Step 3.5 Flash 是阶跃星辰推出的开源旗舰语言推理模型,定位为当前最强大的开源基座之一,专为极致效率、深度推理、智能体(Agent)执行而生。
- GitHub:https://github.com/stepfun-ai/Step-3.5-Flash
- Hugging Face:https://huggingface.co/stepfun-ai/Step-3.5-Flash
- 魔塔:https://modelscope.cn/models/stepfun-ai/Step-3.5-Flash
它基于稀疏混合专家(MoE)架构,总参数量 196B,但每 Token 仅激活约 11B 参数,在保持“大模型记忆与理解能力”的同时,实现“小模型级推理速度”,兼顾超高智能密度、极速响应、长上下文、本地部署友好四大核心优势,可胜任逻辑推理、数学、软件工程、深度研究、复杂工具调用、长文本处理等全场景复杂任务,是开源模型中对标 GPT-4o、Kimi K2.5 等闭源顶级模型的关键选手。
核心架构与设计:MoE+MTP+SWA,效率与能力双突破
1. 基础技术规格(硬核参数)
| 组件 | 规格 |
|---|---|
| 骨干网络 | 45 层 Transformer,隐藏维度 4096 |
| 上下文长度 | 256K(滑动窗口注意力优化) |
| 词汇表 | 128,896 tokens |
| 总参数量 | 196.81B(196B 骨干 + 0.81B 输出头) |
| 每 Token 激活参数量 | ~11B(仅激活少量专家,速度与成本大幅下降) |
2. 稀疏混合专家(MoE):大模型能力,小模型速度
Step 3.5 Flash 采用细粒度 MoE 路由设计,在不损失模型容量的前提下实现极致效率:
- 每层包含 288 个路由专家 + 1 个共享专家(始终激活);
- 每 Token 仅选择 Top-8 专家 激活,其余保持静默;
- 结果:保留 196B 模型的知识容量、理解深度与泛化能力,却以 ~11B 模型的计算量与显存开销 完成推理,实现“智能密度”最大化。
3. 三路多 Token 预测(MTP-3):吞吐量突破 300 tok/s
为满足智能体“快速思考、即时响应”的核心需求,模型内置专用 MTP Head,支持单次前向传播同时预测 4 个 Token,配合滑动窗口注意力,实现:
- 典型场景生成吞吐量:100–300 tok/s;
- 单流代码任务峰值:350 tok/s;
- 复杂多步推理链也能做到“即时响应、无明显等待”,远超传统开源模型。
4. 3:1 滑动窗口注意力(SWA):256K 上下文低成本高效
采用 1 层全注意力 + 3 层 SWA 的混合结构,在 256K 超长上下文下实现:
- 处理海量文档、超长代码库、多轮对话时,性能不衰减;
- 相比传统全注意力长上下文模型,计算开销大幅降低,部署成本更友好;
- 上下文压缩与记忆能力更强,适合深度研究、长文本理解、代码工程等场景。
核心能力:推理、代码、Agent 三强合一
1. 前沿智能 + 极速响应:智能体“想”得快、做得稳
区别于普通聊天模型“重在读”,Step 3.5 Flash 专为 Agent 设计,“想”得极快:
- MTP-3 技术带来超高吞吐,复杂推理链无延迟;
- 内置可扩展强化学习(RL)框架,支持持续自我进化;
- 工具调用、任务分解、多步计划执行稳定可靠,适合自动化 Agent 系统。
2. 代码与软件工程:工业级稳健引擎
在代码与软件工程领域,Step 3.5 Flash 表现达到开源第一梯队:
- SWE-bench Verified:74.4%,开源模型顶尖水平,可处理真实世界复杂软件工程任务;
- Terminal-Bench 2.0:51.0%,命令行工具使用、系统操作、脚本编写能力突出;
- LiveCodeBench-V6:86.4%,实时代码生成、调试、优化能力强;
- 支持长代码库理解、跨文件重构、复杂项目规划,是 AI 编程、代码智能体的理想基座。
3. 顶级推理能力:数学、竞赛、深度研究全面领先
在数学、逻辑、学术推理等硬核任务上,对标闭源顶级模型:
- AIME 2025:97.3%
- HMMT 2025(Feb):98.4%
- HMMT 2025(Nov):94.0%
- IMOAnswerBench:85.4%
- xbench-DeepSearch、ResearchRubrics 等深度研究基准全面领先同参数开源模型。
4. 长上下文与信息获取:256K 窗口+强检索理解
- 原生支持 256K 上下文,可直接输入整本书、大型代码库、超长对话;
- BrowseComp、BrowseComp-ZH 等网页/信息检索基准表现优异,配合上下文管理器(Context Manager)性能进一步提升;
- 适合深度研究、文档总结、知识库问答、长文本分析。
5. 本地部署友好:高端消费级硬件即可跑
专为易用性与隐私优化,支持本地部署:
- 可在 Mac Studio M4 Max、NVIDIA DGX Spark 等高端消费级/企业级硬件上运行;
- 数据完全本地处理,隐私安全可控;
- 性能与云端部署几乎无差距,兼顾效率与安全。
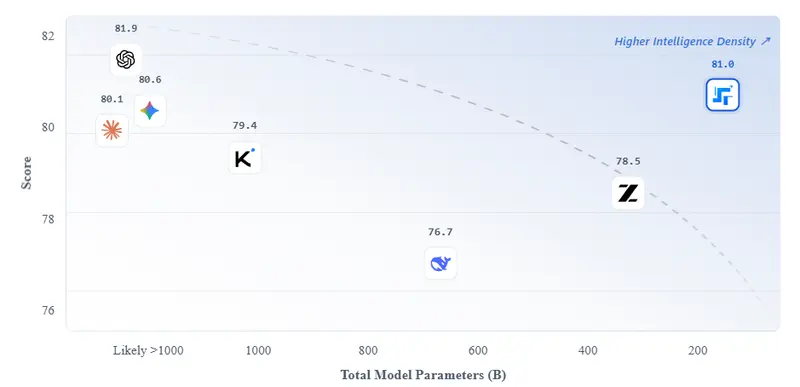
性能对比:开源最强,对标闭源顶级模型
Step 3.5 Flash 在推理、编程、智能体三大维度全面领先主流开源模型,部分指标逼近/追平 Kimi K2.5、GPT-4o 等闭源顶级模型,且在解码效率(速度/成本)上具备碾压优势。
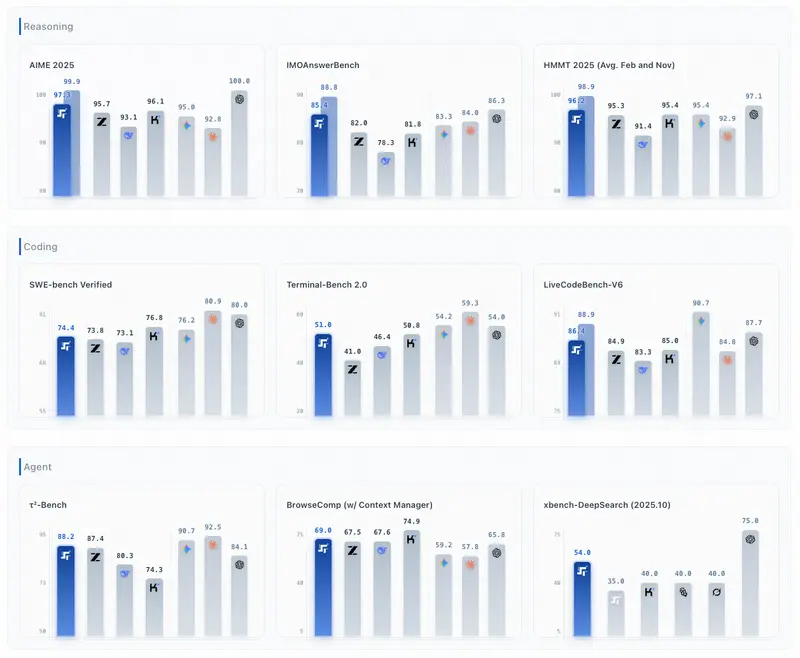
1. 核心效率对比(解码成本 & 吞吐)
| 模型 | 激活参数量 | 总参数量 (MoE) | 解码成本(相对) | 典型吞吐 |
|---|---|---|---|---|
| Step 3.5 Flash | 11B | 196B | 1.0x | 100–300 tok/s (MTP-3) |
| DeepSeek V3.2 | 37B | 671B | 6.0x | 33 tok/s |
| Kimi K2.5 | 32B | 1T | 18.9x | 33 tok/s |
| GLM-4.7 | 32B | 355B | 18.9x | 100 tok/s |
| MiniMax M2.1 | 10B | 230B | 3.9x | 100 tok/s |
| MiMo-V2 Flash | 15B | 309B | 1.2x | 100 tok/s |
解码成本越低 = 速度越快、单 Token 计算/显存开销越小、部署越便宜。
Step 3.5 Flash 以 1.0x 基准成本,实现最高吞吐与最强综合性能,性价比与效率遥遥领先。
2. 关键 Benchmark 精选(核心能力)
智能体 & 信息获取(Agency)
| Benchmark | Step 3.5 Flash | DeepSeek V3.2 | Kimi K2.5 | GLM-4.7 |
|---|---|---|---|---|
| τ²-Bench | 88.2 | 80.3 | — | 87.4 |
| BrowseComp | 51.6 | 51.4 | 60.6 | 52.0 |
| BrowseComp (w/ CM) | 69.0 | 67.6 | 74.9 | 67.5 |
| BrowseComp-ZH | 66.9 | 65.0 | 62.3 | 66.6 |
| GAIA (no file) | 84.5 | 75.1 | 75.9 | 61.9 |
| xbench-DeepSearch(10) | 56.3 | 55.7 | 40+ | 52.3 |
推理(数学/逻辑/学术)
| Benchmark | Step 3.5 Flash | DeepSeek V3.2 | Kimi K2.5 | GLM-4.7 |
|---|---|---|---|---|
| AIME 2025 | 97.3 | 93.1 | 96.1 | 95.7 |
| HMMT 2025 (Feb) | 98.4 | 92.5 | 95.4 | 97.1 |
| HMMT 2025 (Nov) | 94.0 | 90.2 | — | 93.5 |
| IMOAnswerBench | 85.4 | 78.3 | 81.8 | 82.0 |
代码 & 软件工程(Coding)
| Benchmark | Step 3.5 Flash | DeepSeek V3.2 | Kimi K2.5 | GLM-4.7 |
|---|---|---|---|---|
| LiveCodeBench-V6 | 86.4 | 83.3 | 85.0 | 84.9 |
| SWE-bench Verified | 74.4 | 73.1 | 76.8 | 73.8 |
| Terminal-Bench 2.0 | 51.0 | 46.4 | 50.8 | 41.0 |
整体结论:
- 推理、数学、学术:Step 3.5 Flash 全面领先同级别开源模型,接近闭源顶级;
- 代码/软件工程:SWE-bench、Terminal-Bench 均为开源第一梯队;
- 智能体、检索、长文本:配合上下文管理器后,BrowseComp 系列指标大幅提升,适合构建强 Agent;
- 效率:解码成本仅为同类大模型 1/6~1/18,速度与部署成本优势巨大。
快速上手:API 接入,几分钟可用
1. 支持平台(获取 API Key)
目前可通过两大平台调用 Step 3.5 Flash,其中 OpenRouter 提供免费试用:
| 提供商 | 官网 | Base URL |
|---|---|---|
| OpenRouter | https://openrouter.ai | https://openrouter.ai/api/v1 |
| StepFun(阶跃星辰) | https://platform.stepfun.com | https://api.stepfun.com/v1 |
2. 接入流程(极简)
- 注册平台账号,创建应用,获取 API Key;
- 选择模型 ID:
step-3.5-flash(不同平台名称略有差异,以平台文档为准); - 调用
/chat/completions接口,传入 256K 上下文内的 prompt,即可使用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











