
由上海交通大学、上海创智学院、香港理工大学、中国科学技术大学与GAIR联合开展的一项研究,最近提出了一个名为 LIMI 的新方法——全称为 Less is More for Intelligent Agency,即“智能体能力的关键在于精简而非海量数据”。
这项研究挑战了当前主流AI训练中“数据越多越好”的默认假设,提出:真正的机器自主性,并不来自数据规模的堆砌,而是源于对高质量行为样本的战略性筛选与学习。
这一发现,正在重新定义我们构建“能做事”的AI系统的方式。
从“会说”到“会做”:AI需要的是行动力
近年来,大模型在语言理解与生成方面取得了显著进展。但多数模型仍停留在“思考型AI”阶段——它们擅长回答问题、撰写文本,却难以独立完成复杂任务。
而现实应用更需要的是“工作型AI”:能够主动发现问题、制定计划、调用工具并执行操作的智能代理(Agent)。
LIMI的目标正是推动AI从“被动响应”走向“主动作为”。它关注的核心能力包括:
- 自主识别问题
- 多步推理与规划
- 工具调用与协调
- 环境交互与反馈调整
- 协作沟通与任务闭环
这些能力构成了所谓“智能体性”(Agency),也是未来AI能否真正融入生产流程的关键。
LIMI的核心思想:质量胜过数量
LIMI最引人注目的突破,在于其极高的数据效率。
研究人员仅使用 78个高质量训练样本,就在多个任务上实现了远超现有大型模型的表现。相比之下,许多同类系统依赖数千甚至上万条数据进行训练。
这背后的理念很明确:
培养智能体的能力,不应靠盲目扩大数据集,而应聚焦于获取那些真正体现“完整任务执行过程”的优质行为轨迹。
为此,LIMI建立了三个关键技术环节:
1. 用户查询合成:让训练场景更真实
传统方法常依赖人工编写或模拟任务指令,容易脱离实际。LIMI则通过两种方式获取真实用户需求:
- 分析人类与AI协作的真实对话记录
- 利用GitHub上的拉取请求(Pull Request)信息,自动提取开发任务描述
这些来源于实际工作流的查询,确保了训练任务的真实性与挑战性。
2. 系统化轨迹收集:记录完整的“行动链条”
LIMI不仅关注最终结果,更重视AI解决问题的全过程。每一条训练样本都包含:
- 模型的推理步骤
- 工具调用序列(如代码编辑器、数据库接口等)
- 环境反馈(如运行错误、执行结果)
- 最终任务完成状态
这种端到端的行为轨迹,为模型提供了可模仿的“专家示范”。
3. 数据效率原则:以少胜多的训练策略
基于上述高质量轨迹,LIMI采用了一种“小而精”的训练范式:
- 不追求数据总量,而是精心策划每个样本的内容
- 覆盖多样化的任务类型与失败恢复场景
- 强调跨工具协同与动态调整能力
这种方法使得模型能够在极小的数据规模下,掌握复杂的任务执行逻辑。
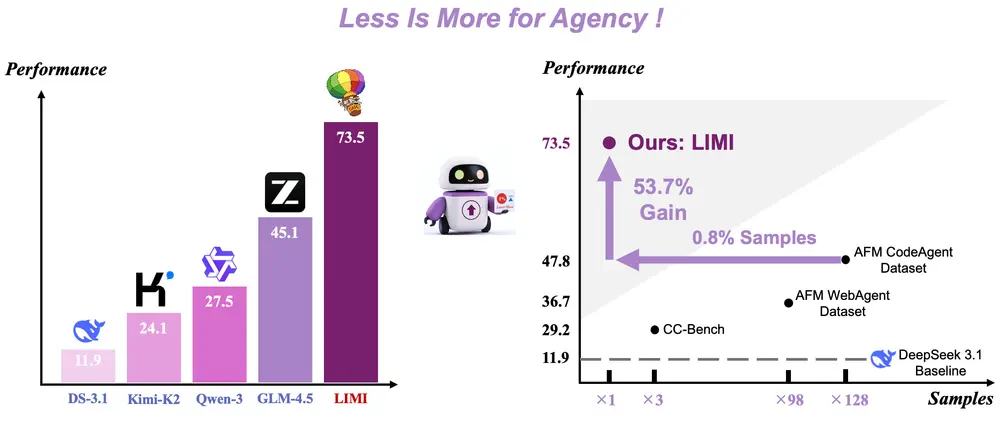
实验结果:用1/128的数据,实现53.7%的性能提升
在标准评测平台 AgencyBench 上,LIMI的表现令人瞩目:
| 模型 | 性能得分 |
|---|---|
| LIMI | 73.5% |
| GLM-4.5 | 45.1% |
| Kimi-K2-Instruct | 24.1% |
这意味着,LIMI在任务成功率上大幅领先当前主流模型。
更关键的是,在数据效率方面的对比:
- LIMI 使用:78个训练样本
- 对比模型使用:10,000个样本
尽管数据量仅为后者的 0.78%(约1/128),LIMI仍实现了 53.7%的相对性能提升。
此外,在泛化能力测试中,LIMI在多个未见任务上的平均表现为 57.2%,优于所有基线模型,显示出良好的迁移潜力。
应用前景:让AI真正进入工作流
LIMI的设计面向真实应用场景。例如:
- 软件开发:AI可主动检测代码缺陷,提出修复方案,并通过集成开发环境直接提交修改。
- 科研辅助:AI能设计实验流程、分析实验数据、撰写初步报告,协助研究人员加速探索。
- 运维自动化:面对系统异常,AI可定位问题根源、执行修复命令、验证修复效果,形成闭环处理。
这些不再是“如果我能……”的设想,而是LIMI所展示出的可行路径。
不是不要数据,而是要更有价值的数据
LIMI的意义,不只是一个高性能模型的诞生,更是对当前AI研发范式的反思。
我们过去习惯于用更大的数据、更强的算力去逼近智能。但LIMI证明:
当我们真正理解“什么是有效的智能行为”,并据此构造高质量训练样本时,可以用极少的资源,培育出更具行动力的AI。
这不仅是效率的胜利,也是一种更可持续的发展方向。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











