在检索增强生成(RAG)和大规模语义搜索领域,嵌入模型(Embedding Model)的性能与成本往往难以兼得。今日,AI搜索引擎 Perplexity AI 发布了专为互联网规模检索任务打造的两款高性能文本嵌入模型:pplx-embed-v1 和 pplx-embed-context-v1。
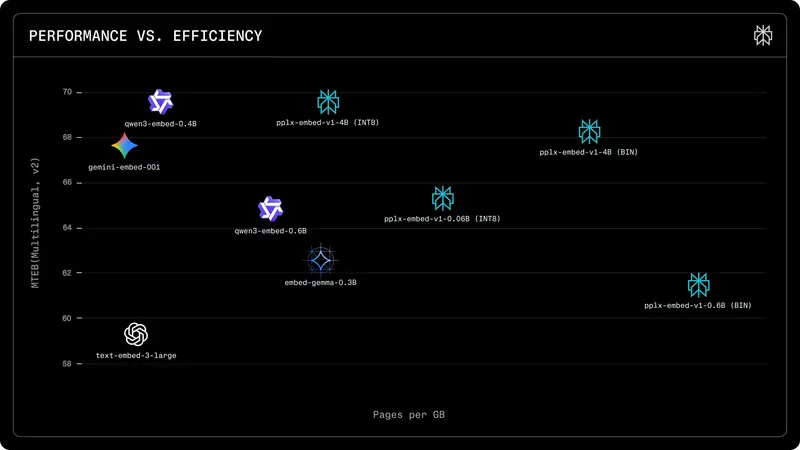
这两款模型不仅在多项基准测试中击败了 Qwen3-Embedding 和 Gemini-Embedding 等强劲对手,更通过原生支持的二进制量化技术,将存储成本降低了惊人的 32 倍,为大规模数据检索树立了新的标杆。
核心亮点:速度与质量的完美平衡
Perplexity 此次发布的模型提供了两种参数量版本,以满足不同场景的需求:
| 模型版本 | 参数量 | 定位 | 适用场景 |
|---|---|---|---|
| pplx-embed-v1 (Small) | 0.6B | 极致速度 | 实时搜索、边缘设备部署、高并发低延迟场景 |
| pplx-embed-v1 (Large) | 4B | 极致质量 | 复杂语义理解、长文档检索、高精度 RAG 系统 |
1. 革命性的量化支持:存储成本降低 32 倍
对于需要在 PB 级数据上运行向量数据库的企业而言,存储成本是巨大的负担。Perplexity 的新模型原生支持两种量化格式:
- INT8 量化:相比标准 FP32,存储空间减少 4 倍,推理速度显著提升,且精度损失微乎其微。
- 二进制量化(Binary Quantization):这是本次发布的最大亮点。相比 FP32,存储空间惊人地减少了 32 倍!
- 意义:这意味着原本需要 32GB 显存/内存存储的向量索引,现在仅需 1GB。这使得在消费级硬件甚至移动端设备上运行互联网规模的检索成为可能,同时保持了极高的召回率。
2. 无需指令前缀(No Instruction Prefix)
许多现有的嵌入模型(如 E5 系列)在推理时需要特定的指令前缀(如 "Represent this sentence for searching...")才能达到最佳效果。这不仅增加了提示工程的复杂度,还浪费了宝贵的 Context Window。
- Perplexity 的突破:新模型不需要任何指令前缀。无论是查询(Query)还是文档(Document),直接输入即可获得最优嵌入。这极大地简化了部署流程,避免了因忘记添加前缀导致的性能下降。
3. 霸榜的检索性能
在多维度的基准测试中,Perplexity 的新模型展现了强大的竞争力:
- 多语言支持:在全球多种语言的检索任务中表现优异。
- 上下文感知:在处理长文本和复杂上下文时,4B 版本展现了超越 Gemini-Embedding 和 Qwen3-Embedding 的理解能力。
- 真实世界表现:早期采用者报告称,在生产环境中,新模型在保持高准确率的同时,显著提升了召回效率(Recall)。
技术揭秘:多阶段训练打造鲁棒性
Perplexity 之所以能取得如此成绩,得益于其独特的多阶段训练流程:
- 基于扩散的预训练(Diffusion-based Pre-training):利用扩散模型的思想增强表示的鲁棒性,使模型能更好地捕捉数据的潜在分布。
- 对比学习(Contrastive Learning):通过精细的对比损失函数,拉近相关文本对的距离,推远不相关对,从而生成具有高度判别力的嵌入向量。
这种组合拳使得模型生成的嵌入不仅语义丰富,而且对噪声具有极强的抵抗力,非常适合嘈杂的真实世界数据检索。
部署与获取:完全开源,多平台支持
Perplexity 此次采取了极其开放的策略,开发者可以通过多种方式立即使用:
- 开源协议:MIT License(允许商业免费使用)。
- 下载平台:已上线 Hugging Face。
- API 访问:可通过 Perplexity API 直接调用。
- 框架兼容:完美支持 Transformers、SentenceTransformers 和 ONNX,可轻松集成到 LangChain、LlamaIndex 等主流框架中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











