
Deep Cogito在今天发布了其最新成果——Cogito v1系列模型,这是一组参数规模从30亿到700亿不等的开源大语言模型(LLMs)。这些模型不仅在性能上超越了同等规模的最佳开源模型,还引入了一种创新的训练策略——迭代蒸馏与放大(IDA),为通往通用超智能(AGI)提供了一条新的路径。
- 模型:https://huggingface.co/collections/deepcogito/cogito-v1-preview-67eb105721081abe4ce2ee53
- Ollama:https://ollama.com/library/cogito
要点
- 模型性能卓越:Cogito v1系列模型在大多数标准基准测试中均优于同等规模的最佳开源模型,包括LLaMA、DeepSeek和Qwen的对应模型。特别是70B模型,还超过了新发布的Llama 4 109B MoE模型。
- 推理与非推理模式切换:每个模型既可以直接回答(标准LLM模式),也可以在回答前进行自我反思(类似推理模型),这种灵活性使其在处理不同类型问题时更具优势。
- IDA训练策略:通过迭代蒸馏与放大(IDA)训练,Cogito v1模型能够突破传统监督学习的限制,实现自我改进和性能提升。
- 开源与广泛可用性:Cogito v1模型的代码和模型权重完全开源,用户可以在Hugging Face或Ollama上下载这些模型,或通过Fireworks AI或Together AI的API直接使用。
- 未来规划:Deep Cogito计划在未来几周和几个月内发布更大规模的模型,包括109B、400B、671B,以及这些模型规模的改进检查点。
通往通用超智能的路径
Deep Cogito认为,实现通用超智能需要超越当前AI系统的能力限制。AlphaGo及其后续的多种游戏AI展示了AI系统在狭窄领域实现超人表现的能力,但这些系统往往依赖于高级推理和迭代自我改进。Deep Cogito提出,通过在LLMs中结合高级推理的迭代自我改进,可以克服传统训练范式中的监督者限制,为实现通用超智能提供一个结构化且高效的途径。
迭代蒸馏与放大(IDA)
IDA是一种不受监督者智能上限限制的对齐策略,通过以下步骤实现:
- 放大:通过通常涉及更多计算的子程序创建更高的智能能力。
- 蒸馏:将提升后的智能蒸馏回模型参数,使放大的能力内化。
通过重复这两个步骤,每一轮迭代都在前一次迭代的进展基础上构建,形成一个正反馈循环。这种方法不仅提升了模型的性能,还在时间效率和可扩展性上优于流行的RLHF和从更大模型蒸馏等方法。
模型详情
Cogito v1系列模型的参数规模从3B到70B不等,从预训练的Llama/Qwen基础检查点开始训练。这些模型针对编码、函数调用和代理使用场景进行了优化,每个模型都可以在标准模式和推理模式下运行。与大多数推理模型不同,Deep Cogito未针对超长推理链进行优化。
评估
Deep Cogito将模型与最先进的同等规模模型在直接模式和推理模式下进行比较。结果显示,Cogito v1模型在多个基准测试中表现出色,尤其是在推理模式下。这些基准测试虽然无法完全反映现实世界的性能,但为模型的性能提供了有用的信号。Deep Cogito对模型在现实世界评估中的表现充满信心。
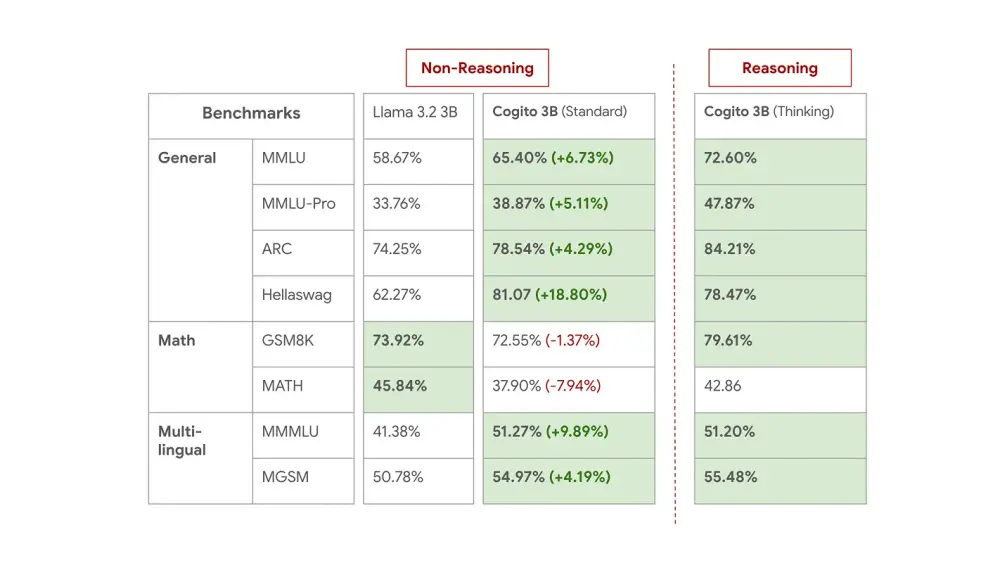
展望未来
Deep Cogito仍处于IDA扩展曲线的早期阶段,仅使用了传统大型语言模型后续/持续训练所需计算资源的一小部分。未来,公司计划探索用于自我改进的互补后续训练方法,并继续发布更大规模的模型。所有模型都将保持开源,以促进社区的协作和创新。
关于Deep Cogito
Deep Cogito总部位于旧金山,由AI领域的一些顶级风险投资公司提供充足资金支持。公司致力于构建通用超智能,通过高级推理和迭代自我改进等技术,不仅匹配人类水平的能力,还要揭示我们尚未想象的全新能力。Deep Cogito正在汇聚全球顶尖的工程师和研究人员,共同开创这一未来。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











