在大语言模型(LLM)的实际应用中,推理速度是影响用户体验和部署成本的关键因素。尽管模型能力不断提升,但逐个生成 token 的方式带来了较高的延迟和计算开销。推测解码(Speculative Decoding)作为一种加速推理的技术,通过“草稿模型”预测多个未来 token 再由目标模型验证,能够在保证输出质量的前提下显著提升生成速度。
- Github :https://github.com/Tencent-BAC/FastMTP
- HuggingFace :https://huggingface.co/TencentBAC/FastMTP
- ModelScope:https://modelscope.cn/models/TencentBAC/FastMTP
然而,传统推测解码依赖小型草稿模型,受限于其容量与上下文建模能力,导致预测命中率不高,限制了实际加速效果。为解决这一问题,腾讯提出了一种更高效、更实用的改进方案FastMTP ——增强型多令牌预测(Enhanced Multi-Token Prediction)。
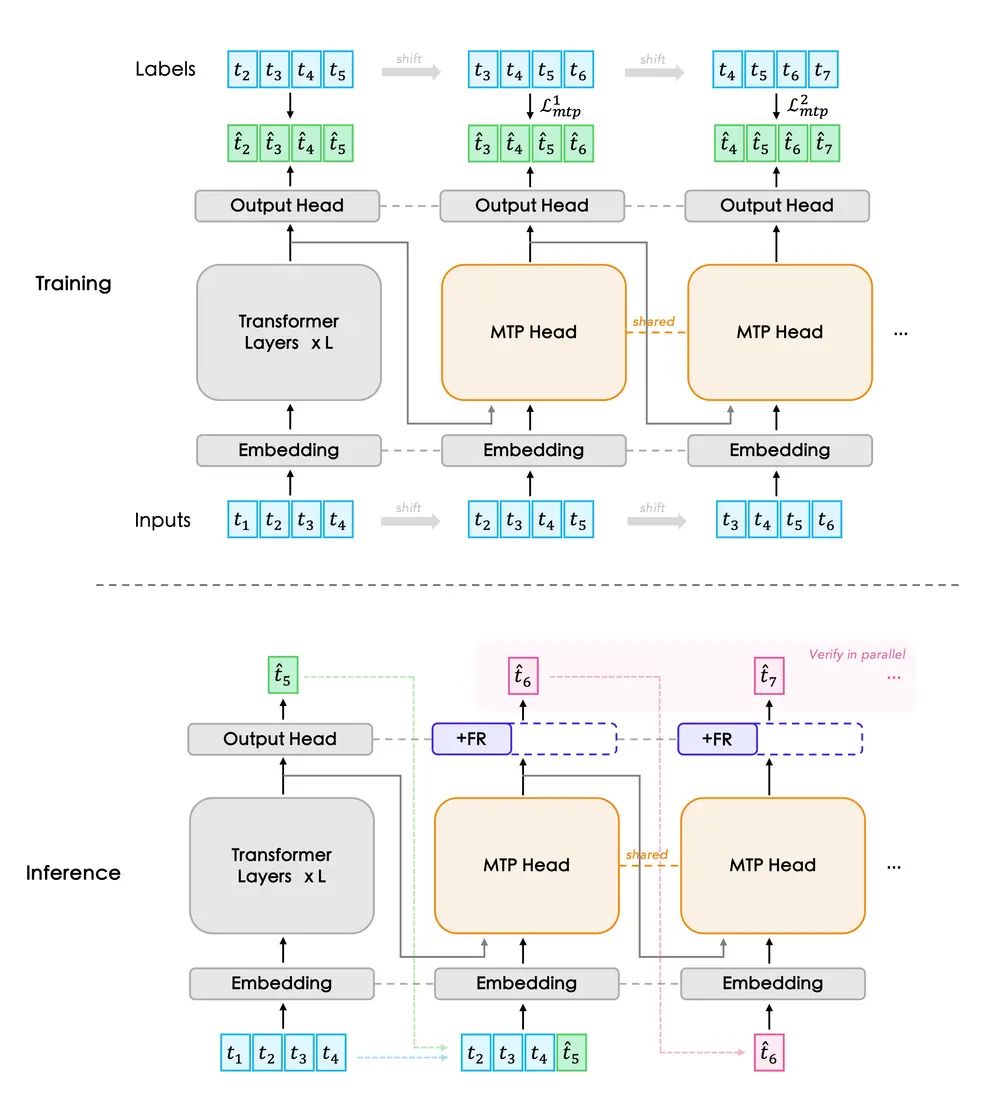
核心思路:用一个轻量头实现多步预测
FastMTP 并未引入额外的草稿模型,而是在原始模型上附加一个小型、可训练的 MTP 头(Multi-Token Prediction Head),用于并行预测后续多个 token。该 MTP 头通过对多个因果位置进行联合建模,并在训练过程中共享参数,使模型能够捕捉更长距离的依赖关系。
关键创新在于:
- 多步因果预测结构:MTP 头在多个时间步上递归预测未来 token,形成类似“草稿”的输出序列;
- 权重共享机制:减少参数量,提高训练效率,同时增强泛化能力;
- 端到端微调:仅对 MTP 头进行轻量级微调,不修改主干模型,保持原始输出分布不变。
这种方式避免了维护独立草稿模型的复杂性,也降低了部署门槛。
进一步优化:语言感知词汇压缩
为了降低 MTP 头在预测过程中的计算负担,FastMTP 引入了语言感知的词汇压缩策略。该方法根据子词频率和语义相关性,将原始词汇表映射到一个更紧凑的空间,在保留关键表达能力的同时,减少了预测阶段的分类维度,从而加快 MTP 头的前向计算速度。
这种压缩不是简单降维,而是结合语言统计特性设计,确保高频、有意义的 token 得到保留,兼顾效率与准确性。
实验表现:稳定加速,无损质量
在多个主流基准(如 GSM8K、XSUM、WikiText 等)上的测试表明:
- FastMTP 在不同规模模型(从 1B 到 7B 参数级别)上均实现了平均 2.03 倍的推理速度提升;
- 推测接受率相比基线方法提升显著,最高可达 85% 以上;
- 输出质量与原始模型一致,无可见退化;
- 训练成本低,通常只需数小时即可完成 MTP 头微调。
更重要的是,FastMTP 可无缝集成到现有的推理框架中(如 vLLM、HuggingFace Transformers),无需更改底层引擎或硬件配置,具备良好的工程实用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











