4 月 14 日,智谱发布了一则重磅消息:推出新一代 GLM-4-32B-0414 系列模型。这一系列模型凭借 320 亿参数的强大性能,效果直逼 OpenAI 的 GPT 系列和 DeepSeek 的 V3/R1 系列,并且支持本地部署,为研究和企业提供了更加灵活的解决方案。
系列模型介绍
GLM-4-32B-0414 系列包含四款模型,分别是 GLM-4-32B-Base-0414、GLM-Z1-32B-0414、GLM-Z1-Rumination-32B-0414 和 GLM-Z1-9B-0414。每一款模型都针对不同的应用场景进行了优化,满足多样化的用户需求。
- GitHub:https://github.com/THUDM/GLM-4/blob/main/README_zh.md
- 模型:https://huggingface.co/collections/THUDM/glm-4-0414-67f3cbcb34dd9d252707cb2e
GLM-4-32B-Base-0414:强大的基础模型
GLM-4-32B-Base-0414 是这一系列的核心基础模型。在预训练阶段,该模型使用了 15T 高质量数据,其中包含大量推理类的合成数据,为后续的强化学习扩展奠定了坚实基础。
在后训练阶段,研发团队不仅针对对话场景进行了人类偏好对齐,还通过拒绝采样和强化学习等技术,进一步强化了模型在指令遵循、工程代码、函数调用等方面的表现,提升了模型在智能体任务所需的原子能力。这使得 GLM-4-32B-Base-0414 在工程代码、Artifacts 生成、函数调用、搜索问答及报告等方面都取得了出色的效果,部分 Benchmark 甚至可以媲美更大规模的 GPT-4o 和 DeepSeek-V3-0324(671B)等模型。
GLM-Z1-32B-0414:深度推理的强化版
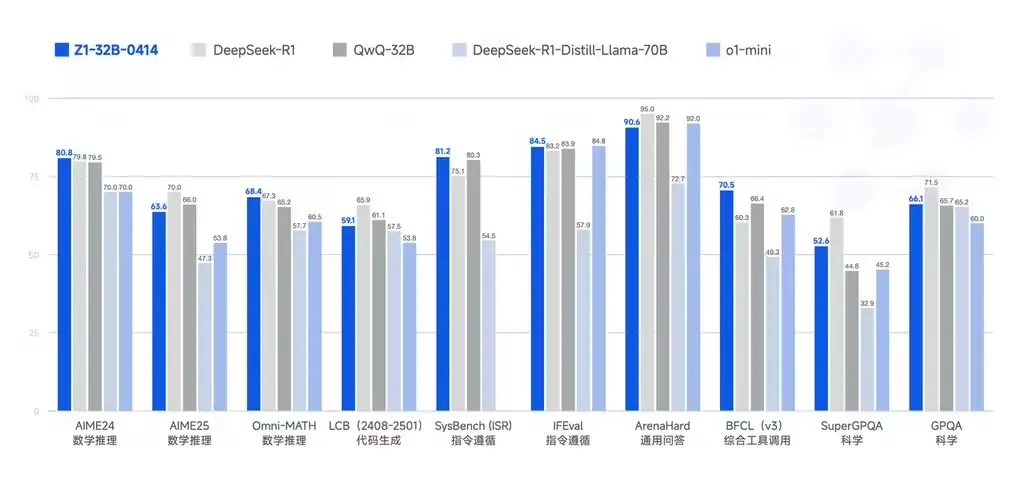
GLM-Z1-32B-0414 是在 GLM-4-32B-Base-0414 的基础上进一步优化的推理模型。它通过冷启动和扩展强化学习,以及在数学、代码和逻辑等任务上的进一步训练,显著提升了数理能力和解决复杂任务的能力。
在训练过程中,团队还引入了基于堆栈排序反馈的通用强化学习,进一步增强了模型的通用能力。这使得 GLM-Z1-32B-0414 在处理复杂的推理任务时表现出色,能够更好地应对多样化的应用场景。
GLM-Z1-Rumination-32B-0414:沉思型深度推理模型
GLM-Z1-Rumination-32B-0414 是一款具有沉思能力的深度推理模型,对标 OpenAI 的 Deep Research。它通过更长时间的深度思考来解决更开放和复杂的问题,例如撰写两个城市 AI 发展的对比情况以及未来发展规划。
该模型结合搜索工具处理复杂任务,并通过多种规则型奖励来指导和扩展端到端强化学习训练。这种设计使得 GLM-Z1-Rumination-32B-0414 在处理复杂任务时更具优势,能够提供更全面、更深入的解决方案。
GLM-Z1-9B-0414:开源小尺寸模型
GLM-Z1-9B-0414 是一个开源的 9B 小尺寸模型,尽管参数量较小,但在数学推理和通用任务中依然展现出极为优秀的能力。其整体表现已处于同尺寸开源模型中的领先水平,为资源有限的研究团队和中小企业提供了高性能的 AI 选择。
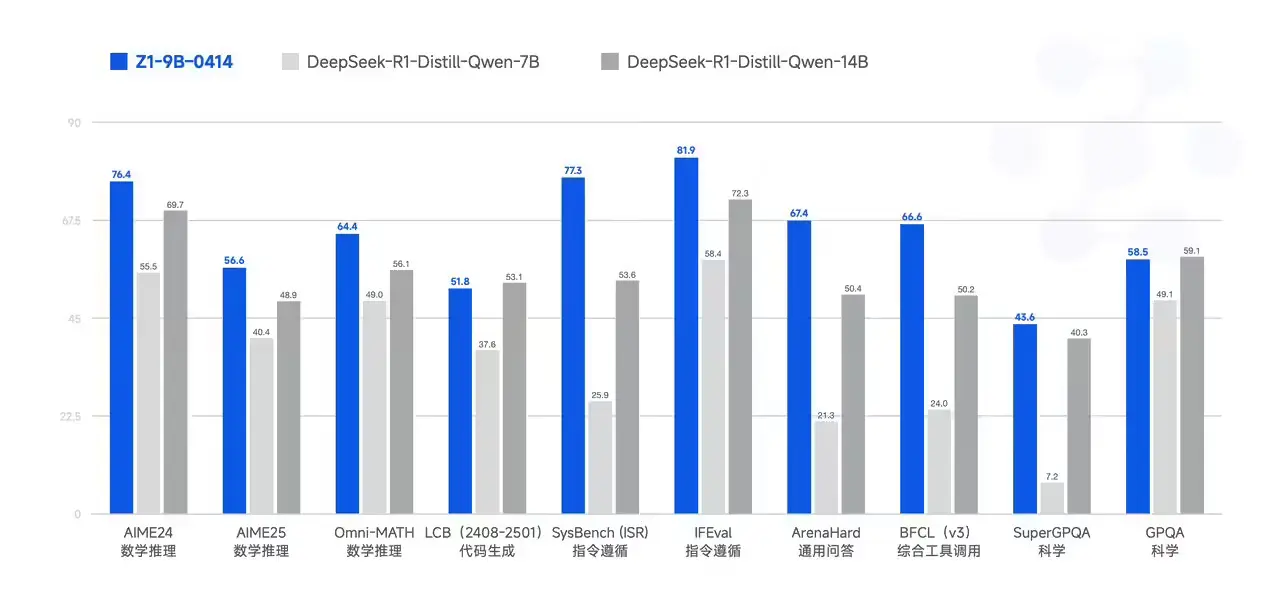
测试结果:卓越的性能表现
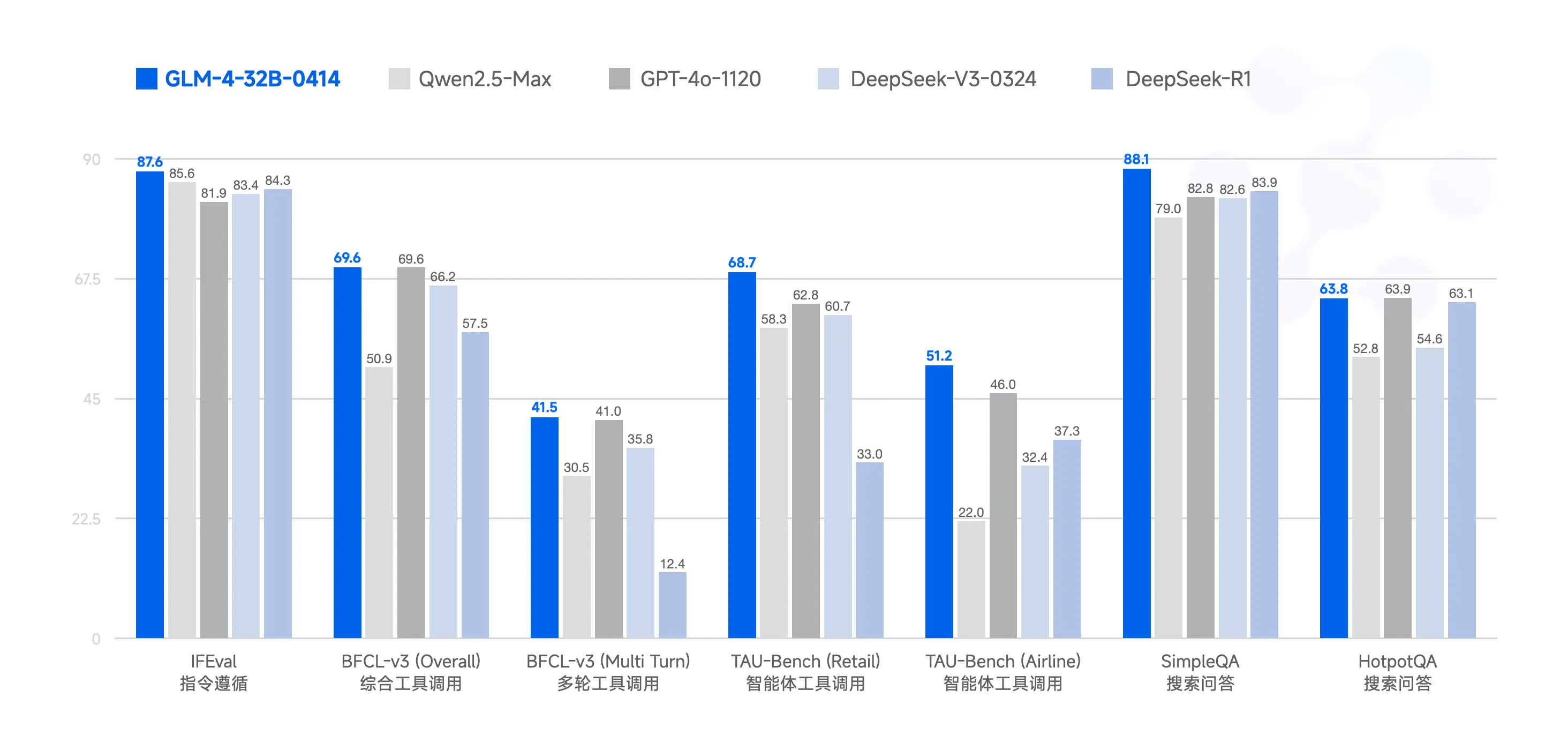
GLM-4 系列在多项基准测试中表现优异。例如,在 IFEval 指令遵循测试中得分 87.6;在 TAU-Bench 任务自动化测试中,零售场景得分 68.7,航空场景得分 51.2;在 SimpleQA 搜索增强问答测试中得分 88.1。此外,在代码修复方面,GLM-4 在 SWE-bench 测试中的成功率达 33.8%。
| 模型 | IFEval | BFCL-v3 (Overall) | BFCL-v3 (MultiTurn) | TAU-Bench (Retail) | TAU-Bench (Airline) | SimpleQA | HotpotQA |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Max | 85.6 | 50.9 | 30.5 | 58.3 | 22.0 | 79.0 | 52.8 |
| GPT-4o-1120 | 81.9 | 69.6 | 41.0 | 62.8 | 46.0 | 82.8 | 63.9 |
| DeepSeek-V3-0324 | 83.4 | 66.2 | 35.8 | 60.7 | 32.4 | 82.6 | 54.6 |
| DeepSeek-R1 | 84.3 | 57.5 | 12.4 | 33.0 | 37.3 | 83.9 | 63.1 |
| GLM-4-32B-0414 | 87.6 | 69.6 | 41.5 | 68.7 | 51.2 | 88.1 | 63.8 |
采用 MIT 许可的 GLM-4 系列降低了计算成本,为研究和企业提供了高性能的 AI 解决方案。无论是基础模型的广泛适用性,还是深度推理模型的复杂任务处理能力,GLM-4 系列都展现出了强大的竞争力。
| 模型 | 框架 | SWE-bench Verified | SWE-bench Verified mini |
|---|---|---|---|
| GLM-4-32B-0414 | Moatless | 33.8 | 38.0 |
| GLM-4-32B-0414 | Agentless | 30.7 | 34.0 |
| GLM-4-32B-0414 | OpenHands | 27.2 | 28.0 |
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











