
随着企业 AI 应用从简单的聊天机器人向复杂的多智能体系统(Multi-Agent Systems)演进,两大瓶颈日益凸显:上下文爆炸导致成本激增与目标漂移,以及每一步都需大模型推理带来的高昂"思考税"。
今日,英伟达正式推出 NVIDIA Nemotron 3 Super,一款专为解决上述难题而生的开放权重模型。凭借创新的混合架构与高达 100 万词元 的上下文窗口,该模型在保持顶尖准确性的同时,将智能体任务的吞吐量提升了高达 5 倍,树立了新一代高效能大模型的标准。
- 官方介绍:https://research.nvidia.com/labs/nemotron/Nemotron-3-Super
- 模型:https://huggingface.co/collections/nvidia/nvidia-nemotron-v3
- Ollama:https://ollama.com/library/nemotron-3-super
- OpenRouter:https://openrouter.ai/nvidia/nemotron-3-super-120b-a12b:free
核心突破:解决智能体的两大痛点
1. 终结“上下文爆炸”
在多智能体协作中,历史对话、工具输出和中间推理步骤会迅速堆积,导致上下文长度呈指数级增长。
- 解决方案:Nemotron 3 Super 拥有 1,000,000(100 万)的原生上下文窗口。
- 价值:智能体可将完整的工作流状态保留在内存中,无需频繁截断或重新发送历史,彻底防止“目标漂移”,确保长任务执行的连贯性。
2. 减免“思考税”
传统方案中,每个子任务都调用大型模型会导致延迟高企、成本失控。
- 解决方案:采用 混合专家(MoE) 架构,总参数量 1200 亿,但推理时仅激活 120 亿 活跃参数。
- 价值:以小型模型的算力成本,实现大型模型的推理能力,大幅降低单次调用的延迟与费用。
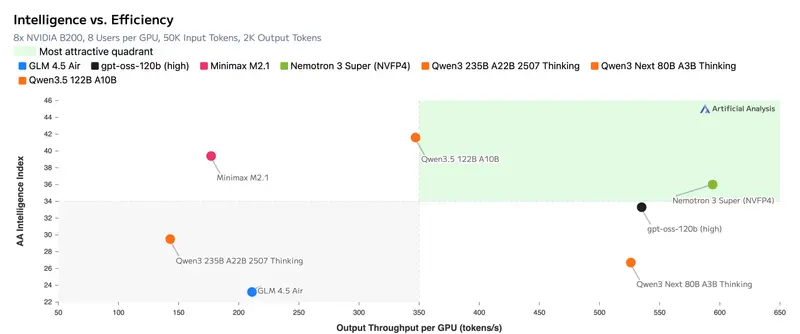
架构创新:四大引擎驱动效率飞跃
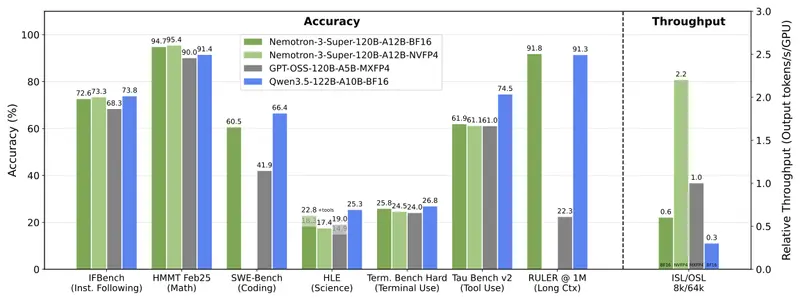
Nemotron 3 Super 通过四项前沿技术创新,实现了比前代模型高达 5 倍的吞吐量和 2 倍的准确性提升:
| 技术特性 | 原理与优势 |
|---|---|
| 混合架构 (Mamba + Transformer) | Mamba 层提供 4 倍的内存与计算效率,擅长线性长序列处理;Transformer 层负责高阶逻辑推理。两者结合,兼顾速度与深度。 |
| 潜在混合专家 (Latent MoE) | 行业首创。通过在低维空间激活专家,以单个专家的计算成本实现四个专家的协同效果,显著减少数据搬运开销,提升推理精度。 |
| 多词元预测 (MTP) | 一次性预测多个未来词元,而非逐个生成。推理速度提升 3 倍,且无需额外的草稿模型,自我加速。 |
| NVFP4 精度优化 | 专为 NVIDIA Blackwell 平台优化,支持 4 位浮点(NVFP4)推理。相比 Hopper 架构上的 FP8,速度提升 4 倍,且精度无损。 |
性能实测:速度与精度的双重领跑
在权威基准测试中,Nemotron 3 Super 展现了压倒性的优势,特别是在智能体任务和长文本处理领域:
- 智能体能力(Agentic Tasks):
- SWE-Bench(软件工程):得分 60.47,大幅超越 GPT-OSS-120B(41.9),展现强大的代码生成与调试能力。
- DeepResearch Bench:推动 NVIDIA AI-Q 研究智能体登顶排行榜,证明其在多步骤研究与复杂推理中的卓越表现。
- 长上下文能力:
- RULER 1M:在 100 万词元测试中得分 91.75,远超竞品 GPT-OSS-120B(22.30),在 256K/512K 长度下仍保持 95% 以上准确率。
- 推理速度:
- 在"8K 输入 +64K 输出”的高负载场景下,比 Qwen3.5-122B 快 7.5 倍,比 GPT-OSS-120B 快 2.2 倍。
应用场景:从代码开发到金融分析
Nemotron 3 Super 的设计初衷是处理多智能体系统中的复杂子任务:
- 软件开发智能体:可一次性加载整个代码库至上下文,实现端到端的代码生成、重构与 Debug,无需分块处理。
- 金融深度分析:轻松 ingest 数千页的财报与研报,在长对话中保持逻辑一致,无需重复推理背景信息。
- 自主安全编排:凭借高精度的工具调用能力,可靠地遍历庞大函数库,避免在网络安全等高风险场景中出现执行错误。
开放生态:权重、数据与配方全开源
英伟达此次采取了极为开放的策略,旨在加速社区创新:
- 开放权重:开发者可在 workstation、数据中心或云端自由部署与定制。
- 开放数据:发布超过 10 万亿词元 的合成训练数据集及训练后数据。
- 开放配方:公开 15 个强化学习环境与评估配方,研究人员可利用 NVIDIA NeMo 平台进行微调或构建衍生模型。
- 便捷部署:模型已打包为 NVIDIA NIM 微服务,支持从本地到云端的无缝部署。
Nemotron 3 Super 的发布,标志着大模型竞争进入了"效率为王"的新阶段。它不再单纯追求参数规模的堆砌,而是通过架构创新(Mamba+MoE+MTP)和量化技术(NVFP4),在智能体最关注的长上下文、低延迟、低成本三个维度上实现了全面突破。
对于正在构建下一代自主智能体应用的企业与开发者而言,Nemotron 3 Super 提供了一个既强大又经济的基础设施选择。随着 Blackwell 架构的普及,这款模型有望成为推动 AI 从“对话”走向“行动”的关键引擎。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











