新Anthropic 重磅发布 Sonnet 4.6:100 万上下文窗口 + 类人操作电脑,免费用户直接升级今日,Anthropic 正式发布了 Claude Sonnet 4.6,这是其中型模型系列的最新力作。不仅保持了公司标志性的四个月更新周期,更带来了令人瞩目的性能飞跃:100 万 Token 的超长...大语言模型早报# Anthropic# Claude Sonnet 4.6# Sonnet 4.62天前070
新Cohere 重磅开源 Tiny Aya:33 亿参数撬动 70+ 语言,手机离线也能跑的“多语言神器”在多语言 AI 领域,长期存在一个悖论:要么模型巨大无比、依赖云端算力,只能覆盖主流语言;要么模型轻量但能力孱弱,无法处理复杂的小语种任务。 今日,在印度 AI 峰会期间,企业级 AI 独角兽 Coh...大语言模型# Cohere# Tiny Aya2天前040
新阿里发布Qwen3.5 系列大模型:两大旗舰模型登场,多项评测超越国际一线今天下午,阿里并未进行大规模宣传,而是在其官方对话页面chat.qwen.ai上低调上线了Qwen3.5系列的两款全新大语言模型——Qwen3.5-Plus与Qwen3.5-397B-A17B。 项目...大语言模型早报# Qwen3.5# Qwen3.5-397B-A17B# Qwen3.5-Plus3天前050
京东开源 JoyAI-LLM-Flash:3B 激活参数 MoE 模型,专为智能体与高吞吐场景优化京东在 Hugging Face 正式开源其最新大语言模型 JoyAI-LLM-Flash,标志着其在高效、低成本、智能体友好型 AI 基础模型领域的重大进展。 模型:https://huggingf...大语言模型# JoyAI-LLM-Flash# 京东4天前0190
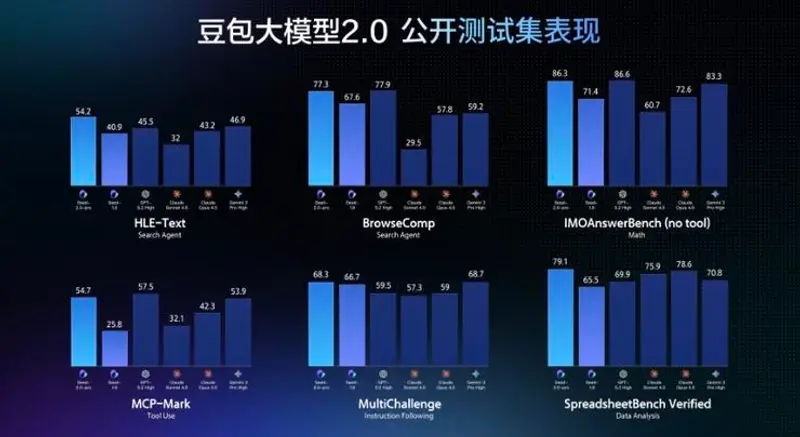
字节跳动发布豆包大模型2.0:数学推理顶尖,复杂任务执行强,API价格仅为竞品五分之一继 Seedance 2.0 视频模型和 Seedream 5.0 Lite 图像模型后,字节跳动于 2 月 14 日正式推出 豆包大模型 2.0(Doubao-Seed-2.0)系列。新版本针对大规...大语言模型早报# Doubao-Seed-2.0# 字节跳动# 豆包大模型2.05天前0110
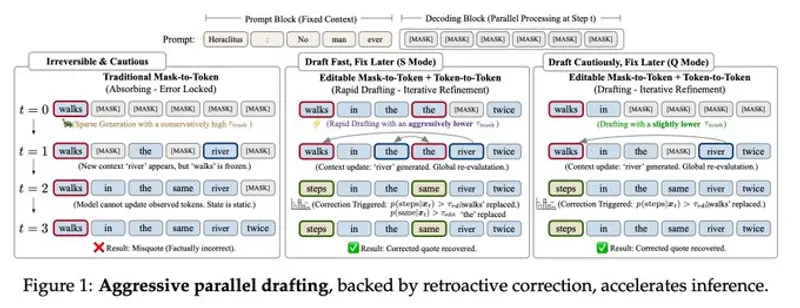
蚂蚁集团发布 LLaDA2.1:支持实时自我修正的开源扩散语言模型当大语言模型不再只能逐词生成,而是可以实时编辑自己已经生成的内容,会带来怎样的变革? 蚂蚁集团 inclusionAI 团队正式推出 LLaDA2.1——一款彻底打破自回归模型主导地位的文本扩散大模型...大语言模型# LLaDA2.1# 扩散语言模型5天前050
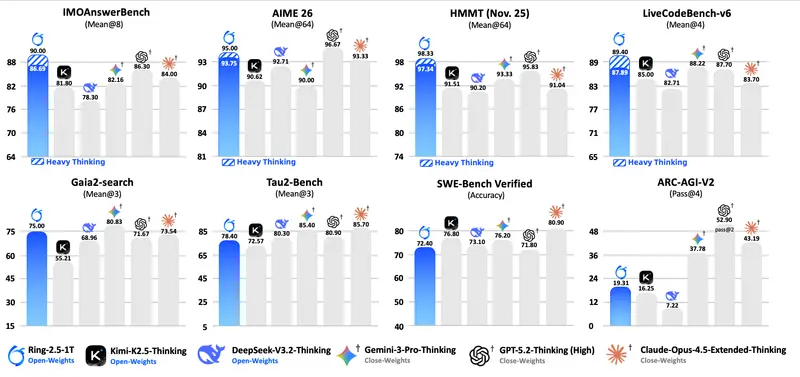
蚂蚁集团 inclusionAI 团队推出Ring-2.5-1T:全球首个万亿参数混合线性注意力思维模型蚂蚁集团 inclusionAI 团队正式推出 Ring-2.5-1T,这是全球首个基于混合线性注意力架构的开源万亿参数思维模型,标志着向通用人工智能体迈出关键一步。 Hugging Face :ht...大语言模型# Ring-2.5-1T# 蚂蚁集团6天前080
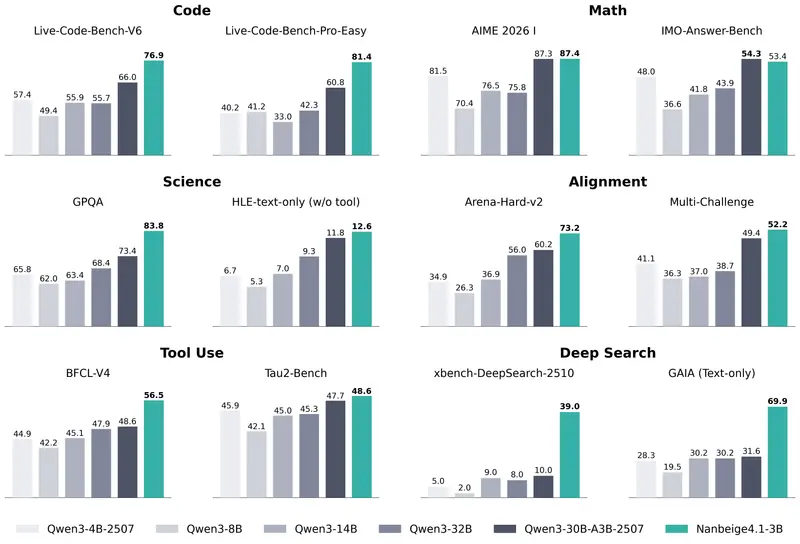
Nanbeige4.1-3B:在保持小参数规模的同时,实现强大推理、偏好对齐与高效智能体能力Nanbeige4.1-3B 基于 Nanbeige4-3B-Base 架构构建,是Nanbeige团队此前推出的推理专用模型 Nanbeige4-3B-Thinking-2511 的全面增强迭代版本...大语言模型# Nanbeige4.1-3B# 推理模型6天前0100
MiniMax正式发布MiniMax M2.5 :更快、更强、更智能,专为现实生产力打造今天,MiniMax 正式推出全新一代大模型——MiniMax M2.5。这款模型依托在数十万个复杂真实世界环境中开展的大规模强化学习训练,实现了能力的全面升级。 在编程开发、智能体工具使用与信息搜索...大语言模型早报# MiniMax# MiniMax M2.56天前01310
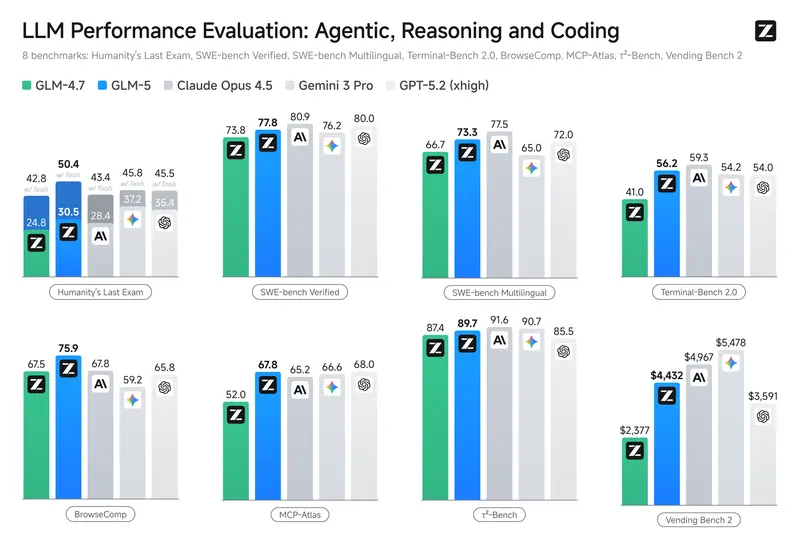
智谱AI正式发布GLM-5:744B参数+28.5T数据,长周期智能体能力登顶开源第一智谱AI正式推出新一代通用大模型——GLM-5,这款模型在设计之初就明确了核心定位:面向复杂系统工程和长周期智能体任务,致力于打破基础模型“只能聊天、难以落地”的局限,实现从“氛围编程”到“智能体工程...大语言模型# GLM-5# 智谱AI1周前0140
Cursor 发布 Composer 1.5:强化学习提升 20 倍,支持复杂代码推理Cursor 团队近日正式推出其智能编程模型 Composer 1.5,作为对前代 Composer 1 的重大升级。新版本聚焦于复杂、多步骤编程任务的处理能力,在推理深度、上下文管理和响应效率上均实...大语言模型# Composer 1.5# Cursor1周前070
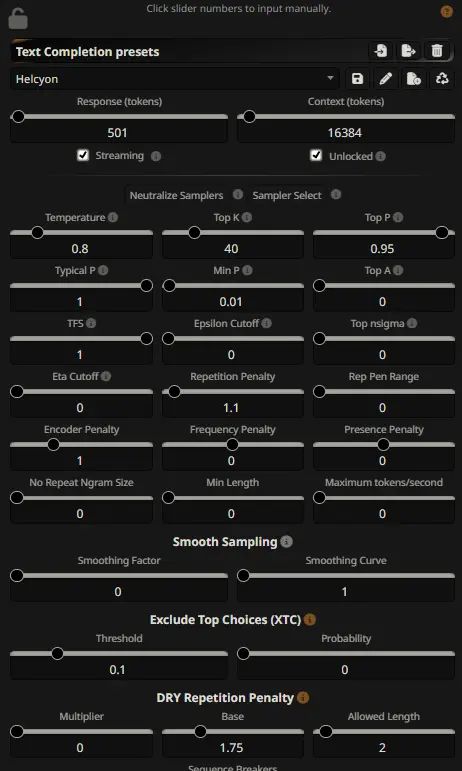
Helcyon-Mercury-12B-v3.0:基于 Mistral Nemo 的高情感智能对话模型在本地大模型(Local LLM)生态中,大多数模型追求的是“能回答问题”或“会写代码”。但 Helcyon-Mercury-12B-v3.0 的目标截然不同——它不满足于做一台“聊天机器”,而是试图...大语言模型# Helcyon-Mercury-12B-v3.02周前0130