IBM 正式推出其最新开源语言模型系列 Granite 4.0,标志着企业在追求高性能与低推理成本之间的平衡上迈出关键一步。
这一代模型不再依赖传统的纯 Transformer 架构,而是采用创新的 混合 Mamba-2/Transformer 设计,结合了状态空间模型(SSM)的高效性和注意力机制的精确性,在显著降低内存占用的同时,保持甚至提升任务表现力。
- GitHub:https://github.com/ibm-granite/granite-4.0-language-models
- 模型:https://huggingface.co/collections/ibm-granite/granite-40-language-models-6811a18b820ef362d9e5a82c
- 文档:https://www.ibm.com/granite/docs/models/granite
更重要的是,Granite 4.0 是全球首批通过 ISO/IEC 42001:2023 认证的开源 LLM 家族,意味着它符合国际标准下的 AI 管理体系要求——涵盖可追溯性、治理、安全与合规性,为企业部署提供了更强信任基础。
该系列模型已上线 IBM watsonx.ai 平台,并可通过 Hugging Face、Docker Hub、Ollama、NVIDIA NIM、Replicate、LM Studio、Kaggle、Dell Pro AI Studio 等广泛渠道获取。
架构革新:为什么用 Mamba-2 + Transformer?
传统 Transformer 模型面临一个根本瓶颈:计算与内存消耗随上下文长度呈二次增长。当处理长文档、代码库或多轮对话时,GPU 内存迅速耗尽,推理成本急剧上升。
而 Mamba-2 作为状态空间模型(SSM),以线性复杂度处理序列,无论输入多长,其内存需求基本恒定。这使得它在长上下文场景中极具优势。
但 Mamba 在少样本学习等任务上仍略逊于 Transformer。因此,IBM 选择了一条折中路径:构建 9:1 的混合堆栈——每 9 层 Mamba-2 后插入 1 层标准 Transformer 块。
这种设计让模型既能高效处理长序列,又能保留局部语义精细解析能力,实现“两全其美”。
“我们发现,位置编码对这类混合架构不再是必需。”IBM 团队指出,“Mamba 天生具备顺序感知能力。”
发布型号:面向不同场景的灵活选择
IBM 推出了四个核心变体,均提供 Base 和 Instruct 版本,支持从边缘设备到云端服务的多样化部署:
| 模型名称 | 总参数 | 活跃参数 | 架构类型 | 适用场景 |
|---|---|---|---|---|
| Granite-4.0-H-Small | 32B | ~9B | 混合 MoE | 企业代理、客户支持自动化 |
| Granite-4.0-H-Tiny | 7B | ~1B | 混合 MoE | 边缘推理、轻量级工具调用 |
| Granite-4.0-H-Micro | 3B | 3B | 混合稠密 | 本地运行、资源受限环境 |
| Granite-4.0-Micro | 3B | 3B | 纯 Transformer | 兼容尚不支持混合架构的平台 |
其中,MoE(专家混合)结构进一步提升了参数效率——仅激活必要模块,大幅降低实际运行开销。
未来计划还包括发布更小的 Nano 系列(面向嵌入式设备)以及专为复杂推理优化的 “Thinking” 变体(预计 2025 年底前上线)。
实测性能:更低资源,更高产出
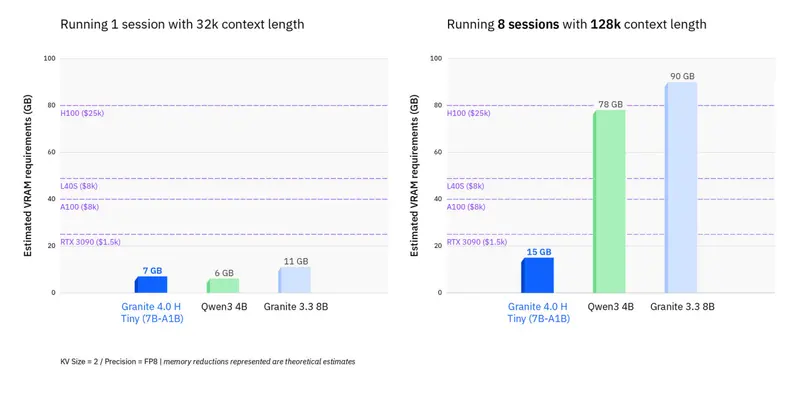
🔽 内存使用减少 >70%
在长上下文(如 128K token)或多会话并发场景下,相比同规模纯 Transformer 模型,Granite 4.0-H 系列可将 GPU RAM 占用降低 超过 70%。
这意味着:
- 更便宜的硬件即可承载高负载;
- 单卡可服务更多用户或更长输入;
- 显著降低 TCO(总拥有成本)。
模型已在 AMD Instinct™ MI-300X 上验证兼容性,并与 Qualcomm Hexagon™ NPU 合作优化移动端推理速度。

⬆️ 推理吞吐持续稳定
传统 LLM 在批次增大或上下文拉长时性能骤降,而 Granite 4.0 混合架构表现出更强的稳定性。即使面对大规模并发请求,输出速率依然平稳,尤其适合 RAG、AI 代理流水线等重负载应用。
质量不妥协:指令跟随与工具调用表现亮眼
尽管参数更少,Granite 4.0 在关键企业任务上的表现优于前代甚至更大模型:
- IFEval (HELM):H-Small 在所有开源模型中排名第一,仅次于参数高达其 12 倍的 Llama 4 Maverick(402B),展现出卓越的指令遵循能力。
- BFCLv3(函数调用基准):在准确调用 API 和工具方面,H-Small 与主流闭源模型相当,但运行成本远低于后者。
- MTRAG(多轮检索增强生成):在跨轮次、跨领域、含无法回答问题的复杂 RAG 场景中,可靠性显著提升。
即使是纯 Transformer 架构的 Granite-4.0-Micro(3B),也全面超越了之前的 Granite 3.3-8B,体现训练数据与方法学的持续进步。
企业级可信设计:不只是性能
IBM 强调 Granite 不只是一个高性能模型,更是为企业生产环境打造的可信基础设施:
✅ ISO/IEC 42001:2023 认证
Granite 成为全球首个获得该认证的开源 LLM 家族,证明其开发流程符合国际 AI 治理标准,适用于金融、医疗、政府等高监管行业。
🔐 加密签名 + 来源可验证
所有 Hugging Face 发布的检查点均附带 .sig 文件,开发者可验证模型完整性与来源真实性,防止篡改或污染。
🛡️ 漏洞赏金计划
IBM 联合 HackerOne 推出最高 10 万美元奖励的漏洞赏金项目,鼓励研究人员发现潜在越狱、对抗攻击等问题,持续强化模型安全性。
💼 IP 免责承诺
在 watsonx.ai 上使用 Granite 生成的内容,若引发第三方知识产权纠纷,IBM 提供无上限赔偿保障,极大降低企业法律风险。
训练细节与生态支持
- 训练数据:基于 22T token 的高质量语料,涵盖企业文档、代码、数学、网络安全、多语言内容等;
- 训练长度:最大支持 512K token 序列,评估测试达 128K;
- 数据准备:使用开源 Data Prep Kit 框架清洗与标注;
- 精度支持:发布 BF16 权重,支持 GGUF 量化转换,便于本地部署;
- 推理框架:已在 vLLM、Hugging Face Transformers 中完整支持;llama.cpp、MLX 正在优化中。
合作伙伴与应用场景
早期合作伙伴包括 EY(安永) 和 Lockheed Martin(洛克希德·马丁),已在客户支持、智能代理、文档分析等关键场景中测试 Granite 4.0。
典型用途包括:
- 作为低成本构建块,集成到大型 AI 工作流中执行函数调用;
- 在边缘设备运行本地化助手;
- 高效处理长文本摘要、合同审查、日志分析等任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











