在持续三个月的优化后,阿里Qwen团队正式推出 Qwen3-235B-A22B-Thinking-2507 版本。该模型在逻辑推理、数学、科学、编程及学术任务上的表现显著提升,进一步巩固了其在开源思维模型中的领先地位。
- 模型:HuggingFace | ModelScope
- Demo:https://chat.qwen.ai
此次更新聚焦于“深度思考”能力的增强,特别适用于需要复杂推理和长链逻辑的高难度任务。
核心升级:更强的推理,更广的覆盖
与前代相比,Qwen3-235B-A22B-Thinking-2507 在多个关键维度实现突破:
- ✅ 推理能力跃升:在数学、科学、编程等专业领域,性能达到开源模型中的最先进水平。
- ✅ 通用能力提升:指令遵循、工具调用、文本生成及与人类偏好的对齐能力均有显著进步。
- ✅ 长上下文支持增强:原生支持 262,144 令牌的上下文长度,对长文档、复杂代码库的理解更加深入。
值得注意的是,此版本的“思考长度”有所增加,建议在处理高度复杂的推理任务时优先使用。
模型概览
| 项目 | 说明 |
|---|---|
| 模型类型 | 因果语言模型 |
| 训练阶段 | 预训练 + 后训练 |
| 总参数量 | 2350亿(235B) |
| 激活参数量 | 220亿(22B,MoE架构) |
| 非嵌入参数 | 2340亿(234B) |
| 层数 | 94 |
| 注意力头数(GQA) | Q: 64, KV: 4 |
| 专家数量 | 128(激活8个) |
| 上下文长度 | 262,144(原生支持) |
注意:该模型仅支持思考模式。默认聊天模板已自动包含
<think>标签,因此输出中仅出现</think>而无起始标签,属于正常行为。
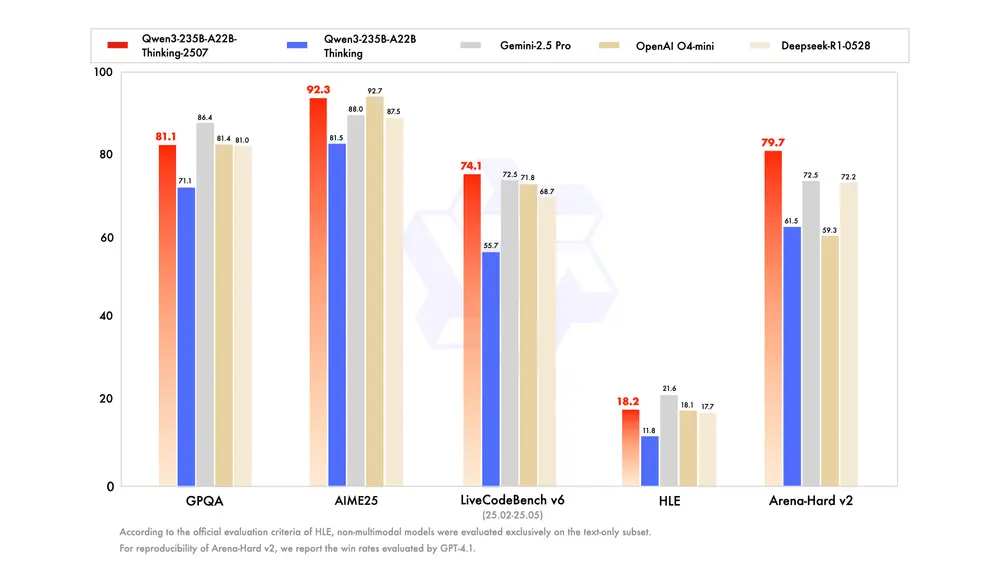
性能表现:多项任务超越主流模型
在多个权威基准测试中,Qwen3-235B-A22B-Thinking-2507 展现出强劲竞争力,尤其在推理与编码领域表现突出。
推理任务
| 基准 | Qwen3-235B-A22B-Thinking-2507 | Qwen3-235B-A22B |
|---|---|---|
| AIME25(数学竞赛) | 92.3 | 81.5 |
| HMMT25(数学竞赛) | 83.9 | 62.5 |
| LiveBench 20241125 | 78.4 | 77.1 |
| HLE(逻辑推理) | 18.2# | 11.8# |
# 为非多模态模型在文本子集上的评估结果。
编码能力
| 基准 | Qwen3-235B-A22B-Thinking-2507 | Qwen3-235B-A22B |
|---|---|---|
| LiveCodeBench v6 | 74.1 | 55.7 |
| CFEval | 2134 | 2056 |
| OJBench | 32.5 | 25.6 |
知识与对齐
| 基准 | Qwen3-235B-A22B-Thinking-2507 | Qwen3-235B-A22B |
|---|---|---|
| MMLU-Pro | 84.4 | 82.8 |
| GPQA(学术知识) | 81.1 | 71.1 |
| SuperGPQA | 64.9 | 60.7 |
| IFEval(指令遵循) | 87.8 | 83.4 |
| Arena-Hard v2 | 79.7 | 61.5 |
* OpenAI 模型部分结果基于高推理努力生成。
代理与多语言
| 基准 | Qwen3-235B-A22B-Thinking-2507 | Qwen3-235B-A22B |
|---|---|---|
| BFCL-v3(Agent任务) | 71.9 | 70.8 |
| TAU2-Retail | 71.9 | 40.4 |
| MultiIF(多语言推理) | 80.6 | 71.9 |
| PolyMATH(数学多语言) | 60.1 | 54.7 |
所有高挑战性任务(如数学、编程)使用 81,920 令牌输出长度;其余任务使用 32,768。
最佳实践建议
为充分发挥模型潜力,建议采用以下配置:
1. 采样参数
Temperature=0.6TopP=0.95TopK=20MinP=0- 可选:调整
presence_penalty(0-2)以减少重复,但过高可能导致语言混合。
2. 输出长度
- 一般任务:32,768 令牌
- 复杂任务(如数学竞赛、编程难题):81,920 令牌
3. 标准化输出格式
- 数学题:提示中加入
请逐步推理,并将最终答案放在 \boxed{} 中 - 选择题:使用 JSON 格式约束输出
"answer": "C"
4. 对话历史管理
在多轮对话中,历史记录应仅保留最终输出,无需包含 <think> 内容。此逻辑已在 Jinja2 聊天模板中实现。若自行实现,需确保遵循此规范。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











