型以实现更快的推测解码,同时构建自定义请求优先级系统,保障智能体会话的流畅性。
- 解决系统延迟瓶颈:当模型速度达到 950 tok/s 后,原本可忽略的系统延迟成为主导问题。团队遂重写 Windsurf 智能体的关键组件(如 lint 检查、命令执行管道),将每步操作的开销减少高达 2 秒。
未来规划与试用方式
SWE-1.5 的发布,证明了“速度与智能可兼得”——通过全栈协同设计,它在实现前沿编程性能的同时,速度达到 Sonnet 4.5 的 13 倍。作为小型专注团队的成果,该模型也体现了 Cognition 作为智能体实验室的优势:将产品、研究与基础设施深度结合,持续推进软件工程智能体的能力边界。
目前,SWE-1.5 已在 Windsurf 平台开放,开发者可从今日起直接试用,体验高速编程智能体带来的效率提升。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











