在大模型竞赛普遍追求参数规模和算力投入的背景下,一个名为 Apriel-1.5-15B-Thinker 的新开源模型带来了不同的思路:它不依赖强化学习或偏好优化,也不从零训练,而是通过精心设计的中期训练流程,在文本与视觉任务上实现了接近顶级闭源模型的表现。
- 模型:https://huggingface.co/collections/ServiceNow-AI/apriel-15-15b-thinker-68dc288ab563cb0d4f4804c9
- Demo:https://huggingface.co/spaces/ServiceNow-AI/Apriel-Chat
这个 150 亿参数的多模态模型基于 Pixtral-12B 架构扩展而来,已在 MIT 许可下公开发布完整检查点、训练配方和评估协议。它的出现表明:对于资源有限的研究团队来说,更智能的训练策略可能比更大规模更具性价比。
不靠“暴力训练”,而是分阶段推进
Apriel 的核心理念是:能力应逐步构建,而非一次性堆砌数据与算力。为此,团队采用了三阶段渐进式训练流程:
阶段一:深度扩展(Deep Scaling)
在已有 Pixtral-12B 模型基础上,通过加深 Transformer 层结构来增强推理能力,而无需全量重新预训练。这种方式降低了计算成本,同时为后续复杂任务打下架构基础。
阶段二:分阶段持续预训练(CPT)
这是整个流程的关键环节,分为两个子阶段:
- 通用能力培养
使用多样化的图文对数据集,提升模型对语言和图像的基本理解能力。 - 针对性合成数据注入
引入人工构造的数据,专门解决多模态中的难点问题:- 空间结构建模(如页面布局分析)
- 组合语义理解(识别多个对象的关系)
- 细粒度感知(区分细微视觉差异)
这类数据并非随机生成,而是围绕特定推理任务设计,带来了可测量的性能提升。例如,在 MathVerse 视觉数学基准测试中,准确率提升了 +9.65 分。
阶段三:高质量监督微调(SFT)
最后阶段使用精选的指令-响应对进行微调,重点覆盖:
- 数学解题
- 编程实现
- 科学推理
- 工具调用
所有样本均包含完整的中间推理步骤(reasoning trajectory),引导模型学会“一步步思考”。值得注意的是,这一过程未使用 RLHF 或人类偏好标注,完全依赖高信号密度的训练数据完成行为对齐。

实测表现:高效且均衡
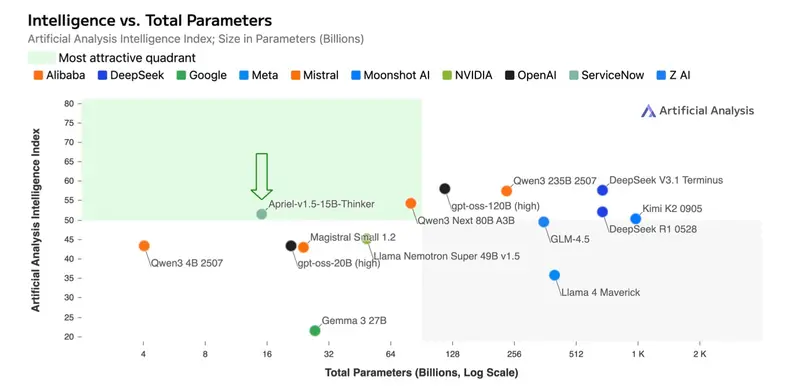
尽管参数量仅为 15B,Apriel-1.5-15B-Thinker 在多项评测中展现出惊人竞争力:
| 指标 | 表现 |
|---|---|
| 人工智能分析指数(AI24 Index) | 得分 52,与 DeepSeek-R1-0528 相当 |
| 文本推理(AIME、GPQA) | 在高级数学与硕士级科学问题上表现优异 |
| 多模态基准(平均) | 距离 Gemini 2.5 Flash 和 Claude Sonnet 3.7 平均仅差 5 分 |
| 部署需求 | 可在单张消费级 GPU 上运行 |
尤其值得称道的是其在图像相关任务中的表现——通常这类能力需要更大模型和更强算力支撑,但 Apriel 凭借合成数据的精准补强,显著缩小了差距。
方法背后的启示
Apriel 的成功揭示了一个正在被越来越多研究者重视的趋势:
训练过程的设计质量,正在成为决定模型能力的关键变量。
与其盲目扩大模型规模或依赖昂贵的人类反馈机制,不如专注于:
- 更高效的架构扩展方式(如深度扩展);
- 更有针对性的数据构建策略(如合成数据);
- 更清晰的推理路径引导(如带轨迹的 SFT);
这些做法不仅节省资源,也更容易复现和改进。
当然,该模型仍有局限:当前能力仍偏重文本推理,视觉端尚未完全释放潜力;交互式智能体功能仍在规划中。未来团队计划进一步加强视觉理解,并探索自主工具调用等动态决策能力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











