
“如果 Transformer 是记忆大师,线性 RNN 是状态追踪者,那么混合模型就是集两者之大成的‘全能选手’。”
艾伦AI研究所(Ai2)今日正式发布了 Olmo Hybrid,这是一个全新的 7B 参数完全开源模型系列。通过与前代纯 Transformer 架构的 Olmo 3 7B 进行严格的受控对比,Ai2 提供了令人信服的证据:混合架构(Hybrid Architecture)不仅可行,而且在数据效率和扩展性上具有显著优势。
- 官方介绍:https://allenai.org/blog/olmohybrid
- 模型:https://huggingface.co/collections/allenai/olmo-hybrid
核心发现震撼业界:Olmo Hybrid 在达到与 Olmo 3 相同性能(如 MMLU 基准)时,仅需消耗 49% 的训练 Token。 这意味着,你可以用一半的数据和计算成本训练出同样聪明的模型,或者用相同的数据训练出一个明显更强的模型。
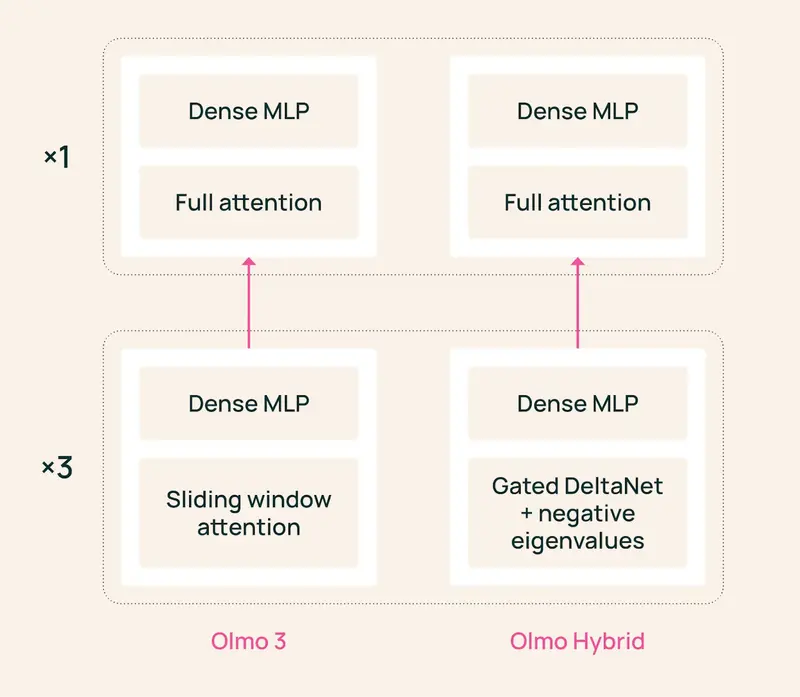
核心突破:为什么混合架构是未来?
Transformer 统治了 NLP 领域近十年,但其局限性日益凸显:注意力机制随序列长度呈二次方增长,导致长上下文推理昂贵;且其缺乏天然的状态跟踪能力。相反,线性 RNN(如 SSM、DeltaNet)虽能高效处理长序列并擅长状态追踪,却在精确回忆早期信息上表现不佳。
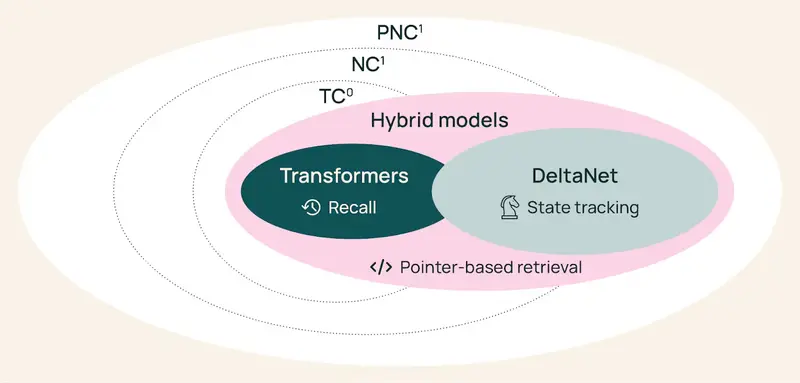
Olmo Hybrid 巧妙地融合了二者:
- 架构设计:采用 3:1 混合比例,即每 3 层 Gated DeltaNet(现代线性 RNN)后跟随 1 层 多头注意力(MHA)。
- 75% 的层由 DeltaNet 构成,负责高效的状态跟踪和长序列建模。
- 25% 的层保留注意力机制,确保模型能精准“回溯”序列早期的关键细节,防止信息在有界状态中丢失。
- 理论支撑:Ai2 的研究证明,混合架构在理论上比单一的 Transformer 或线性 RNN 更具表达力。这种表达力优势直接转化为预训练期间更高效的损失下降曲线。
实测数据:效率与性能的双重胜利
1. 2 倍数据效率 (2x Data Efficiency)
在严格控制变量(数据分布、训练基础设施、超参数)的对比实验中:
- MMLU 基准:Olmo Hybrid 达到与 Olmo 3 相同的准确率,但Token 用量减少 49%。
- Common Crawl 评估:用少 35% 的 Token 即可达到同等水平。
- 结论:由于训练吞吐量相当,Token 的节省直接等同于计算成本(GPU 小时)的减半。
2. 长上下文的绝对优势
随着上下文长度增加,混合架构的优势愈发明显:
- RULER 基准测试:
- 在短上下文(<4k)中,混合模型略逊于纯 Transformer。
- 在 8k 长度时实现反超。
- 在 64k 超长上下文中,配合 DRoPE 位置编码,Olmo Hybrid 得分高达 85.0,远超使用 YaRN 的 Olmo 3 (70.9)。即使同样使用 YaRN,混合模型 (76.9) 也优于纯 Transformer。
- 原因:线性层的线性复杂度使得处理长序列的成本极低,而定期的注意力层保证了长距离依赖的准确性。
3. 全面的能力提升
- 中期训练优势:在训练中期,Olmo Hybrid 在数学、科学推理等复杂任务上已明显领先 Olmo 3。
- 最终表现:完成 6T Token 训练后,混合模型在 BBH 和 MMLU Pro 等高难度基准上取得显著增益,仅在少数编码任务上初期略慢,但很快被弥合。
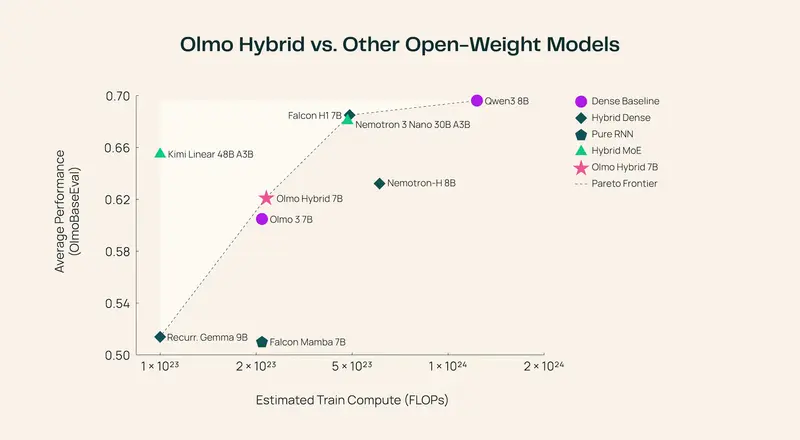
技术细节:首个在 B200 上训练的开源先锋
- 模型规模:7B 参数。
- 训练数据:6 万亿 (6T) Token,基于 Olmo 3 32B 改进的高质量数据混合。
- 硬件基础设施:
- 启动于 512 张 NVIDIA H100。
- 中途迁移至 NVIDIA HGX B200 集群(由 Lambda Labs 托管)。
- 里程碑:Olmo Hybrid 成为首批在 Blackwell B200 架构上训练完成的最先进完全开源模型之一。
- 训练速度:与 Olmo 3 持平,证明效率增益源自架构本身,而非牺牲训练速度。
深度洞察:表达力驱动扩展律
Ai2 不仅给出了结果,还解释了“为什么”:
- 表达力即效率:语言建模本质上是学习无数离散子任务。混合模型能表达的子任务集合 > 纯 Transformer 或 纯 RNN。因此,它能从每个 Token 中提取更多信息,更快降低 Loss。
- 缩放律预测:拟合的缩放律曲线显示,随着模型规模扩大,混合架构的 Token 节省因子将从 1B 时的 1.3 倍 提升至 70B 时的 1.9 倍。这意味着模型越大,混合架构的优势越恐怖。
开源生态意义
Olmo Hybrid 的发布是对当前“混合模型热潮”(如 Samba, Nemotron-H, Qwen3-Next, Kimi Linear)的有力回应和补充:
- 完全开放:权重、代码、数据配比、技术报告全部开源(Apache 2.0 / OLC 许可)。
- 严谨对照:不同于许多商业模型的“黑盒”宣传,Olmo Hybrid 提供了与基线模型(Olmo 3)最公平、最透明的对比数据。
- 社区指引:为学术界和工业界指明了方向——混合架构不是噱头,而是下一代高效大模型的基石。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











