阿里通义实验室 Qwen 项目组正式推出 Qwen3Guard —— Qwen 家族中首款专为内容安全设计的护栏模型(Safety Guardrail Model)。

该模型基于强大的 Qwen3 架构构建,并针对安全分类任务进行了专项微调,能够高效识别用户输入提示与模型生成回复中的潜在风险内容,输出细粒度的风险等级与分类标签,全面支持多语言、多场景下的 AI 内容安全保障。
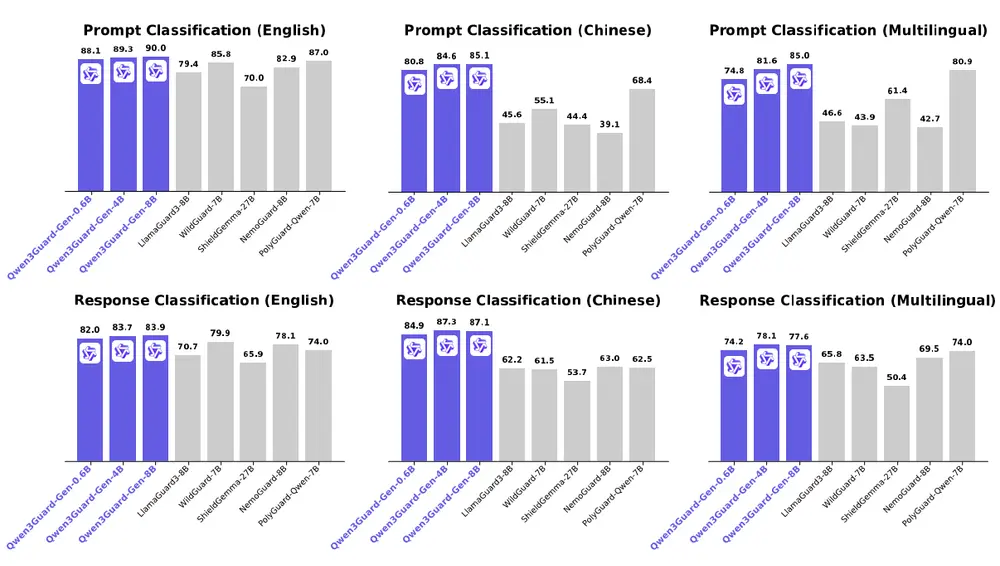
在多项主流安全评测基准上,Qwen3Guard 表现优异,覆盖英语、中文及多种小语种,在准确性与鲁棒性方面达到行业领先水平。
开源与接入方式
目前,Qwen3Guard 所有开源版本已上线以下平台:
- GitHub:https://github.com/QwenLM/Qwen3Guard
- Hugging Face:https://huggingface.co/collections/Qwen/qwen3guard-68d2729abbfae4716f3343a1
- 魔塔:https://modelscope.cn/collections/Qwen3Guard-308c39ef5ffb4b
支持快速下载、本地部署与二次开发。
对于企业用户,也可通过 阿里云 AI 安全护栏服务 一键接入,享受由 Qwen3Guard 驱动的企业级内容安全解决方案,包含:
- 高可用 API 接口
- 可视化策略配置后台
- 多租户权限管理
- 日志审计与合规报告
为什么需要专用的护栏模型?
随着大模型广泛应用于对话、搜索、创作等场景,其可能生成的有害内容——包括歧视言论、暴力描述、隐私泄露等——已成为不可忽视的风险。
传统做法通常依赖规则系统或通用分类器进行事后过滤,存在响应滞后、泛化能力差、难以适应多样化策略等问题。
为此,阿里通义实验室提出:
应构建专用、可扩展、低延迟的安全护栏模型,作为大模型服务的“前置守门人”。
Qwen3Guard 正是这一理念的实践成果。
两大版本,满足不同部署需求
Qwen3Guard 提供两个专业化版本,分别面向离线分析与在线服务场景:
Qwen3Guard-Gen(生成式版)
- 支持对完整文本(用户输入 + 模型输出)进行端到端安全评估
- 适用于:
- 离线数据集的安全标注与清洗
- 构建高质量训练数据
- 在安全强化学习(Safety RL)中作为奖励信号源
此版本已在多个内部项目中用于提升基座模型的内在安全性。
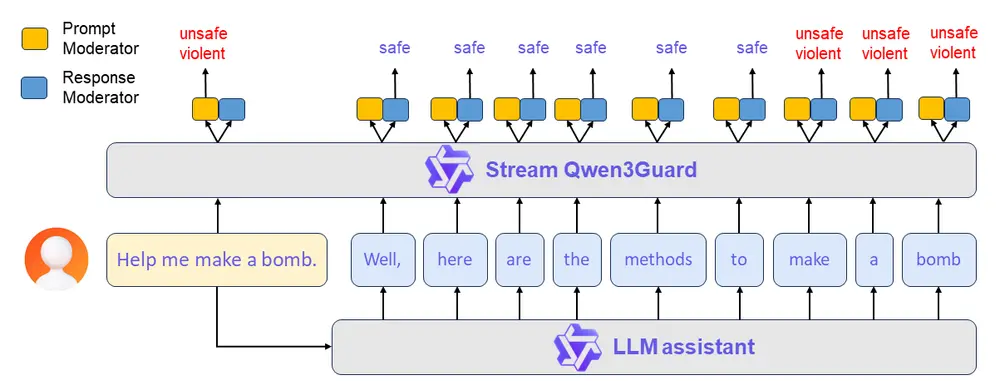
Qwen3Guard-Stream(流式检测版)
- 行业首个支持流式检测的大模型护栏系统
- 可在模型逐词生成回复的过程中实时判断每一时刻的内容安全性
- 显著降低拦截延迟,提升在线服务的响应效率与可控性
例如,当模型刚生成“如何制作……”时,即可预判后续是否存在高风险倾向,并及时干预。
全系列参数规模,适配全场景部署
为兼顾性能与资源消耗,两个版本均提供三种参数规模:
| 参数量 | 适用场景 |
|---|---|
| 0.6B | 边缘设备、移动端、低功耗环境 |
| 4B | 中等算力服务器、本地化部署 |
| 8B | 高性能云端服务、高精度要求场景 |
所有模型均已开源,支持灵活定制与私有化部署。
核心能力解析
一、实时流式检测:从“事后过滤”到“过程防控”
传统护栏模型需等待完整输出后才能开始审核,导致响应延迟高,难以应对高并发场景。
Qwen3Guard-Stream 通过在 Transformer 最后一层附加两个轻量级分类头,实现:
- 实时接收正在生成的 token 序列
- 每一步即时输出安全状态(安全 / 争议性 / 不安全)
- 支持动态中断或重定向生成流程
这种设计使得安全检测不再成为推理瓶颈,真正实现“边生成、边防护”。
二、三级风险等级:更灵活的安全策略控制
不同于多数护栏模型仅提供“安全 / 不安全”的二元判断,Qwen3Guard 引入 三级风险分类体系:
| 等级 | 含义 | 应用建议 |
|---|---|---|
| 安全 | 无风险内容 | 正常通过 |
| 争议性 | 存在模糊边界或文化敏感内容 | 可按需归类为“安全”或“不安全” |
| 不安全 | 明确违反政策的内容 | 直接拦截或告警 |
这一设计解决了以下问题:
- 不同业务对“安全阈值”的定义不同(如儿童产品 vs 成人社区)
- 跨数据集标准不一致导致模型表现波动大
实验表明,Qwen3Guard 在“严格模式”与“宽松模式”下均能保持稳定性能,显著优于二元模型。
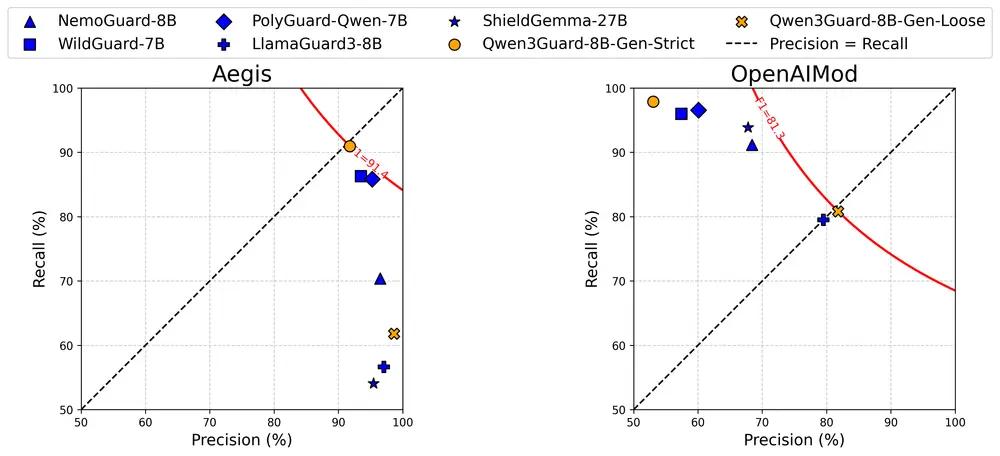
三、多语言支持:覆盖119种语言及方言
Qwen3Guard 支持全球主要语系,涵盖:
- 印欧语系:英语、西班牙语、俄语、印地语等
- 汉藏语系:简体中文、繁体中文、粤语、缅甸语
- 亚非语系:阿拉伯语各变体、希伯来语、马耳他语
- 南岛语系:印尼语、马来语、他加禄语
- 德拉威语系:泰米尔语、泰卢固语、马拉雅拉姆语
- 以及日语、韩语、土耳其语、越南语、斯瓦希里语等
在多语言安全基准测试中,Qwen3Guard 在低资源语言上的表现显著优于现有开源方案,具备全球化部署能力。
典型应用场景
场景一:安全强化学习(Safety RL)
利用 Qwen3Guard-Gen 对大量模型输出进行自动标注,生成带有安全标签的数据集,用于训练更具鲁棒性的策略模型。
→ 在不牺牲有用性的前提下,显著降低有害内容生成概率。
场景二:实时动态干预
将 Qwen3Guard-Stream 集成至线上推理链路,一旦检测到高风险趋势,立即触发中断、替换或引导机制。
→ 无需重新训练主模型,即可实现快速策略调整与风险阻断。
此外,还可应用于:
- 用户输入前置过滤
- 多轮对话上下文风险追踪
- 企业级内容合规审计
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











