美团 LongCat 团队正式推出 LongCat-Flash-Thinking——一款专注于高复杂度任务推理的大型语言模型(LRM)。该模型在保持前代 LongCat-Flash-Chat 高效响应速度的基础上,显著增强了逻辑、数学、编程及智能体决策等领域的深度推理能力。
- GitHub:https://github.com/meituan-longcat/LongCat-Flash-Thinking
- 模型:https://huggingface.co/meituan-longcat/LongCat-Flash-Thinking
综合评估显示,LongCat-Flash-Thinking 在多个权威基准上达到当前全球开源模型中的领先水平,部分任务表现接近主流闭源模型。更重要的是,它成为国内首个同时支持“非形式化+形式化”推理与“工具调用+自主决策”的统一架构大模型。
核心能力概览
✅ 多领域推理全面领先
| 领域 | 基准测试 | 成绩 |
|---|---|---|
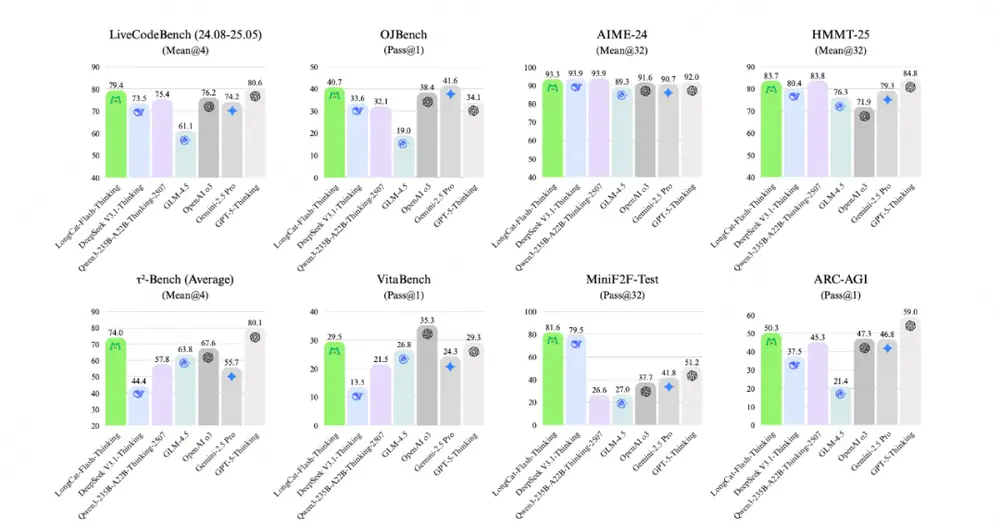
| 通用推理 | ARC-AGI | 50.3 分,超越 OpenAI o3、Gemini 2.5 Pro |
| 数学推理 | HMMT / AIME 相关基准 | 表现与 Qwen3-235B-A22B-Thinking 相当 |
| 编程能力 | LiveCodeBench | 79.4 分,开源 SOTA,接近 GPT-5 水平 |
| 智能体工具使用 | τ²-Bench | 74.0 分,刷新开源纪录 |
| 形式定理证明 | MiniF2F-test (pass@1) | 67.6 分,大幅领先现有模型 |
尤其在需要多步推导、结构化思维和外部工具协同的任务中,新模型展现出显著优势。
模型架构:高效 MoE + 动态计算
LongCat-Flash-Thinking 是一个参数总量达 5600 亿的混合专家(MoE)模型,采用动态路由机制:
- 激活参数范围:根据输入上下文,每次推理仅激活 186 亿至 313 亿参数,平均约 270 亿;
- 计算效率提升:相比全参模型,显著降低延迟与资源消耗,实现高性能与低开销的平衡。
该设计使其既能应对复杂任务,又适合部署于生产环境,延续了 Flash 系列“快而强”的定位。
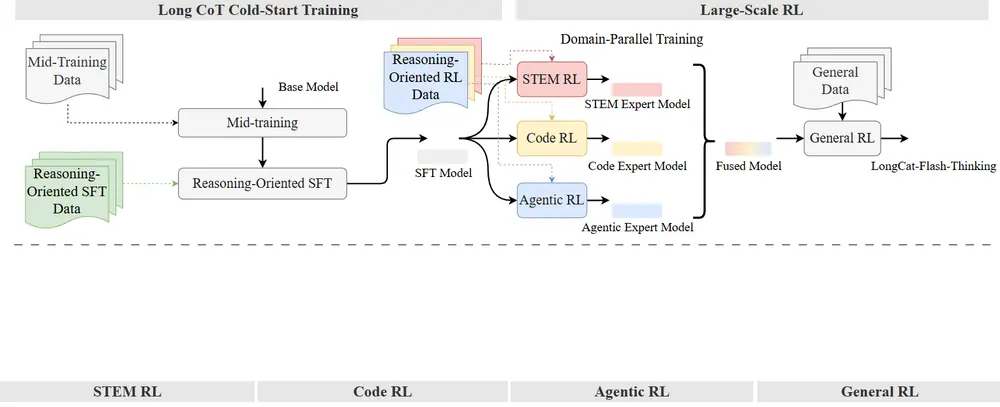
训练体系:两阶段强化学习框架
模型开发基于自研的 DORA(Dynamic Orchestration for Reinforcement Optimization)系统,采用两阶段训练流程,兼顾稳定性与泛化能力。
第一阶段:长链推理冷启动
- 使用课程学习策略,在中期训练中逐步增强模型内在推理能力;
- 在监督微调(SFT)阶段引入大量推理密集型数据(数学证明、代码生成、代理轨迹);
- 构建基础推理骨架,为后续强化学习打下基础。
第二阶段:大规模异步强化学习
- 基于 DORA 框架进行工业级异步训练,支持跨数千加速器并行;
- 改进 GRPO 算法,提升探索-利用平衡,缓解异步训练中的策略滞后问题;
- 引入领域并行训练方案,将 STEM、编码、智能体任务解耦优化,分别生成领域专家模型;
- 最终通过融合机制整合各领域专家,形成统一模型,并进一步开展通用 RL 微调,提升安全性与人类对齐程度。
这一方法有效解决了传统多任务强化学习中因梯度冲突导致的性能退化问题。
关键技术特性
领域并行强化学习
不同于常规多任务联合训练,LongCat-Flash-Thinking 将不同推理领域独立建模:
- 各领域单独迭代优化,避免相互干扰;
- 训练完成后通过加权融合生成最终模型;
- 实现接近帕累托最优的跨领域性能均衡。
此策略特别适用于数学、代码、工具调用等差异较大的任务类型。
自研 DORA 强化学习基础设施
DORA 是支撑整个训练过程的核心系统,具备三大能力:
- 弹性协同定位
动态调度 Actor 与 Critic 模型实例,最大化硬件利用率。 - 多版本异步流水线
支持多个旧策略模型并行采样,提升长尾样本覆盖。 - KV-Cache 高效复用
减少重复计算开销,提升序列处理效率,保障采样一致性。
该系统已在数万个加速器上验证其稳定性和可扩展性。
双向推理能力升级
1. 形式推理(Formal Reasoning)
模型支持从自然语言命题到形式化逻辑的转换,并能生成 Coq/F* 类风格的结构化证明。
关键技术:
- 构建专家迭代框架,用于合成高质量定理证明数据;
- 包含语句形式化、迭代证明生成、语法与一致性过滤;
- 显著提升在 MiniF2F 等形式化数学基准上的 pass@k 指标。
2. 代理推理(Agentic Reasoning)
模型可自主判断是否调用工具,并完成复杂任务编排。
实现路径:
- 提出双路径推理机制,识别需工具辅助的高价值查询;
- 在包含 MCP 服务器、模拟 API 的多功能环境中合成真实交互轨迹;
- 支持单轮与多轮工具调用,增强智能体行为稳健性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











