
MiniMax 团队正式发布 MiniMax M2 —— 一款专为代码生成与 AI 代理工作流优化的混合专家(Mixture-of-Experts, MoE)模型。该模型以 MIT 开源许可 在 Hugging Face 上发布,总参数量 2290 亿,但每 token 仅激活 约 100 亿参数,在保证性能的同时,显著降低了计算成本与延迟。
核心亮点:性能、成本与效率的平衡
- 性价比优势:官方宣称其价格仅为 Anthropic Claude Sonnet 的 8%,推理速度约为其 2 倍,并提供有限期的免费试用窗口。
- 代理工作流优化:针对需要长时间运行、多步骤规划、工具调用(如 shell、浏览器、代码执行器、检索系统)的复杂任务进行了专门优化。
- 开源可复现:模型权重、基准测试配置、部署指南(vLLM/SGLang)一并公开,确保社区可验证与部署。
架构特色:紧凑 MoE 与“交错思考”
- 紧凑 MoE 设计:2290 亿参数的 MoE 架构,动态激活 100 亿参数,有效控制了推理过程中的内存占用和尾延迟,使得在代理循环(规划-行动-验证)中能维持更稳定的性能。
- “交错思考”机制:模型内部的推理过程被
<think>...</think>标签包裹。官方强调,在多轮对话历史中保留这些标签对于维持多步骤任务和工具链的准确性至关重要。移除它们会显著损害模型表现。
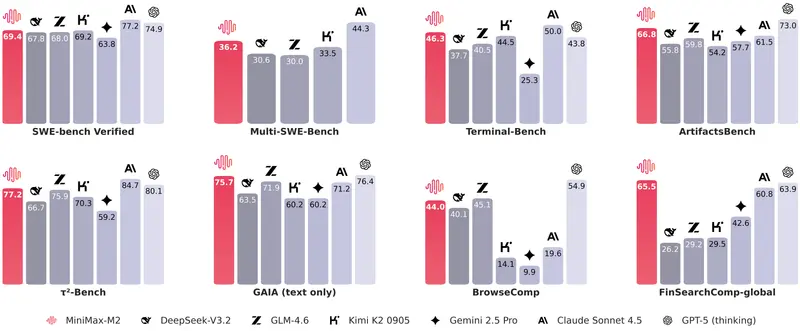
性能基准:聚焦开发者真实场景
M2 的评估侧重于代理与编码的实际应用,而非传统的静态问答:
- Terminal-Bench:46.3
- Multi SWE-Bench:36.2
- BrowseComp:44.0
- SWE-bench Verified:69.4(使用 OpenHands 脚手架,128k 上下文,100 步)
这些指标表明,M2 在终端操作、代码修改、网页浏览与交互等开发者高频场景中具备强大的实用性。
M1 vs M2:从广度到深度的演进
| 特性 | MiniMax M1 | MiniMax M2 |
|---|---|---|
| 总参数 | 4560 亿 | 2290 亿 |
| 激活参数 | 459 亿 | 100 亿 |
| 设计焦点 | 长上下文、通用推理 | 代理 & 代码工作流 |
| 思考格式 | 无特殊标签协议 | <think>...</think> 交错思考 |
| 主要基准 | MMLU-Pro, AIME, SWE-Bench | Terminal-Bench, Multi SWE-Bench, BrowseComp |
| 核心优势 | 通用长文本处理 | 特定场景高性能、低成本 |
M2 相比 M1,是一次从“通用大而全”到“专业小而精”的战略调整,专注于代理与编码领域,以更少的资源消耗,实现更优的特定任务性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











